教育类网站开发需求说明书各大网站开发语言
🔥博客主页: A_SHOWY
🎥系列专栏:力扣刷题总结录 数据结构 云计算 数字图像处理 力扣每日一题_
六天时间系统学习Python基础总结,目前不包括可视化部分,其他部分基本齐全,总结记录,学过C++和java等并用过一些py学起来快很多。另推荐某站学习课程链接在下方,讲解清晰。
【黑马程序员python教程,8天python从入门到精通,学python看这套就够了】https://www.bilibili.com/video/BV1qW4y1a7fU?p=115&vd_source=2a2d1efdeba6d2eedfe2fd5940c5f1be
一、字符串
1.字符串的三种定义方式


2.字符串格式化

3.字符串格式化的精度控制
用m.n控制数据的宽度和精度,m控制宽度,n控制小数点精度“%5d”、“%5.2f”、“%.2f”
如果m比数字本身的宽度还要小,就不会生效
*4.字符串格式化的快速写法
f”内容{变量}”
不会理会类型,不会做精度控制
5.对表达式进行格式化
表达式:一条有明确结果的代码语句,如1+1或者name=”张三”,age=1+1,type(“abcde”)
二、数据输入input
获取键盘的输入,可以使用input(提示信息),用于给用户提示。无论键盘输入什么类型,获取的都是字符串类型,需要自己类型转换。
print("请告诉我你是谁")
name=input()
print("我知道了,你是:%s"%name)
name=input("请告诉我你是谁?")
print("我知道了,你是:%s"%name)例:

user_name = input("请输入您的姓名")
user_type = input("请输入您的用户类型")
print(f"{user_name},您是尊贵的{user_type}用户,欢迎您的光临")三、判断语句
1.布尔类型和比较运算符
布尔类型的字面量:True,False
变量名称=布尔类型字面量
比较运算符:是否相等==,是否不相等!=,是否大于>,是否小于<,>=,<=
2.if判断语句
if 要判断的条件:
条件成立时,要做的事情
3.if else语句
if 条件:
满足条件要做的事情
else:
不满足条件要做的事情
4.if elif else语句
多个条件的判断,上一个满足后面的就不会判断了,可以在条件判断中直接写input
if 条件1:
条件1成立时,要做的事情
elif 条件2:
条件2成立时,要做的事情
elif 条件3:
条件3成立时,要做的事情
else:
所有条件都不满足要做的事情
5.判断语句的嵌套

补:随机数字:
import random
num = random.randint(1,2)
print(num)四、循环语句
1.while循环的基础应用
While 条件:
条件满足时,做的事情1
条件满足时,做的事情2
.......
只要条件满足,会无限循环执行
条件需要布尔类型,需要设置终止的条件
不换行:
print("hello",end='')
print("world",end='')
制表符:\t,多字符串整齐对齐
print("hello\tworld")
print("itheima\tbest")
例:打印99乘法表
i = 1
while(i <= 9):j = 1while(j <= i):print(f"{i} * {j} = {i * j}\t",end = '')j += 1print()i += 1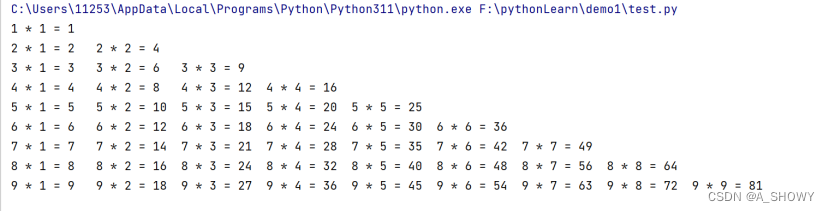
2.for循环
(1)for循环的基础语法
for 临时变量 in 待处理数据集(序列)
循环满足条件时执行的语句

无法定义循环条件,只能从被处理的数据集中依次取出处理,无法构建无限循环
(2)range语句
range(1, 9) 不生成列表,而是一个表示从1到8(不包括9)的范围的对象。在Python 3中,range() 函数返回的是一个可迭代的对象,而不是立即生成所有元素的列表。
如果需要将其转换为列表,可以使用 list() 函数
序列:指内容可以一个个依次取出的类型:字符串,列表,元组
range语句可以获得一个简单的数字序列
语法1:
range(num)
获取一个从0开始,到num结束的数字序列(不含num本身)
语法2:
Range(num1,num2)
从num1开始到num2结束的数字序列,不含num2本身
语法3:
Range(num1,num2,step)
从num1开始到num2结束的数字序列(不含num2本身),数字之间的步长是step
(3)for循环临时变量作用域
临时变量,在编程规范上,作用范围,只限定在for循环内部
for i in range(5):print(i)
print(i)如果想访问这个临时变量i,可以在for循环之前定义一个i=0,后面只是一遍遍覆盖这个i
for循环和while循环可以互相嵌套使用
例子:99乘法表
for i in range(1,10):for j in range(1,i + 1):print(f"{i}*{j} = {i * j}\t",end = '')print()3.break和continue
(1)continue临时中断
中断本次循环,直接进入下一次循环

Continue语句只可以控制它所在的循环临时中断
(2)Break永久中断

break关键字用于直接结束循环
break语句也只控制他所在的循环
例:发工资

import random
i = 1
money = 10000
for i in range(1,21):t = random.randint(1,10)if t < 5:print(f"员工{i},绩效分{t},不发工资,下一位")continueif (t >= 5):if money <= 0:print("工资发完了,下个月领取吧")breakelse :money -= 1000print(f"向员工{i}发工资1000元,账户余额还剩余{money}元")五、函数
1.函数的基础定义语法
def 函数名(传入参数):
函数体
return 返回值
传入参数和return可以省略,函数必须先定义后使用
函数的调用:
函数名(参数)
2.函数的参数使用
传入参数:在函数进行计算的时候,接受外部提供的数据
可以不使用参数,也可以使用任意N个参数
3.函数的返回值
变量=函数(参数)
返回值会给到这个变量
函数体一遇到return就结束了,后面的代码不会执行了。
4.函数的返回值的None类型
无返回值的函数实际上是返回了None这个字面量 <class 'NoneType'>
使用场景:
函数返回值;
在if判断中,None等同于False;
None也用于声明无初始内容的变量。
5.函数的说明文档

写上”””回车会自动出来前面的格式,鼠标放在调用的括号上会出来说明文档。
6.函数的嵌套调用
一个函数里又调用了另外一个函数
7.变量在函数中的作用域
作用域:变量在哪里可用,在哪里不可用
局部变量和全局变量和global关键字
局部变量:定义在函数体内部的变量,只在函数体内部生效
临时保存数据,在函数调用完后立即销毁变量
全局变量:在函数体内、外都能生效的变量
将变量定义在函数的外面
global关键字

如果没有global,函数B里的num还是局部变量
六、数据容器
1.数据容器的入门
一个容器容纳多份数据,每一份数据称为一个元素,每个元素可以是任意类型的数据。
列表、元组、字符串、集合、字典
2.列表
(1)列表的语法

列表中的元素可以是不同类型,支持嵌套
(2)列表的下标索引


获取对应位置的元素:
列表[下标索引]

(3)列表的常用操作
在python中如果将函数定义为class(类)的成员,函数就会称之为:方法。方法和函数只是使用格式不同。

列表的方法:
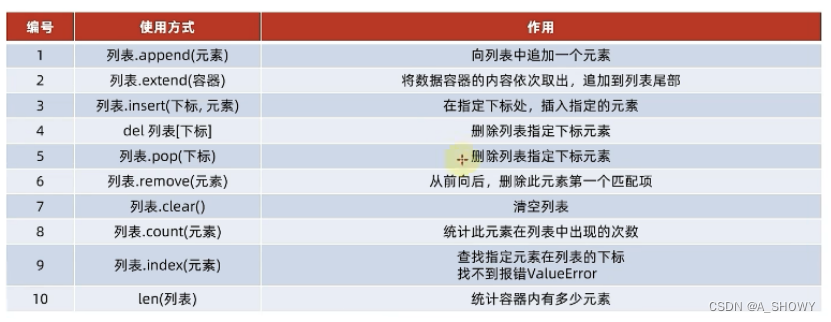
①查找某元素的下标,如果找不到,报错ValueError
语法:列表.index(元素)
②修改特定位置(索引)的元素值
语法:列表[下标]=值
③插入元素
语法:列表.insert(下标,元素),在指定的下标位置,插入指定的元素
④追加元素
语法:列表.append(元素),将指定元素,追加到列表的尾部
或者语法:列表.extend(其他的数据容器),将其他的数据容器的内容取出,依次追加到列表尾部
⑤删除元素
语法一:del 列表[下标]
语法二:列表.pop[下标],还能用变量接收删除的元素
⑥删除某元素在列表中的第一个匹配项
语法:列表.remove(元素)
⑦清空列表内容
语法:列表.clear()
⑧统计某个元素在列表中的数量
语法:列表.count(元素)
统计列表元素个数,这个不叫方法
语法:len(列表)
(4)列表的循环遍历
列表的while循环遍历
遍历:将容器内的元素依次取出进行处理的行为
列表的for循环遍历,for 临时变量 in 数据容器:临时变量进行处理
While循环适用于任何想要循环的场景
for循环适用于遍历数据容器的场景或简单的固定次数循环场景
#遍历两种写法
list = [21,25,21,23,22,20]
index = 0
while index < len(list):ele = list[index]print(f"元素{ele}")index += 1for x in list:ele = xprint(ele)
3.元组
列表是可以被修改的;元组一旦定义完成,就不可以修改


通过下标索引取出内容和list一样

元组里嵌套的list里的内容可以修改
4.字符串
字符串是一个无法修改的数据容器
常用操作

(1)查找特定字符串的下表索引值
语法:字符串.index(字符串)
字符串.rindex(字符串)找到的是最后一个字符串出现的位置
(2)字符串的替换
语法:字符串.replace(字符串1,字符串2)
将字符串内的全部字符串1,替换为字符串2
注意:不是修改了字符串本身,而是得到了一个新字符串
*(3)字符串的分割
语法:字符串.split(分隔符字符串)
功能:按照指定的分隔符字符串,将字符串划分为多个字符串,并存入列表对象中
注意:字符串本身不变,而是得到了一个列表对象
*(4)字符串的规整操作(去前后空格)
strip()去除开头和结尾的空格和换行符

(4)统计字符串中某个字符串出现的次数
语法:字符串.count(字符串)
(5)字符串长度
len(字符串)
字符串的遍历也支持while循环和for循环
¥(6)join方法
将序列中的元素连接成字符串,可以指定元素和元素之间连接的字符川
语法:separator.join(iterable)
- separator 是一个字符串,用于在连接时放置在序列的元素之间。
- iterable 是一个可迭代对象,通常是一个包含字符串的列表或元组。
不加分隔符:"".join(words)
¥(7)zfill方法
zfill 是字符串对象的一个方法,它用于在字符串的左侧(即字符串的开头)用零填充字符串,使其达到指定的宽度
语法:str.zfill(width)
¥(8)bin函数
将整数转换为二进制表示,会自动返回一个二进制的字符串,这个字符串以"0b"为前缀,后面跟着二进制表示的数字
5.数据容器(序列)的切片
序列:内容连续、有序,可使用下标索引的一类数据容器。列表、元组、字符串都可以视为序列。
切片:从一个序列中,取出一个子序列。
语法:序列[起始下标:结束下标:步长]
起始下标留空视作从头开始,结束下标留空(含)视作截取到结尾。结束下标(不含)表示何处结束。步长省略默认为1
步长1表示挨个取,步长2表示每次跳过一个取,步长N表示每次跳过N-1个取,步长为负数表示反向取。
[:-2]表示从头开始取到倒数第二个(不包含)
切片操作不会影响序列本身,而是得到一个新的序列
6.集合
列表可以修改、支持重复元素且有序;元组、字符串不可修改、支持重复元素且有序。
集合不支持重复元素且内部无序。不支持下标索引访问。集合可以修改

常用操作
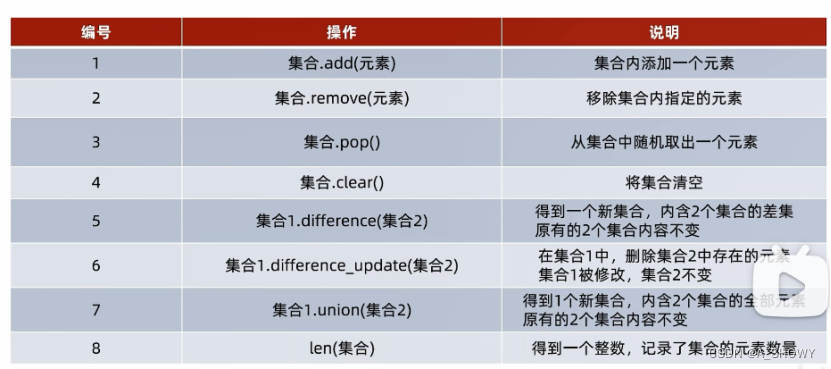
①添加新元素
语法:集合.add(元素)
②移除元素
语法:集合.remove(元素)
③从集合中随即取出元素
语法:集合.pop()
④清空集合
语法:集合.clear()
⑤取出两个集合的差集
语法:集合1.difference(集合2)
功能:取出集合1里有而集合2没有的
结果:得到一个新的集合,集合1和集合2不变
⑥消除2个集合的差集
语法:集合1.difference_update(集合2)
功能:在集合1内删除和集合2相同的元素
结果:集合1被修改,集合2不变
⑦两个集合合并
语法:集合1.union(集合2)
功能:将集合1和集合2合成新集合
结果:得到新集合,集合1和集合2不变
⑧统计集合元素数量
语法:len(集合)
⑨集合的遍历
集合不支持下标索引所以不能用while循环,但是可以用for循环
⑩集合的交集
common = set1 & set2,返回的是包含两个集合中相同集合的元素
集合的update()方法
该方法会修改原始集合,将可迭代对象中的元素添加到集合中,如果有重复的元素,则只保留一个副本。
set1 = {1, 2, 3}
tuple1 = (2, 3, 4)
set1.update(tuple1)7.字典


字典的key不可以重复,不可以使用下标索引,但是可以用key获得对应的value
语法:字典[key]
字典的嵌套:Key和value可以是任意数据类型(key不能为字典)
字典的常用操作

①新增元素
语法:字典[key]=value,结果:字典被修改,新增元素
②更新元素
语法:字典[key]=value,结果:字典被修改,元素被更新(效果不同取决于key存不存在)
③删除元素
语法:字典.pop(key),结果:获得指定key 的value,同时字典被修改,指定key的数据被删除
④清空元素
语法:字典.clear()
⑤获取全部的key
语法:字典.keys(),结果:得到字典中的全部key;字典.values(),得到字典中的全部value
⑥遍历字典
方式一:通过获取全部的keys来完成遍历

方式二:直接对字典进行for循环,每一次循环都是直接得到key

⑦统计字典内的元素数量
语法:len(字典)
Python在遍历字典时不允许修改字典元素,会报错RuntimeError: dictionary changed size during iteration,可以改为for k in list(my_dict.keys()):
8.数据容器总结


9.数据容器通用操作

(1)遍历
(2)len(容器)
(3)max(容器)
(4)min(容器)
(5)通用类型转换
①list(容器),容器转换成列表。字符串转列表将字符串每个元素都取出来作为列表的每个元素。字典将value抛弃掉只剩下key。
②tuple(容器),容器转换成元组。
③str(容器),容器转换成字符串。“[1,2,3,4,5]”“(1,2,3,4,5)”“{1,2,3,4,5}”,字典的value会保存
④set(容器),容器转换成集合。
⑤dict(容器),容器转换为字典。将其他序列转化成字典的时候 对这个序列有要求,这个序列得是二维的, 内层序列得有两个元素
[['语文', 77], ['数学', 78]]
*(6)通用排序功能
sorted(容器,reverse=True),传入True就是从小到大,传入False就是从大到小。排序的结果会全部变成列表,字典会丢失value
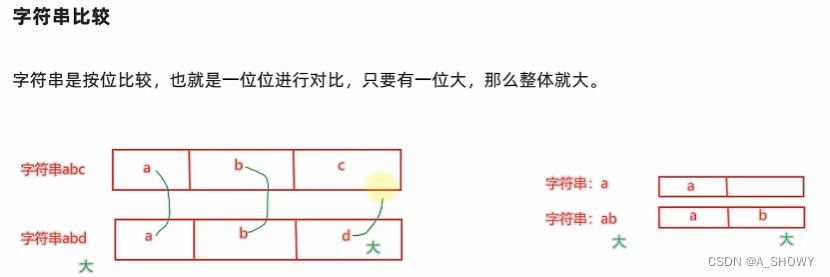
拓展:字符串大小比较
ASCII码表:大小写英文字母,数字,特殊符号都有对应的ASCII码
字符串进行比较就是基于ASCII码值大小进行比较的
七、函数进阶
1.函数的多返回值

逗号隔开的可以返回不同的类型
2.函数的多种传参方式
使用方式不同,四种常见的参数使用方式
(1)位置参数
调用函数时根据函数定义的参数位置来传递参数
(2)关键字参数
函数调用时通过“键=值”形式传递参数

(3)默认参数(缺省参数)
为参数提供默认值,调用函数时可以不传该默认参数的值,注意:所有位置参数必须在默认参数前。默认参数必须统一都在最后面

(4)不定长参数(可变参数)
用于不确定调用的时候会传递多少个参数
分为:
位置传递不定长
参数数量不一定多少

关键字传递不定长

3.匿名函数
(1)函数作为参数传递
前面我们学的都是接受数据作为参数传入:
数字、字符串、字典列表元组等
也可以函数本身作为参数传入另一个函数内

是一种计算逻辑的传递,而非数据的传递
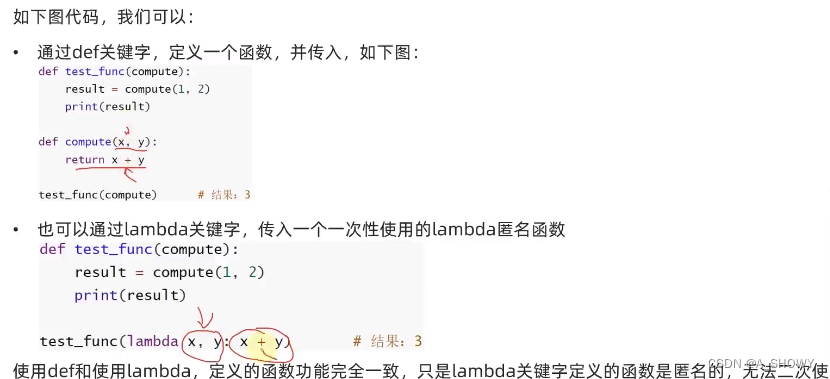
(2)lambda匿名函数
函数的定义中
def关键字,可以定义带有名称的函数,可以反复使用
lambda关键字,可以定义匿名函数(无名称),只能临时使用一次
语法:
lambda 传入参数:函数体(只能写一行代码)
八、Python的文件操作
1.文件的编码
文本文件使用编码技术(密码本)将内容翻译成0和1存入计算机中。
编码技术:翻译的规则,记录了如何将内容翻译成二进制,以及如何将内容翻译回可识别内容。
计算机中可用编码:UTF-8、GBK、Big5等
2.文件的读取
什么是文件?文本文件、视频文件、音频文件、图像文件、可执行文件
对文件的操作:打开、关闭、读、写
文件的操作步骤:打开-读写-关闭
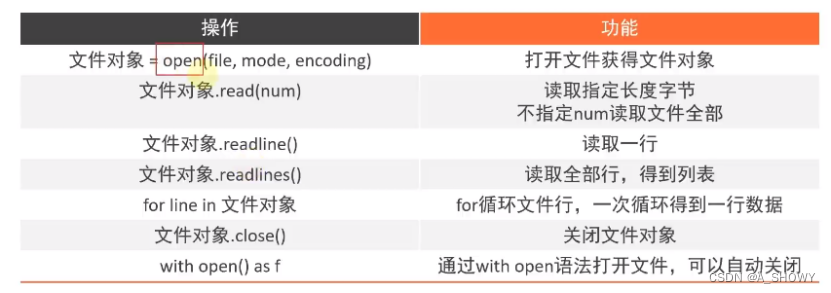
(1)打开


(2)读操作

Readlines:读取全部行,封装到列表
Read():读取全部,到字符串
多次调用read,后面的read会在上一次read的结尾处开始读
\n是回车换行符


(3)关闭文件

(4)with open语法

例子;文件的读取,统计里面“chenzi”的数量
f = open('E:\guozi.txt','r',encoding = 'UTF-8')
count = 0
for line in f:line = line.strip()words = line.split(" ")print(words)for word in words:if word == "chenzi":count += 1
print (count)
f.close()3.文件的写入

write方法,内容并未真正写入文件,会在内存中的缓冲区,调用flush的时候才会真正写入文件。避免频繁操作硬盘。
f.write写入的必须是字符串不能是别的。
Close()内置了flush()
4.文件的追加

a模式,文件不存在会创建文件
文件存在会追加写入文件,在原有内容后面继续写入,可以使用“\n”来换行
九、Python异常、模块与包
1.异常
程序运行过程中出现了错误(Bug)
(1)异常的基本捕获方法:
基本语法:
try:
可能发生错误的代码
except:
如果出现异常执行的代码
(2)捕获指定异常
基本语法:
try:
print(name)
except NameError(异常) as e(别名):
print(‘name变量名称未定义错误’)
(3)捕获多个异常

(4)捕获全部异常
try:
except Exception as e:
(5)异常else
else表示的是如果没有异常要执行的代码
try:
except Exception as e:
else:
(6)异常的finally(放在最后)
表示无论是否异常都要执行的代码,例如关闭文件
try:
except Exception as e:
else:
finally:
2.异常的传递
异常具有传递性

3.python的模块
模块(module),是一个python文件,以.py结尾,模块能定义函数,类和变量,也可能包含可执行的代码。一个模块就是一个工具包
(1)模块的导入方式
一般写在开头的位置
中括号是表示可以写可以不写

基本语法:
(1)
import 模块名 模块里所有功能都能用
import 模块名1,模块名2
模块名.功能名()
(2)
from 模块名 import 功能名 模块里只有这一个功能能用
功能名()
(3)
from 模块名 import * *表示全部的意思,和(1)的区别不需要用.
(4)

4.自定义python模块
注意:当导入多个模块的时候,且模块内有同名功能,当调用同名功能,调用到的是后面导入模块的功能。
(1)__main__变量

__main__变量所提供的功能:运行这个模块文件的时候name被自动赋值了main所以会运行,但去另一个用这个模块的文件中运行就不会了。

(2)__all__变量

__all__作用在*上
5.自定义python包
Python包就是一个文件夹,在该文件夹下包含了一个__init__.py文件(创建包会默认自动创建的文件),这个文件存在才说明这是一个包。

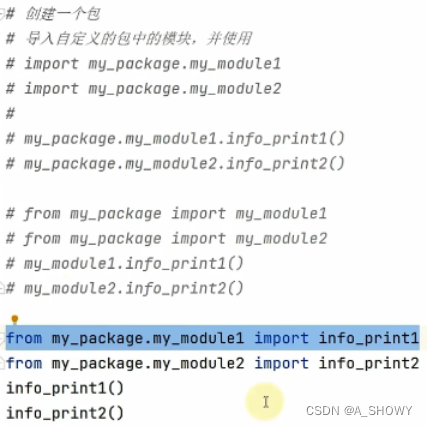
导入包:
(1)方式一

或者用 from 包名 import 模块名,这样不用写包名.了
下面三种方法
(2)方式二
通过__all__变量控制import *
在__init__.py文件里定义__all__变量
6.第三方包

(1)安装方法一
使用pip程序即可,打开命令提示符程序,在里面输入:pip install包名称
国内网站安装命令:
![]()
(2)安装方法二
在pycharm里安装

点加号搜索安装就行,如果想用国内的就在选项勾选然后输入
![]()
十、可视化案例
等待更新
十一、面向对象
生活中或是程序中,我们都可以使用设计表格、生产表格、填写表格的形式组织数据
使用对象组织数据
设计类

创建对象

对象属性赋值

1.类的成员方法
(1)类的定义和使用



定义在类内部的函数称之为方法

调用的时候self关键字可以不用理会,不用写这个参数
2.类和对象
现实世界的事物由属性和行为组成,类也可以包含属性和行为,所以类很适合用来描述现实世界。
面向对象编程:设计类,基于类创建对象,由对象做具体的工作。
3.构造方法

注意事项:
构造方法也是成员方法,self关键字不要忘记,构造方法内访问成员变量,要用self。
4.魔术方法
__init__构造方法,是pythontip类内置的方法之一,这些内置的类方法,各自有各自的特殊功能,这些内置方法我们称之为:魔术方法。

(1)__str__字符串方法
当类对象需要变成字符串就会通过字符串方法去变成字符串的形式,如果不写就会输出内存地址


(2)__lt__小于符号比较方法

(3)__le__小于等于比较符号方法

(4)__eq__比较运算符实现方法

5.封装
封装是:将现实世界的属性和行为,封装到类中描述为成员变量和成员方法。
私有成员:
私有成员变量:变量名以__开头
私有成员方法:方法以__开头(两个下划线)
私有成员无法被类对象使用,但是可以被类中的其他成员使用。
6.继承
(1)单继承

class 类名(父类名):
类内容体
(2)多继承
一个类继承多个父类
class 类名(父类1,父类2,......,父类N):
类内容体
多个父类中,如果有同名的方法或者属性,先继承的优先级高于后继承(左边的高)
pass关键字的作用:占位语句,用于保证定义的完整性,表示无内容,空的意思。
(3)复写父类成员
子类继承父类的成员属性和方法后,如果对其不满意,可以进行复写

调用父类同名成员

注意:只可以在子类内部调用父类的同名成员,子类的实体类对象调用默认是调用子类复写的。
7.类型注解
为什么需要类型注解?
在代码中涉及数据交互的地方,提供数据类型的注解(显示的说明)
主要功能:
帮助IDE对代码进行类型推断,协助做代码提示;帮助开发者自身对变量进行类型注释
支持:
(1)变量的类型注解;
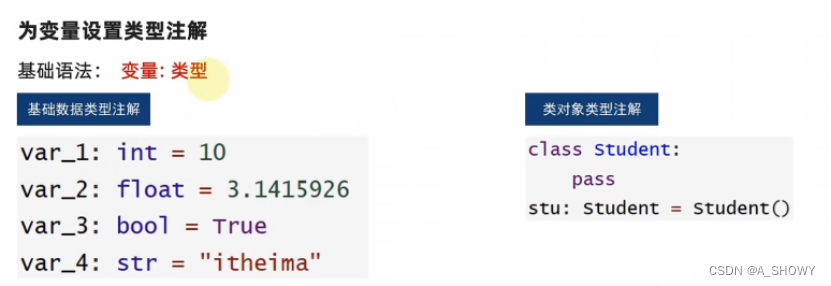

为变量设置注释,显示的变量定义,一般无须注解


类型注解只是提示性的,不是强制性的,不会报错
(2)函数(方法)形参列表和返回值的类型注解


、
(3)union类型


8.多态
多态:多种状态,即完成某个行为时,使用不同的对象会得到不同的状态。

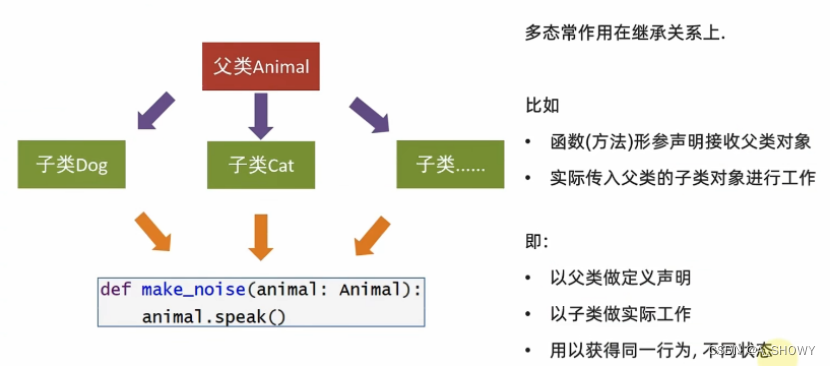
*抽象类(接口)

抽象类就好比定义一个标准,包含了一些抽象的方法,要求子类必须实现。