河南省教育类网站前置审批泰安市建设职工培训中心电话网站
1.编程语言介绍
ArkTS是HarmonyOS主力应用开发语言。它在TypeScript (简称TS)的基础上,匹配ArkUI框架,扩展了声明式UI、状态管理等相应的能力,让开发者以更简洁、更自然的方式开发跨端应用。

2.TypeScript简介
自行补充TypeScript知识吧。https://ts.nodejs.cn/
如果没有环境,可以使用在线的编辑器。https://playcode.io/typescript-playground

3.鸿蒙开发语音ArkTS
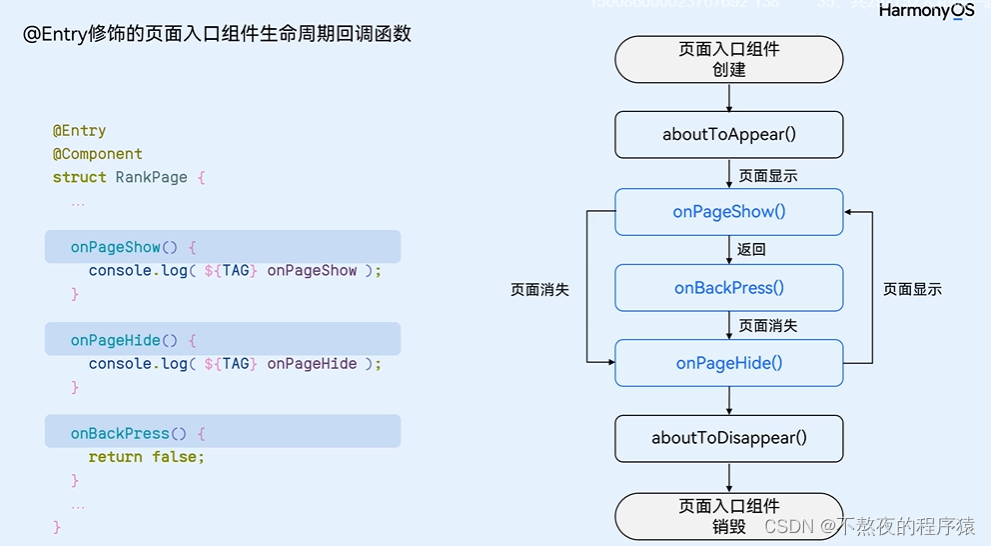
基本结构:

生命周期函数