中国站长网站株洲网站建设优化
模板添加及模板过户操作流程:
一、添加模板操作流程:
1.在业务管理-域名管理-模板管理中找到“添加模板”
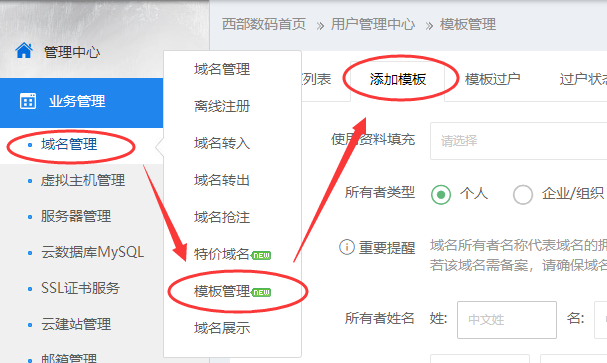
2.选择所有者类型(个人或是企业/组织),填写新的域名所有者资料,填写无误后点击“确定”。
目前需要进行实名认证的域名有哪些:关于域名实名认证 -西部数码帮助中心
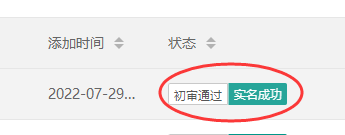
是否全部审核通过可以点击“实名成功”,如下图:
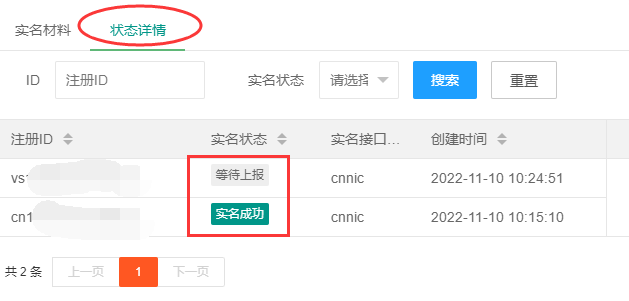
再点击“状态详情”,同一时间提交的都显示“实名成功”,然后就可以参考第二步办理模板过户了,如果还有注册ID对应的显示“等待上报”,请耐心等待上级单位审核,一般1-3个工作日内完成。
二、模板过户操作流程:
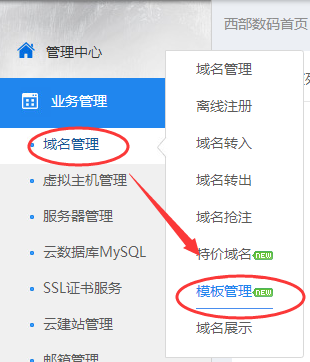
1、使用账号和密码登录我司网站,点击业务管理——域名管理——模板管理。
2、点击模板过户,在域名列表选择域名或填写您需要过户的域名,一行一个域名,一批次过户域名后缀应相同。然后选择状态已经实名成功的模板资料,再点击“立即提交过户”。
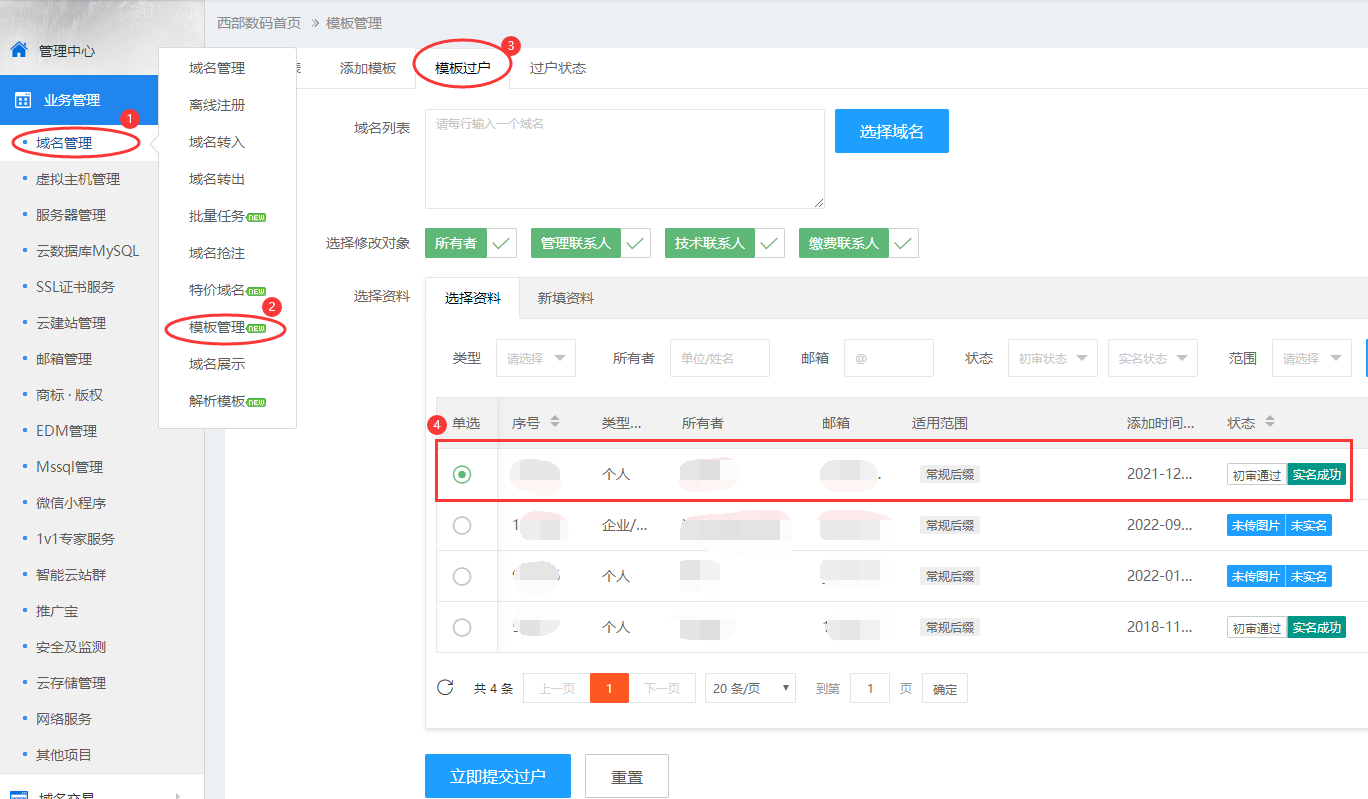
3、若没有对应的模板,请先参考第一步添加模板,再进行过户。模板名称可以填写您模板的所有者,也可以填写一个您自己能够区分的模板名字。
4、若需要过户的域名不支持模板过户,请按照页面说明提交过户前及过户后的相关资料进行过户。
域名过户常见问题:
域名过户:是指域名的当前所有人将域名转让给其他个人或团体,即转移此域名所有权的行为。域名过户给其他人后,您的域名所有权将变为您过户给的个人或团体。
模板过户:操作为在线自动过户,无须审核。适合没有纠纷的情况下快速过户,如果相关域名出现所有权纠纷,我司有权将域名所有者信息还原为历史信息,然后双方重新按常规过户流程操作。
原文链接:https://www.west.cn/faq/list.asp?unid=746