深圳住房和建设局网站预约放号做一个商务平台网站的费用
概述
1. 什么是 Docker?
Docker 是一个应用容器平台,管理项目中用到的所有环境(MySQL、Redis…)
2. Docker 和虚拟机的区别
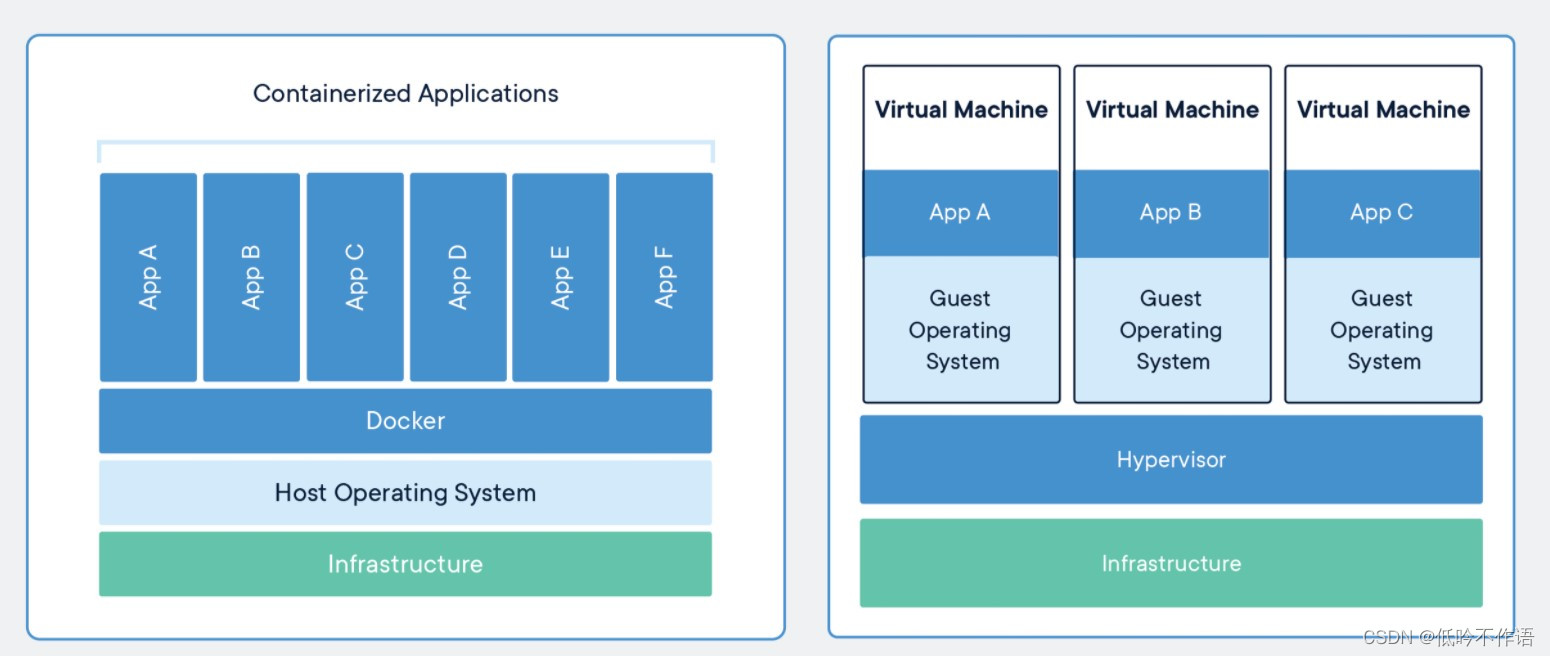
虚拟机是携带操作系统的,本身很小的应用程序因为携带了操作系统而变得十分笨重,Docker 不携带操作系统,所以 Docker 的应用非常轻巧
在调用宿主机资源时,虚拟机利用 Hypervisor 去虚拟化内存,整个调用过程是 虚拟内存 - 虚拟物理内存 - 真实物理内存,但是 Docker 利用 Docker Engine 去调用宿主机资源,这个过程是 虚拟内存 - 真实物理内存
3. Docker 核心架构
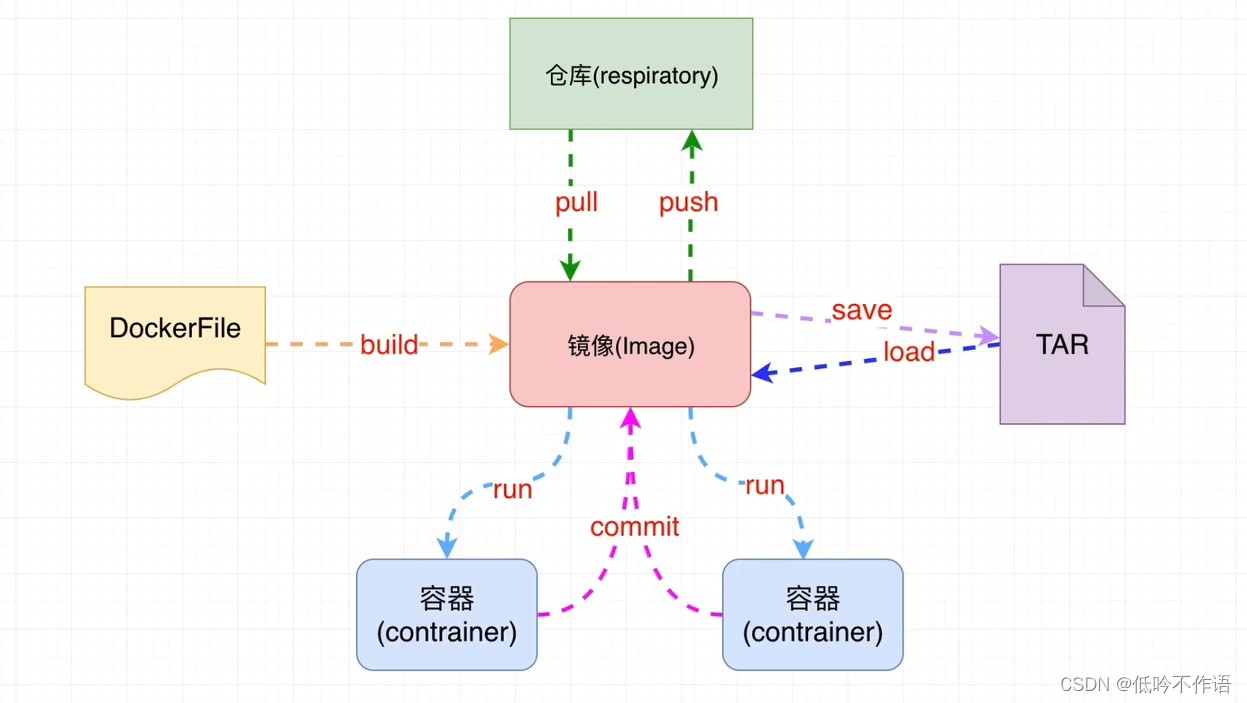
- 镜像:一个镜像代表一个应用环境,它是一个只读的文件,如 MySQL 镜像,Tomcat 镜像,Nginx 镜像等
- 容器:镜像每次运行之后就会产生一个容器,就是正在运行的镜像,特点是可读可写
- 仓库:用来存放镜像的位置,类似于 maven 仓库,也是镜像上传和下载的位置
- dockerFile:docker 生成镜像配置文件,用来书写自定义镜像的配置
- tar:一个对镜像打包的文件,日后可以还原成镜像
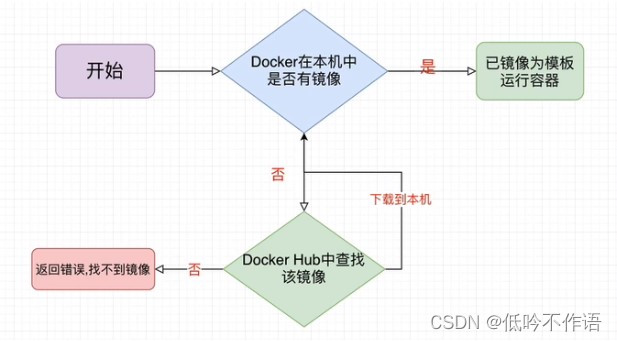
4. Docker 运行流程
安装 Docker
以 Ubuntu18.04.4 为例
更新 ubuntu 的 apt 源索引
sudo apt-get update
安装包允许 apt 通过 HTTPS 使用仓库
sudo apt-get install \apt-transport-https \ca-certificates \curl \software-properties-common
添加 Docker 官方 GPG key
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
设置 Docker 稳定版仓库
sudo add-apt-repository \"deb [arch=amd64] https://download.docker.com/linux/ubuntu \$(lsb_release -cs) \stable"
添加仓库后,更新 apt 源索引
sudo apt-get update
安装最新版 Docker CE(社区版)
sudo apt-get install docker-ce
检查 Docker CE 是否安装正确
sudo docker run hello-world
启动 docker
sudo service docker start
停止 docker
sudo service docker stop
重启 docker
sudo service docker restart
Docker 配置阿里云镜像加速服务,访问阿里云登录自己的账号查看 docker 镜像加速服务
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://e9rzpyni.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
sudo docker info # 验证 docker 的镜像加速是否生效
Docker 镜像命令
# 辅助命令
docker version # 查看 docker 命令
docker info # 查看更详细的信息
docker --help # 帮助命令
# images 镜像命令
docker images # 查看本地所有镜像
docker images -a # 列出所有镜像(包含中间映像层)
docker images -q # 只显示镜像id
# 搜索镜像
docker search [镜像名]
docker search -s [镜像名] # 列出收藏数不少于指定值的镜像
docker search --no-trunc [镜像名] # 显示完整的镜像信息
# 拉取镜像
docker pull [镜像名]
# 删除镜像
docker rmi [镜像名]
docker rmi -f [镜像名] # 强制删除
# 构建镜像
docker build -t [镜像名] [Dockerfile所在目录]
docker build -t [镜像名] [Dockerfile所在目录] --no-cache # 禁用缓存
Docker 容器命令
## 运行容器
# --name # 为容器起一个名字
# -p # 映射端口号:原始端口号,指定端口号启动
# -d # 启动守护式容器
# -rm # 用完即删
docker run [镜像名]
## 查看运行的容器
# -a # 正在运行的和历史运行过的容器
# -q # 静默模式,只显示容器编号
docker ps # 列出所有正在运行的容器
## 停止|关闭|重启容器
docker start 容器名字或容器id # 开启容器
docker restart 容器名或容器id # 重启容器
docker stop 容器名或容器id # 正常停止容器运行
docker kill 容器名或容器id # 立即停止容器运行
## 删除容器
docker rm [容器id]
docker rm -f [容器id] # 强制删除
docker rm -f $(docker ps -qa) # 全部容器删除
## 查看容器内的进程
docker top [容器名或容器id] # 查看容器内的进程
## 查看运行容器内部的细节
docker inspect [容器id] # 查看容器内部细节
## 查看容器的运行日志
# -t # 加入时间戳
# -f # 跟随最新的日志打印
# -tail [数字] # 显示最后多少条
docker logs [OPTIONS] [容器id或容器名] # 查看容器日志
## 容器内数据交互
# 进入容器内部
# -i # 以交互模式运行容器,通常与 -t 一起使用
# -t # 分配一个伪终端,命令后要跟一个 shell 窗口,如 /bin/bash
docker exec [options] [容器id]
# 退出容器
exit
## 将容器打包为新的镜像
docker commit -a="[作者]" -m="[描述信息]" [容器id] [目标镜像名称]:TAG
## 从容器中复制文件到宿主机目录中
docker cp 容器id:容器内资源路径 宿主机目录路径
## 设置容器和宿主机共享目录
# 宿主机必须是绝对路径,宿主机目录会覆盖容器内目录内容
docker run -it -v /[宿主机路径]:/[容器内的路径]:镜像名
# 检查 json 字符串有没有以下内容,如果有则证明卷挂载成功
# "Mounts":[
# {
# "Type":"bind",
# "Source":"/hostDataValueme",
# "Destination":"/containerDataValueme",
# "Mode":"",
# "RW":true,
# "Propagation":"rprivate"
# }
# ]
docker inspect [容器id]
## 打包镜像
docker save [镜像名] -o [名称].tar
## 载入镜像
docker load -i [名称].tar
Docker 安装 MySQL
以 Ubuntu18.04.4 为例
拉取 mysql 镜像到本地
sudo docker pull mysql:tag # tag 不加默认最新版本
运行 mysql 服务
# 没有暴露外部端口,外部不能连接
docker run --name [自定义容器名称] -e MYSQL_ROOT_PASSWORD=[设置 root 密码] -d mysql:tag
# 暴露外部端口
docker run --name [自定义容器名称] -e MYSQL_ROOT_PASSWORD=[设置 root 密码] -p 3306:3306 -d mysql:tag
进入 mysql 容器
sudo docker exec -it [容器名称]|[容器id] bash
外部查看 mysql 日志
sudo docker logs [容器名称]|[容器id]
使用自定义配置参数
docker run --name [自定义容器名称] -v [宿主机配置文件目录]:[容器中配置文件目录] -e MYSQL_ROOT_PASSWORD=[设置 root 密码] -p 3306:3306 -d mysql:tag
将容器数据位置与宿主机位置挂载保证数据安全
docker run --name [自定义容器名称] -v [宿主机配置文件目录]:[容器中配置文件目录] -v [宿主机数据文件目录]:[容器中数据文件目录] -e MYSQL_ROOT_PASSWORD=[设置 root 密码] -p 3306:3306 -d mysql:tag
将 mysql 数据库备份为 sql 文件
# 导出全部数据
sudo docker exec mysql sh -c 'exec mysqldump --all-databases -uroot -p"$MYSQL_ROOT_PASSWORD"' > /root/all-databases.sql
# 导出指定库数据
sudo docker exec mysql sh -c 'exec mysqldump --databases [库表] -uroot -p"$MYSQL_ROOT_PASSWORD"' > /root/all-databases.sql
# 导出指定库,但不要数据
sudo docker exec mysql sh -c 'exec mysqldump --no-data --databases [库表] -uroot -p"$MYSQL_ROOT_PASSWORD"' > /root/all-databases.sql
执行 sql 文件到 mysql
sudo docker exec -i mysql sh -c 'exec mysql -uroot -p"$MYSQL_ROOT_PASSWORD"' < /root/xxx.sql
Docker 安装 Redis
以 Ubuntu18.04.4 为例
在 docker hub 搜索 redis 镜像
sudo docker search redis
拉取 redis 镜像到本地
sudo docker pull redis
运行 redis 服务
# 没有暴露外部端口,外部不能连接
sudo docker run --name [自定义容器名称] -d redis:tag
# 暴露外部端口
sudo docker run --name [自定义容器名称] -p 6379:6379 -d redis:tag
外部查看 redis 日志
sudo docker logs -t -f [容器名称]|[容器id]
进入容器内部查看
sudo docker exec -it [容器名称]|[容器id] bash
加载外部自定义配置启动 redis 容器,默认情况下 redis 官方镜像中没有 redis.conf 配置文件,需要去官网下载指定版本的配置文件
sudo docker run --name [自定义容器名称] -v [宿主机配置文件路径]:/usr/local/etc/redis/redis.conf -p 6379:6379 -d redis:tag redis-server /usr/local/etc/redis/redis.conf
将数据目录挂载到本地保证数据安全
sudo docker run --name [自定义容器名称] -v [宿主机数据目录]:/data -v [宿主机配置文件路径]:/usr/local/etc/redis/redis.conf -p 6379:6379 -d redis:tag redis-server /usr/local/etc/redis/redis.conf
Docker 安装 Nginx 服务器
以 Ubuntu18.04.4 为例
在 docker hub 搜索 Nginx 镜像
sudo docker search nginx
拉取 nginx 镜像到本地
sudo docker pull nginx
运行 nginx 服务
# 没有暴露外部端口,外部不能连接
sudo docker run --name [自定义容器名称] -d nginx:tag
# 暴露外部端口
sudo docker run --name [自定义容器名称] -p 80:80 -d redis:tag
进入容器内部
sudo docker exec -it [容器名称]|[容器id] /bin/bash
# 查找目录
whereis nginx
# 配置文件
/etc/nginx/nginx.conf
从容器复制配置文件到主机
dokcer cp [容器名称]|[容器id]:/etc/nginx/nginx.conf [宿主机目录]
挂载 nginx 配置以及 html 到宿主机外部
sudo docker run --name [自定义容器名称] -v [宿主机配置文件路径]:/etc/nginx/nginx.conf -v [宿主机 html 目录]:/usr/share/nginx/html -p 80:80 -d nginx
Docker 安装 Tomcat 服务器
以 Ubuntu18.04.4 为例
在 docker hub 搜索 tomcat
sudo docker search tomcat
下载 Tomcat 镜像
sudo docker pull tomcat
运行 tomcat 镜像
sudo dokcer run -p 8080:8080 -d --name [自定义容器名称] tomcat
进入容器内部
sudo docker exec -it [容器名称]|[容器id] /bin/bash
将 webapps 目录挂载到外部
sudo docker -p 8080:8080 -v [宿主机webapps目录]:/usr/local/tomcat/webapps -d --name [自定义容器名称] tomcat
Docker 安装 MongoDB 数据库
以 Ubuntu18.04.4 为例
在 docker hub 搜索 mongo
sudo docker search mongo # 无须权限
运行 mongoDB
sudo docker run -d -p 27107:27107 --name [自定义容器名称] mongo
查看 mongo 的运行日志
sudo docker logs -f [容器名称]
进入容器内部
sudo docker exec -it [容器名称]|[容器id] /bin/bash
运行具有权限的容器
sudo docker run --name [容器名称] -p 27017:27017 -d mongo --auth
进入容器配置用户名和密码
# 进入 mongo 客户端
mongo
# 选择 admin 库
use admin
# 创建用户,此用户创建成功,则后续操作都需要用户认证
db.createUser({user:"root",pwd:"root",roles:[{role:'root',db:'admin'}]})
# 退出
exit
将 mongoDB 中数据目录映射到宿主机中
sudo docker run -d -p 27017:27017 [宿主机数据目录]:/data/db --name [自定义容器名称] mongo
Docker 安装 Elasticsearch 以及 Kibana 服务
预先配置
# 修改配置 sysctl.conf
sudo vim /etc/sysctl.conf
# 加入如下配置
vm.max_map_count=262144
# 启用配置
sysctl -p
docker hub 拉取镜像
sudo docker pull elasticsearch
运行 docker 镜像
sudo docker run -d -p 9200:9200 -p 9300:9300 --name [自定义容器名称] elasticsearch
复制容器中 data 目录到宿主机
sudo docker cp [容器id]:/usr/share/share/elasticsearch/data [宿主机目录]
运行 es 容器,指定 jvm 内存大小并指定 ik 分词器的位置
sudo docker run -d --name [自定义容器名称] -p 9200:9200 -p 9300:9300 -e ES_JAVA_OPTS="-Xms128m -Xmx128m" -v [宿主机插件目录]:/usr/share/elasticsearch/plugins -v [宿主机data目录]:/usr/share/elasticsearch/data elasticsearch:tag
拉取 kibana 镜像
sudo docker pull kibana
启动 kibana 容器
sudo docker run -d --name [自定义容器名称] -e ELASTICSEARCH_URL=[elasticsearch服务url] -p 5601:5601 kibana
Dockerfile
1. 概述
Dockerfile 可以认为是 Docker 镜像的描述文件,是由一系列命令和参数构成的脚本,主要作用是用来构建 docker 镜像
2. Dockerfile 解析过程
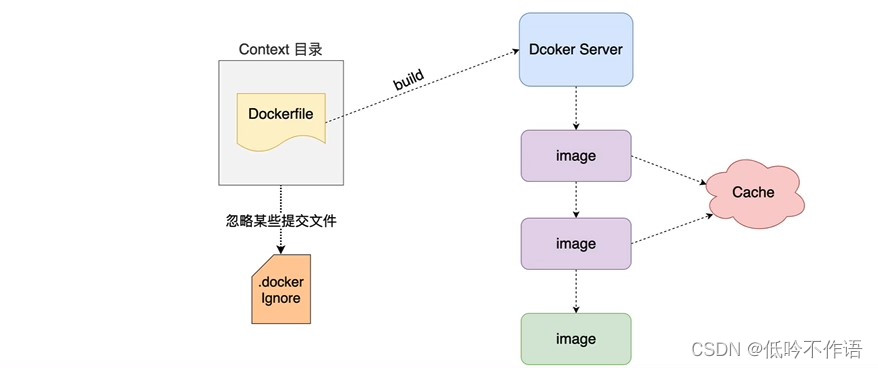
3. Dockerfile 的保留命令
## FROM:当前镜像基于哪个镜像构建,构建时会自动拉取 base 镜像(第一个指令必须是 FROM)
FROM [镜像]
FROM [镜像]:tag
FROM [镜像]:[@<digest>] # 使用摘要
## MAINTAINER:镜像维护者的姓名和邮箱地址
MAINTAINER [作者信息]
## RUN:构建镜像时需要运行的指令,并提交结果,生成的提交映像将用于 Dockerfile 的下一步
RUN [shell命令格式]
RUN yum install vim
RUN [json格式]
RUN ["yum","install","vim"]
## EXPOSE:构建的镜像创建容器时对外暴露的端口号
EXPOSE 80/tcp # 没有显示指定默认是 tcp
EXPOSE 80/udp
## WORKDIR:指定在创建容器后,终端默认登录进来的工作目录,一个落脚点
WORKDIR [路径]
## ENV:用来在构建镜像过程中设置环境变量
ENV [键] [值]
ENV [键]=[值]
## AOD:将宿主机下的文件或目录拷贝到镜像且 ADD 命令会自动处理 URL 和解压 tar 包
ADD [要拷贝的文件/目录] [镜像中的目录] # 第一个参数可以使用通配符
ADD [url] [镜像中的目录]
## COPY:类似 ADD,拷贝文件和目录到镜像,但不能处理 URL 和解压 tar 包
## VOLUME:容器运行时可以挂载到宿主机的目录
VOLUME [容器中可以挂载到宿主机的目录]
## CMD:构建的镜像启动容器时要运行的命令,DockerFile 中可以有多个 CMD 指令,但最后只有一个生效,CMD 会被 docker run 之后的参数替换,格式与 RUN 一致
## ENTRYPOINT:和 CMD 一样,指定容器时执行命令,格式与 RUN 一致,如果要覆盖,必须使用 --entrypoint="[新命令]" [镜像名] [其他参数]