专业企业网站建设2022好项目免加盟费
在我们日常遇到的很多第三方软件中,有部分软件针对开发人员,并不提供预编译成果物,而是需要开发人员自行编译,此类问题有时候不是问题(编译步骤的doc详细且清晰时),但有时候又很棘手(编译步骤的doc少,对应的configure脚本或者CMakeLists脚本又很长且缺少help选项)。本文就针对一款开发调试软件,但是需要依赖于QT5库进行编译生成,话不多说,开始进行编译QT5。
编译准备
在以前,QT5是往往是直接下载安装的,相信很多Windows端的开发人员都操作过。从官网下载QT时需要登录才能提供下载资源,这一步就很不友好。我们直接采用从镜像站去下载的方式,原来QT的版本仓库是有很多的预构建包供下载的,但是现在已经都被删除了,甚至都见不到5.9版本的踪影,QT最新是推荐QT6,但是由于依赖QT5的问题,所以我们采用最新的5.15.10的源码进行库编译。
编译QT5
QT5的编译步骤其实在QT的相关document中有介绍,其中就有在Linux上进行编译的编译指南。其中主要介绍的是依赖X11窗口系统进行编译。Ubuntu22.04使用的窗口系统是wayland,并非X11,所以这次编译的结果是否可以100%成功具有未知性。
先通过使用configure --help来查看编译脚本的一些可配置信息,可以看到大量的介绍信息,我们采用如下参数来进行预构建配置:
./configure \
-verbose \
-recheck-all \
-opensource \
-confirm-license \
-release \
-shared \
-c++std c++17 \
-make libs \
-nomake tests \
-nomake examples \
-skip qtandroidextras \
-skip qtmacextras \
-skip qtwinextras
# 省略多个-skip, 可根据情况自己选择跳过哪些模块的编译在执行配置的过程中,可以看到一些第三方库的可选安装信息,可根据自己的需求去进行安装,例如安装png库apt install libpng。 这边如果没有报错,那么就可以进行下一步编译了,执行make开始编译。
assimp库找不到的问题
编译报错Project ERROR: Library 'assimp' is not defined,在出现这个问题之前,我们已经通过apt install libassimp-dev安装了assimp库了,库版本是5.2.2。 为了解决这个问题,在网上搜索了一下此问题,并没有很好的解决方案。于是查找QT的相关网页与问题反馈,最后找到了一丝线索:

顺着线索,找到此问题的解决方案的页面,QT团队给出的解释居然是因为使用高于5.0.0版本的assimp库的开发者不多,所以他们并没有想修复此问题,于是这个问题在历代QT5中均会存在。解决方案也很简单,找到图中所框的脚本代码位置,改为框中的内容即可。
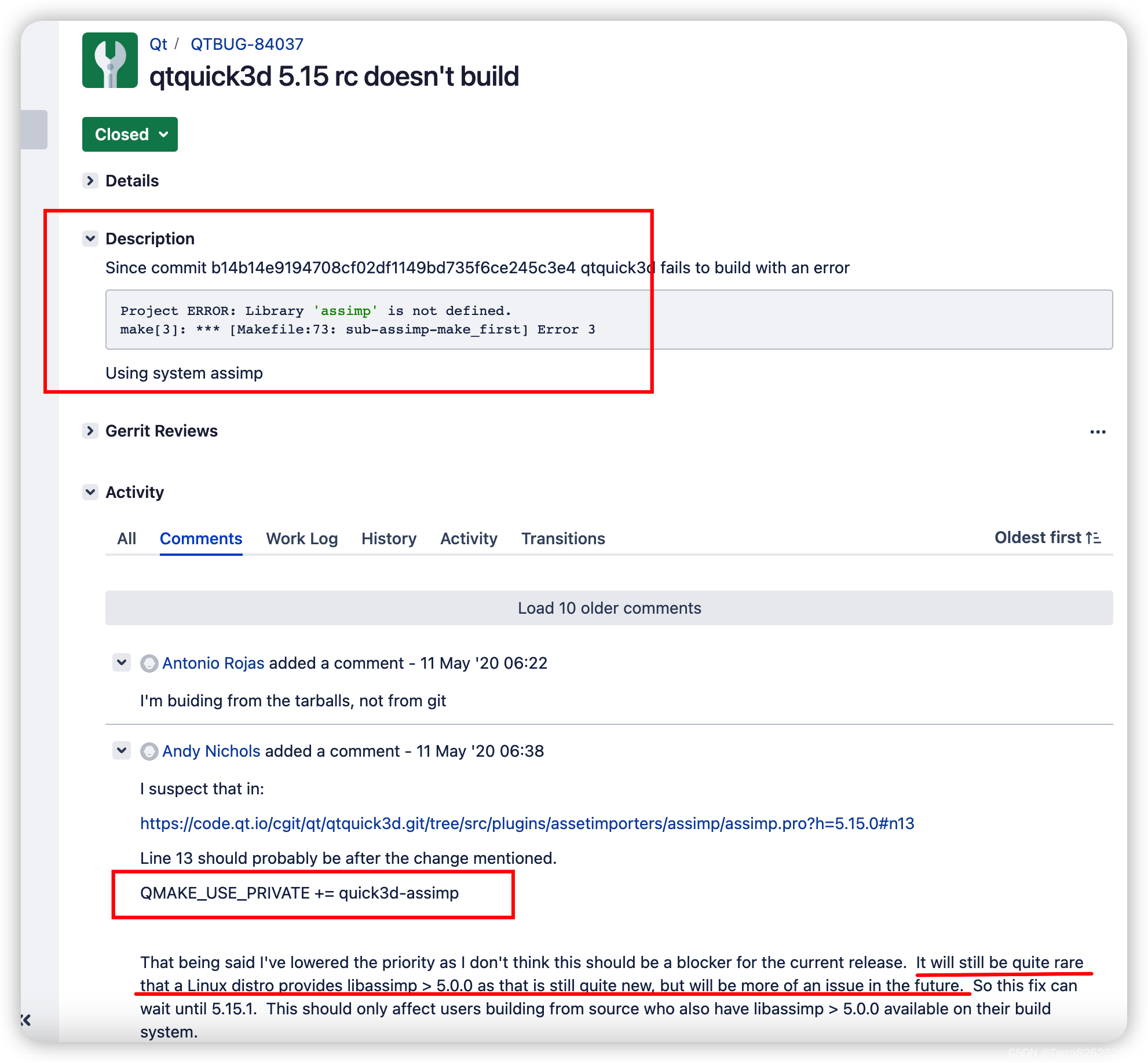
在经过这个修改后,发现确实生效,因为再次重新编译时遇到了不一样的错误。
pbrmaterial.h缺少宏定义的问题
这次的编译错误提示是找不到assimp相关的一个头文件中的一个宏定义。
经过确认,该问题在assimp 5.2.3中就得到了修复,而目前Ubuntu的apt仓库中拉取到的最新的为5.2.2,因此还是存在这个问题。所以解决方案就是:完整移除apt下载的assimp库,下载assimp最新源码并编译安装。这个库的编译与安装就不多展开了,比较简单也比较顺利。
等最新版本的assimp安装好后,再次进行QT5的编译即可。