网站开发转包协议wordpress页面内菜单
1.软件下载
官网下载地址
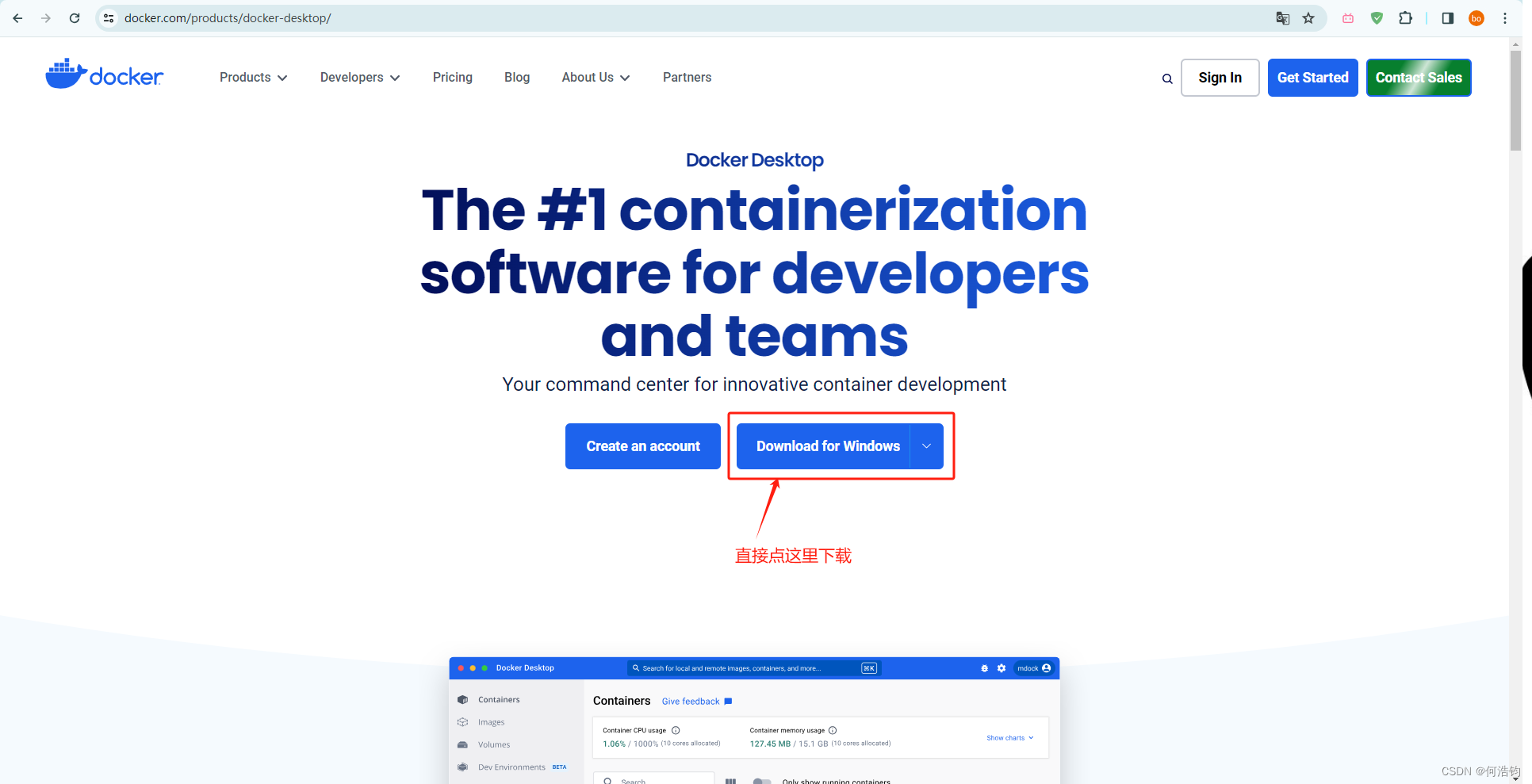
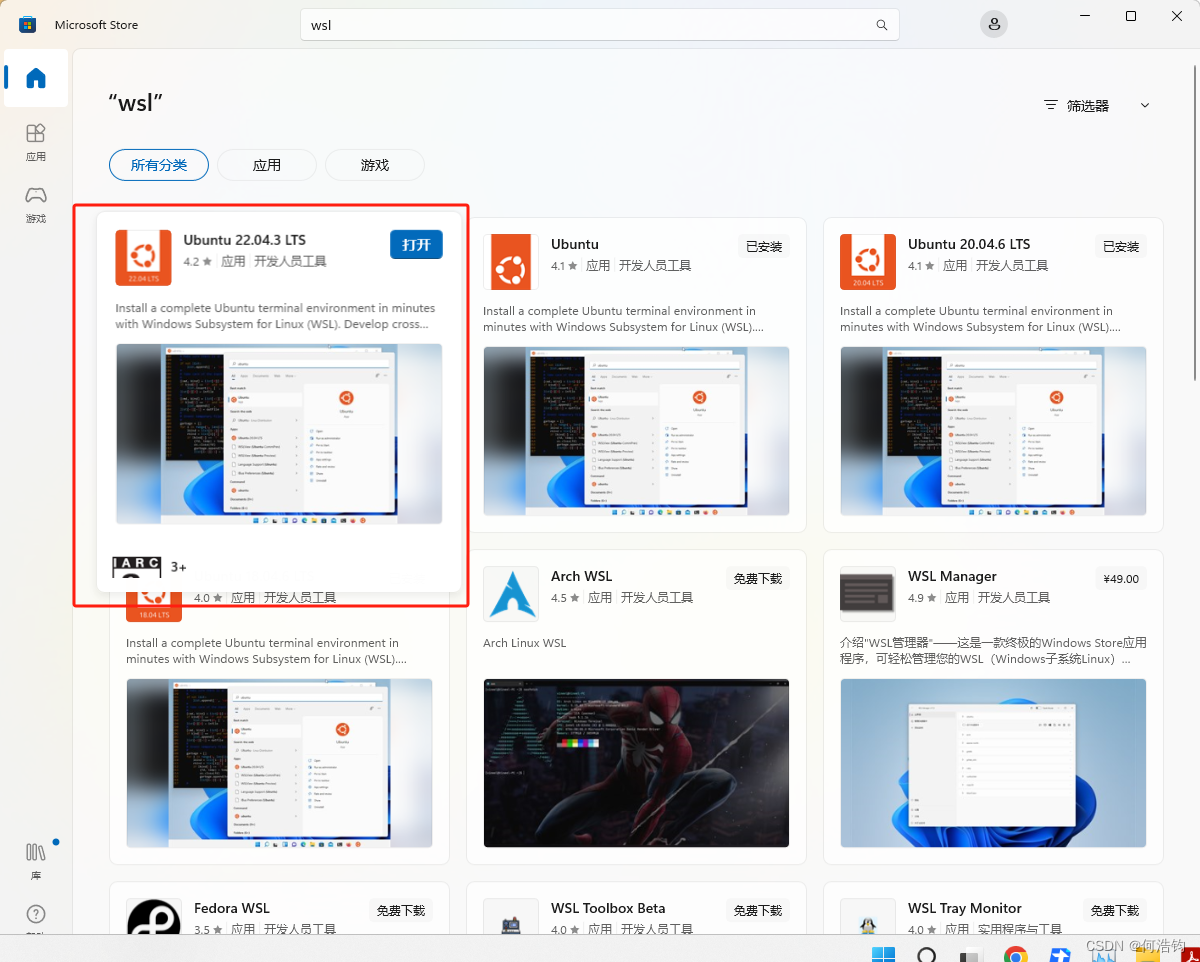
下载安装之后,再去微软商店下载wsl软件,可以直接用,或者也可以使用命令行拉取(下面会讲)
2.在docker里面创建容器的两种方法
2.1.命令行创建
前言:输入 win+r 打开命令行进行下面操作
第一步:拉取镜像(以ubuntu为例)
docker pull ubuntu

第二步:创建容器
docker run -it --name <容器ID或名称> <镜像名称> /bin/bash
# 例如
docker run -it --name myUbuntu ubuntu /bin/bash
# 现在就可以在容器里面使用了
# 然后退出
exit

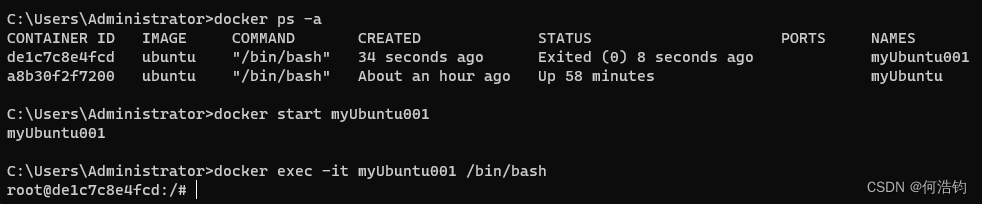
第三步:退出之后,再次进去容器里面
# 1.查看有哪些容器
docker ps -a
# 2.启动容器
docker start <容器ID或名称>
# 3.运行容器
docker exec -it <容器ID或名称> /bin/bash
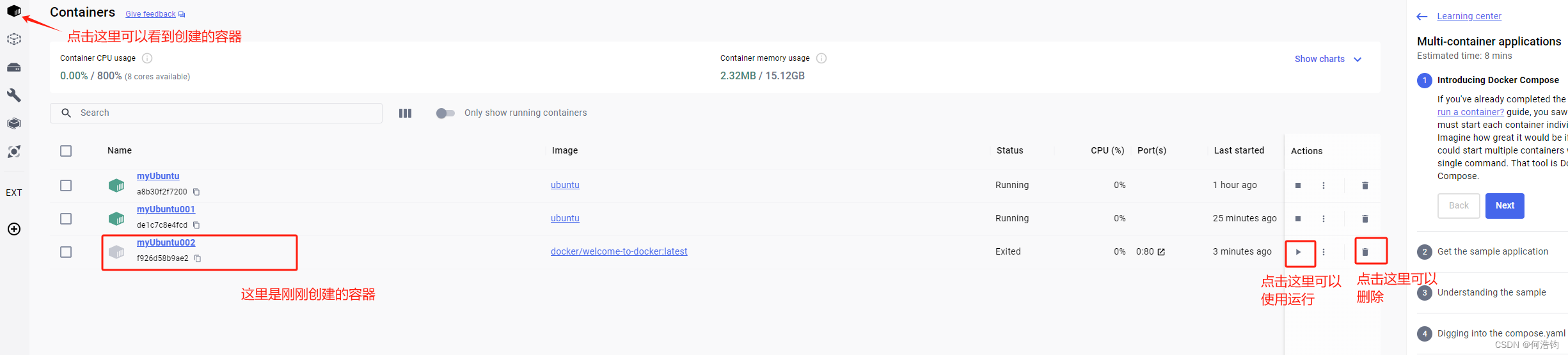
创建成功之后可以在docker软件里面看得到

2.2.docker软件里面创建
第一步:在里面搜索docker/welcome-to-docker
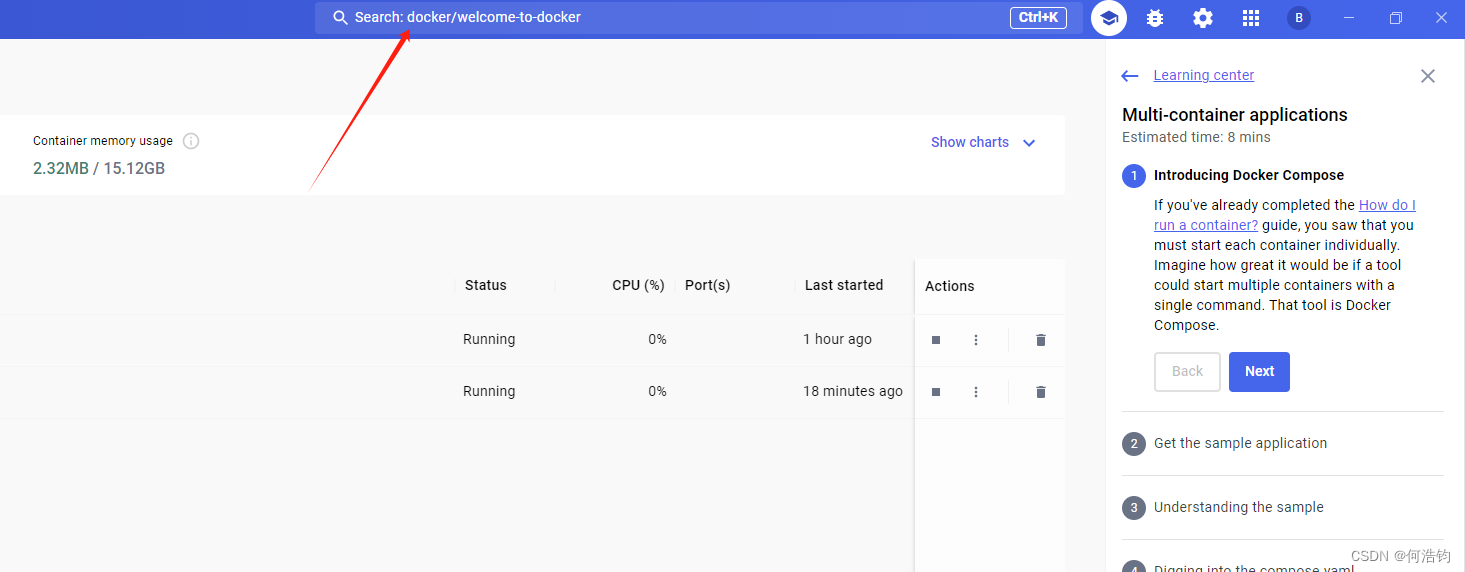
第二步:点击运行
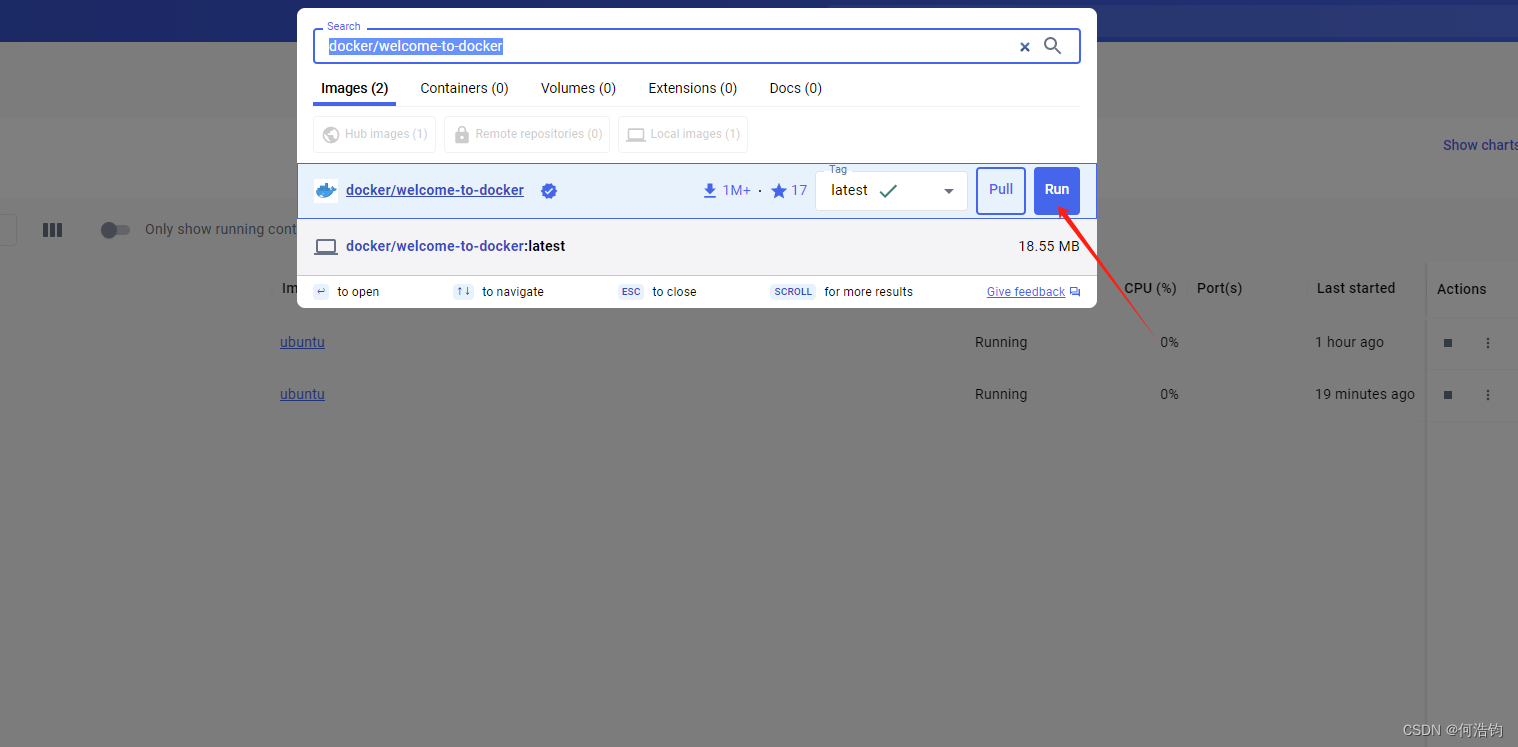
第三步:填写配置
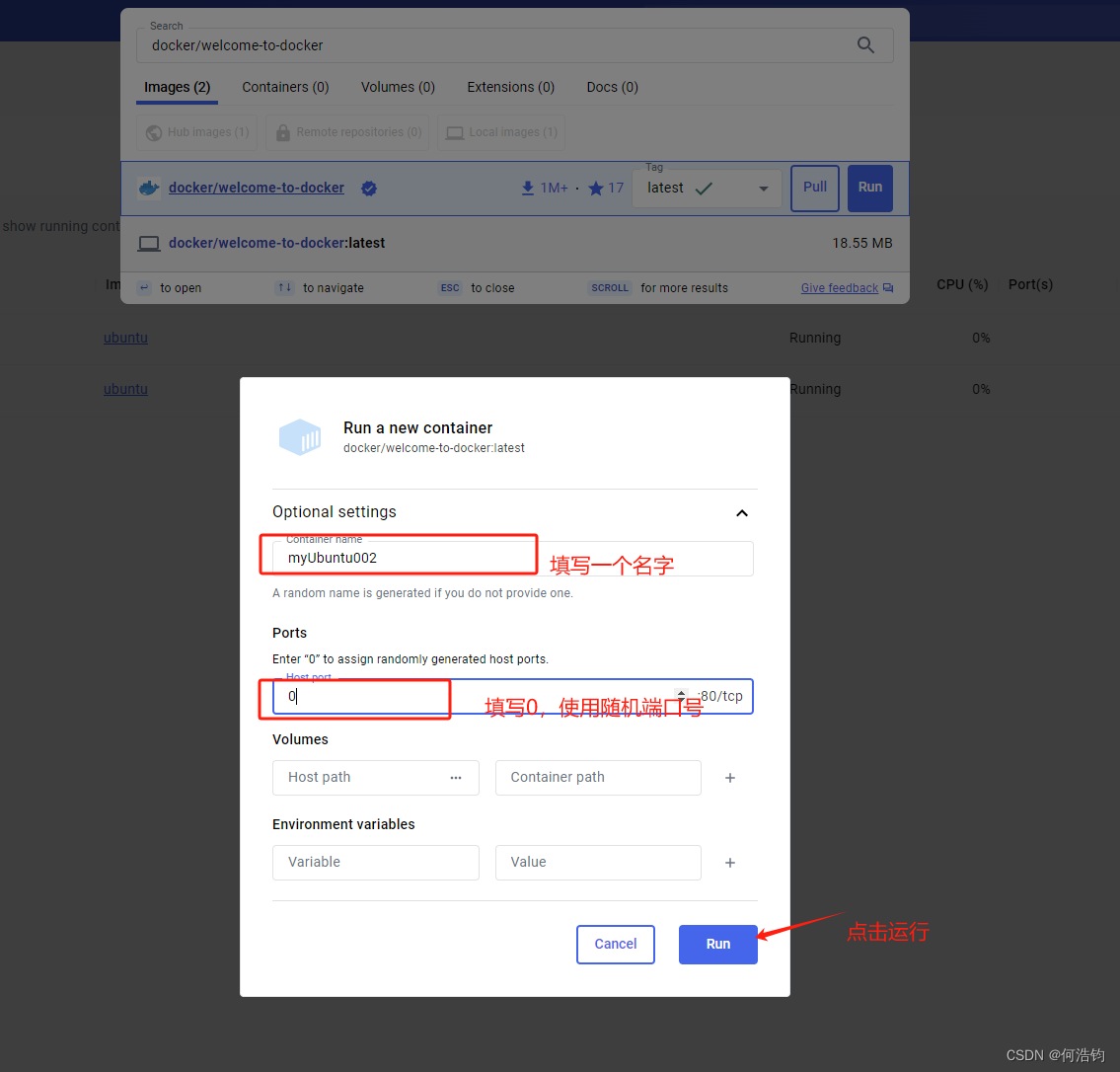
第四步:开始使用
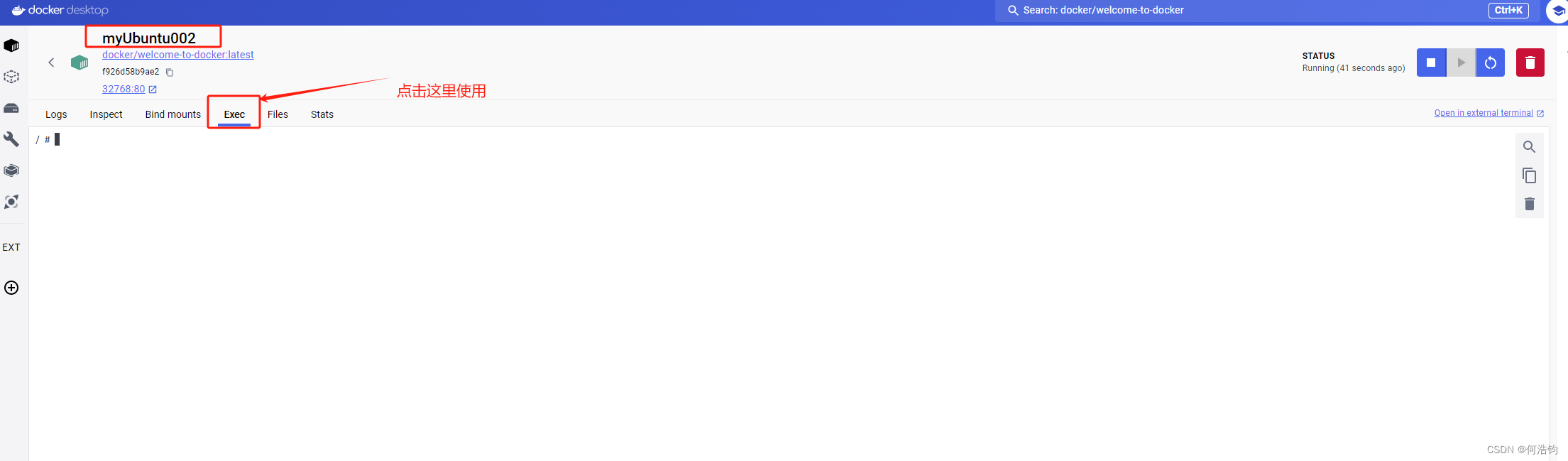
第五步:查看容器