百度公司电话是多少泉州seo培训
文章目录
- 前言
- 一、Linux内核的特征
- 二、Linux操作系统结构
- 1.Linux在系统中的位置
- 2.Linux内核的主要子系统
- 3、Linux系统主要数据结构
- 三、linux内核源码组织
- 1、下载Linux源码
- 2、Linux版本号
- 3、linux源码架构目录讲解
前言
这里将是我们从零开始学习Linux的第一节,这节课我们将了解Linux源码的各个文件夹的组成与含义。
一、Linux内核的特征
1、开源:Linux内核是开源的,用户和开发者可以自由地查看、学习、修改和分发内核代码,促进了协作和创新。
2、可移植性:Linux内核被设计为高度可移植的,可以在各种不同的硬件平台上运行,包括个人计算机、服务器、嵌入式设备、移动设备等。
3、多任务和多用户支持:Linux内核支持多任务和多用户操作。它可以同时运行多个程序,并为每个程序提供独立的执行环境。
4、强大的网络支持:Linux内核具有强大的网络支持,包括TCP/IP协议栈、网络设备驱动程序和网络协议的实现。
5、模块化设计:Linux内核采用了模块化的设计,允许核心功能和设备驱动程序以模块的形式加载和卸载,提高了系统的灵活性和可维护性。
6、良好的性能和可靠性:Linux内核经过长时间的发展和优化,具有良好的性能和可靠性。
7、支持广泛的硬件和软件生态系统:Linux内核支持广泛的硬件设备和软件应用。它具有丰富的设备驱动程序和接口,可以与各种硬件设备和外部设备进行通信。同时,Linux拥有庞大的开源软件生态系统,提供了各种应用程序、开发工具和库,满足了不同用户和开发者的需求。
二、Linux操作系统结构
1.Linux在系统中的位置
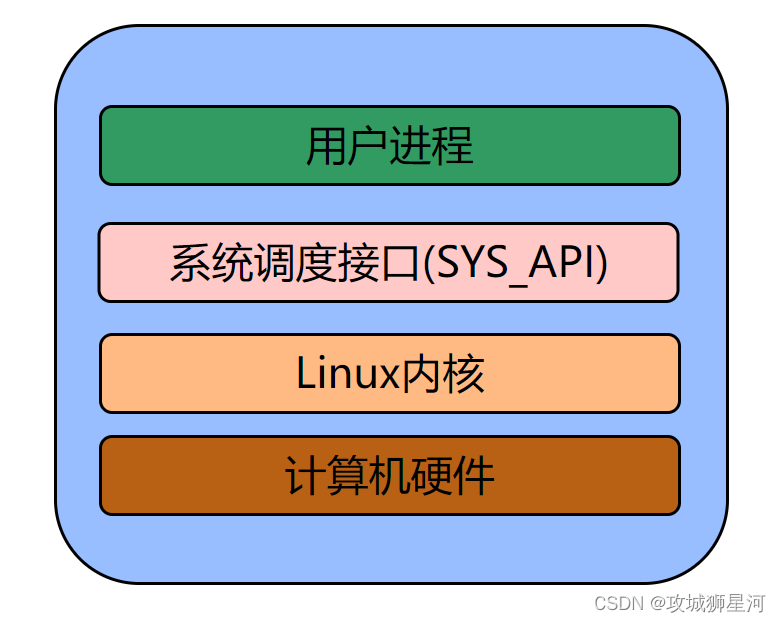
2.Linux内核的主要子系统
Linux内核可以根据功能和任务划分为以下几个主要的子系统:
1、进程管理子系统:负责管理进程的创建、调度、终止和通信等任务。
2、文件系统子系统:提供文件和目录的管理、访问和操作功能,包括各种文件系统的实现。
3、网络子系统:处理网络协议栈、网络设备驱动程序和网络通信等网络相关任务。
4、内存管理子系统:管理系统内存的分配、释放和映射,包括虚拟内存管理和页面置换等功能。
5、设备驱动程序子系统:提供与硬件设备的交互和控制,包括各种设备驱动程序的实现。
每个子系统都有特定的责任和功能,通过协同工作,实现了Linux内核的全面功能和可靠性。
Linux内核还包含其他子系统,如电源管理子系统、安全子系统、时钟和定时器子系统等,这些子系统也在特定领域提供了重要的功能和服务。
3、Linux系统主要数据结构
在Linux内核中,有以下这些使用频率较高的数据结构:
task_struct: 代表一个进程数据结构指针,形成一个task数据
mm_struct:代码进程的虚拟内存
inode:代表虚拟文件系统中的文件、目录等对应的索引节点
还有很多相关的数据结构,我们后面慢慢讲
三、linux内核源码组织
1、下载Linux源码
想要更快的了解Linux架构,那么首先需要下载一版Linux源码,关于如何下载Linux源码:可以查看我之前写的文章:https://blog.csdn.net/qq_43257914/article/details/134344756?spm=1001.2014.3001.5501
2、Linux版本号
linux内核版本有两种:稳定版、开发版
linux内核版本号由3组数字组成
1、第一组:内核主版本
2、第二组:偶数表示稳定版本、奇数表示开发中版本
3、第三组:错误修补此数
举个例子:linux-4.5.1
4:主版本号
5:此版本号,表示开发中版本(因其为奇数)
1:修订版本号,表示修改次数
3、linux源码架构目录讲解
arch: 不同平台体系相关代码
block: 块设备驱动
certs: 与认证和签名相关代码
crypto: 内核常用加密、压缩算法等代码
Documentation: 描述模块功能和协议规范代码
Driver: 驱动程序(USB总结、PCI总结、显卡驱动等)
firmware目录: 主要是一些二进制固件
fs: 虚拟文件系统代码
include: 内核源码依赖绝大部分头文件
init: 内核初始化代码,联系到内存各组件入口
ipc: 进程间通信实现,比如共享内存、信号量、匿名管道等
kernel: 内核核心代码,包括进程间通信、IRQ、时间等
lib: C标准的子集
mm: 内存管理相关实现
net: 网络协议代码,比如 TCP、IPv6、WiFi、以太网等
samples: 内核示例代码
scripts: 编译和配置内核所需脚本:per/bash 等
security: 内核安全模型相关代码:如 selinux
sound: 声卡驱动源码
tools: 与内核交互
usr: 用户打包和压缩内核的实现源码
virt: /kvm 虚拟化目录相关支持实现