健康门户网站建设律师推广网站排名
1 下载源码
下载opencv源码https://github.com/opencv/opencv

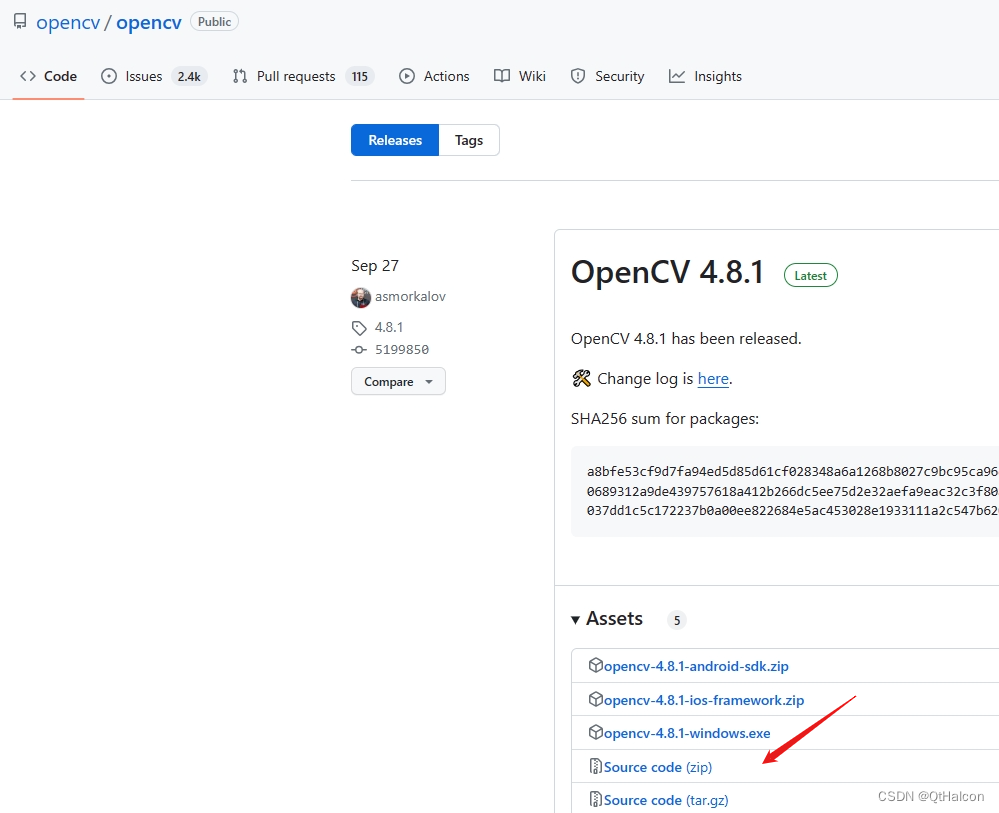
下载opencv源码https://github.com/opencv/opencv_contrib

2 开始编译
构建需要下载ffmpeg的包,cmake构建时会自动下载,但是比较满,这里可以从下面链接直接下载
https://download.csdn.net/download/qq_40732350/88655658
下载后解压到目录下面
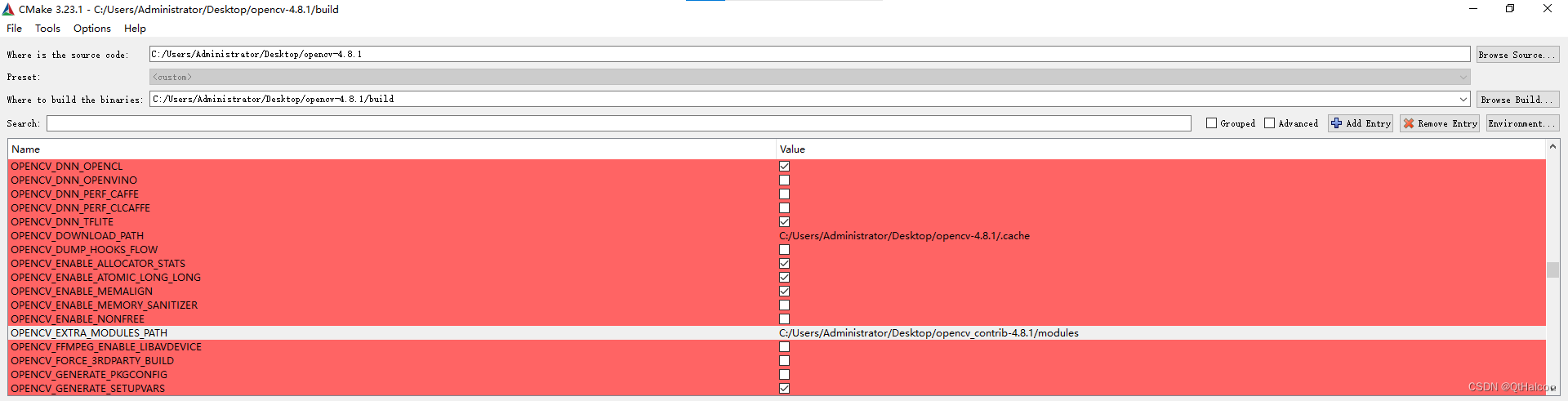
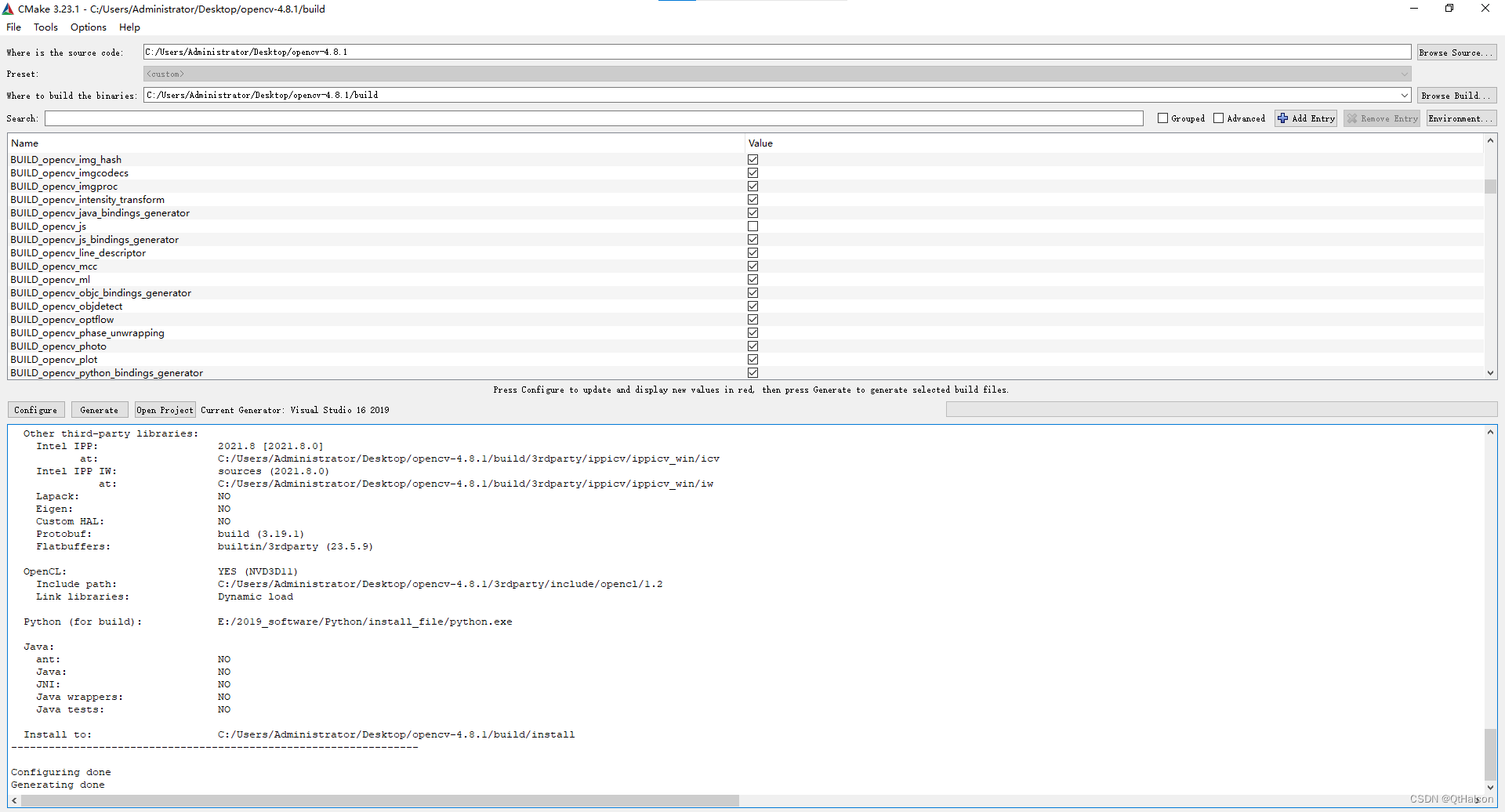
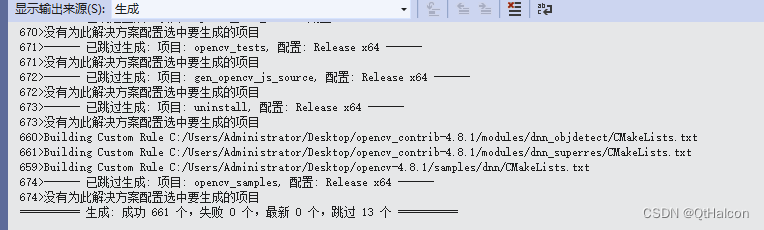
编译完成
安装完成

3 测试
#include<iostream>
#include<string>
#include<opencv2\core\core.hpp>
#include<opencv2\highgui\highgui.hpp>
#include<opencv2\imgproc\imgproc.hpp>
using namespace cv;
using namespace std;
int main(int argc,char*argv[])
{Mat img = cv::imread(argv[1], cv::IMREAD_COLOR);imshow("as", img);waitKey(0);return 0;
}