怎么做招聘网站手机版的网站用什么开发
背景
之前个人博客搭建时,发现页面加载要5s才能完成并显示
问题
React生成的JS有1.4M,对于个人博客服务器的带宽来说,压力较大,因此耗费了5S的时间
优化思路
解决React生成的JS大小,因为我用的是react-router-dom路由模块,查阅资料发现可以利用懒加载的机制,实现JS分割成不同的JS文件
利用React.lazy进行懒加载,在页面尚未加载完毕的时候,需要配置Suspense
Suspense的作用是当React.lazy懒加载完成时,就回调真正的页面实现展示
实现代码
import React, {Suspense } from 'react'
import { BrowserRouter, Route } from 'react-router-dom'
import { Loading } from '../components/common'import Home from '../components'
import Download from '../components/download/'
import Login from '../components/login'
import Prize from '../components/prize'
import News from '../components/news'
import NewsDetail from '../components/news/detail'
import Support from '../components/support'
import Me from '../components/me'
import Pay from '../components/pay'const App = () => (// 使用 BrowserRouter 的 basename 确保在服务器上也可以运行 basename 为服务器上面文件的路径<BrowserRouter basename='/'><Route path='/' exact component={Home} /><Route path='/download' exact component={Download} /><Route path='/prize' exact component={Prize} /><Route path='/news' exact component={News} /><Route path='/news/detail' exact component={NewsDetail} /><Route path='/support' exact component={Support} /><Route path='/me' component={Me} /><Route path='/pay' component={Pay} /><Login /></BrowserRouter>
)// 因为使用了多语言配置,react-i18next 邀请需要返回一个函数
export default function Main() {return (<Suspense fallback={<Loading />}><App /></Suspense>);
}
优化后效果
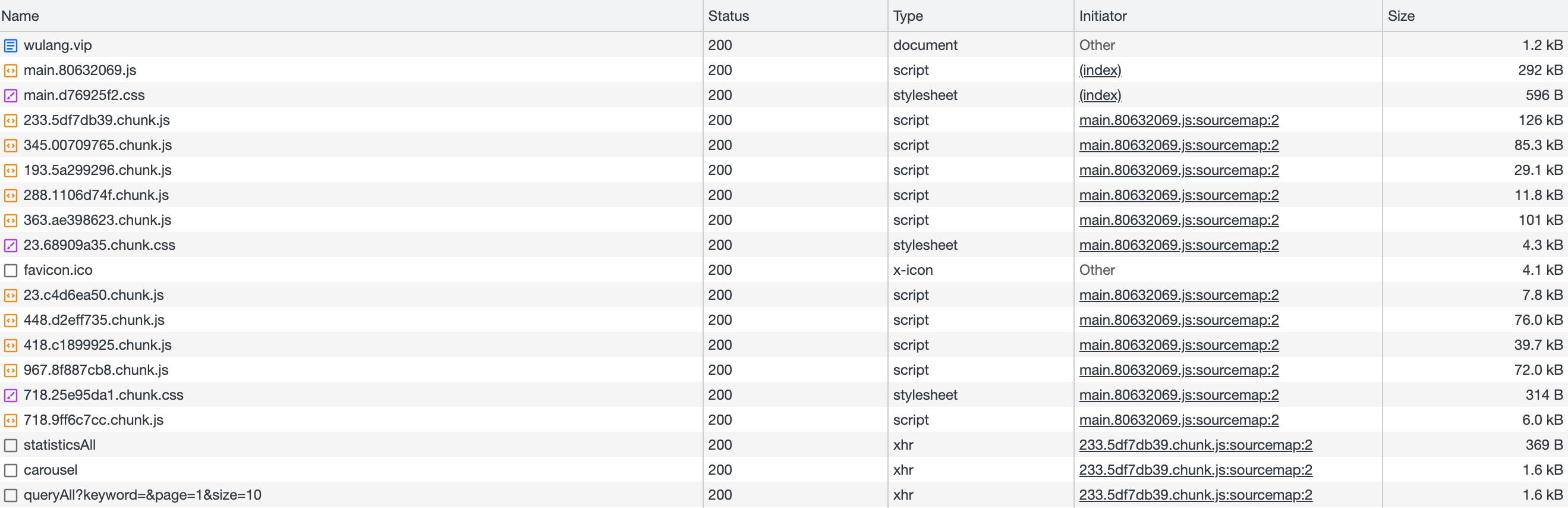
参考文章
- 博客原文