wamp 多网站怎么做二维码微信扫后直到网站
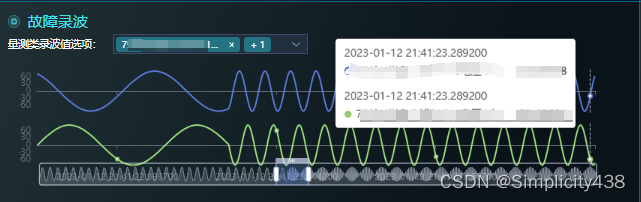
实现效果
根据接口传来的数据,使用echarts绘制出,共用一个x轴的图表
功能:后端将所有数据传送过来,前端通过监听选中值来展示对应的图表数据
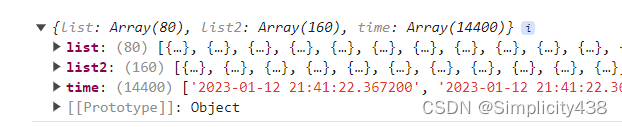
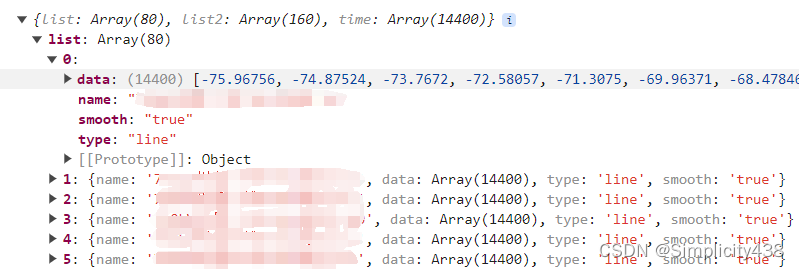
数据格式:
代码:
<template><div><div class="screen-list-item"><span style="display: inline-block; width: 140px">量测类录波值选项:</span><el-selectmultiplecollapse-tagscollapse-tags-tooltipstyle="width: 260px"clearablepopper-class="select-box":teleported="false"v-model="SensorListVal"placeholder="请输入量测"size="small"class="m-2"><el-optionv-for="item in SensorList.data":key="item.value":label="item.label":value="item.value"/></el-select></div><divid="FaultRecording1"style="width: 800px; height: 180px; margin: auto"></div></div>
</template><script>
// 引入echarts
import * as echarts from "echarts";
import { onMounted, reactive, ref, watch } from "vue";
// 调用接口数据
import { AllRecordDataApi } from "@/utils/record";
import { RecordPostBc } from "@/utils/request";export default {setup() {let recordDataList = ref([]);let xseriesdata = ref([]);let SensorListVal = ref([]);let SensorList = reactive({data: [],});// 获取录波数据let recordData = async () => {const result = await RecordPostBc(AllRecordDataApi, {});console.log(result)// 找出数据中所有选项,为筛选框的选择项SensorList.data = result.list.map(obj => ({ value: obj.name, label: obj.name }) );// 图表数据recordDataList.value = result.listxseriesdata.value = result.time// 默认选择前两项SensorListVal.value = SensorList.data.slice(0, 2).map(item => item.value);recordEcharts1()}//绘制图表let recordEcharts1 = () => {let myChart = echarts.init(document.getElementById("FaultRecording1"));myChart.clear(); // 清除之前的图表实例let options = {grid: [// 第一个折线图{left: '3%',right: '4%',top: '10%',height: '32%',},// 第二个折线图{left: '3%',right: '4%',top: '50%',height: '32%',},],tooltip: {trigger: 'axis', },// 将上下两个tootip合成一个axisPointer: {link: { xAxisIndex: 'all' },},xAxis: [{type: 'category',scale: true,axisLabel: {show: false,},data: xseriesdata.value, //x轴时间的数据},{gridIndex: 1,type: 'category',scale: true,data: xseriesdata.value, //x轴时间的数据},],yAxis: [{type: 'value',scale: false,splitLine: {show: false,},},{type: 'value',gridIndex: 1,scale: true,splitLine: {show: false,},},],dataZoom: [{show: true,realtime: true,start: 30,end: 70,xAxisIndex: [0, 1],},{type: "inside",realtime: true,start: 30,end: 70,xAxisIndex: [0, 1],},],series: [],};// 添加每条曲线数据到 series 中for (var i = 0; i < recordDataList.value.filter(record => SensorListVal.value.includes(record.name)).length; i++) {options.series.push({xAxisIndex: i,yAxisIndex: i,name: recordDataList.value.filter(record => SensorListVal.value.includes(record.name))[i].name,type: 'line',smooth: 'true',data: recordDataList.value.filter(record => SensorListVal.value.includes(record.name))[i].data});}myChart.setOption(options);}onMounted(() => {recordData();});// 监听 SensorListVal 的变化watch(SensorListVal, (newValue, oldValue) => {recordEcharts1()});return { SensorList, SensorListVal };},
};