河北京电电力建设有限公司网站怎么根据网站前端做网站后台
论文速读|Rewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning
论文信息:

简介:
这篇论文探讨了如何提升大型语言模型(LLM)在多步推理任务中的性能。具体来说,它试图解决的问题是现有的基于结果的奖励模型(ORMs)在提供反馈时过于稀疏,导致学习效率低下。ORMs仅在推理过程的最终步骤提供反馈,这限制了模型在多步推理任务中的信用分配能力。为了改善这一点,论文提出了一种新的方法,即使用过程奖励模型(PRMs),这些模型在多步推理的每一步都提供反馈,以期提高信用分配的效率。动机在于现有的ORMs在训练大型语言模型时,由于其稀疏的反馈信号,使得模型难以从错误中学习并有效地进行信用分配。这导致了模型在解决复杂问题时的性能受限。为了克服这一限制,作者提出了利用PRMs来提供更密集的反馈,从而在每一步推理中指导模型,使其能够更好地学习和探索,最终提高解决问题的准确性和效率。
论文方法:
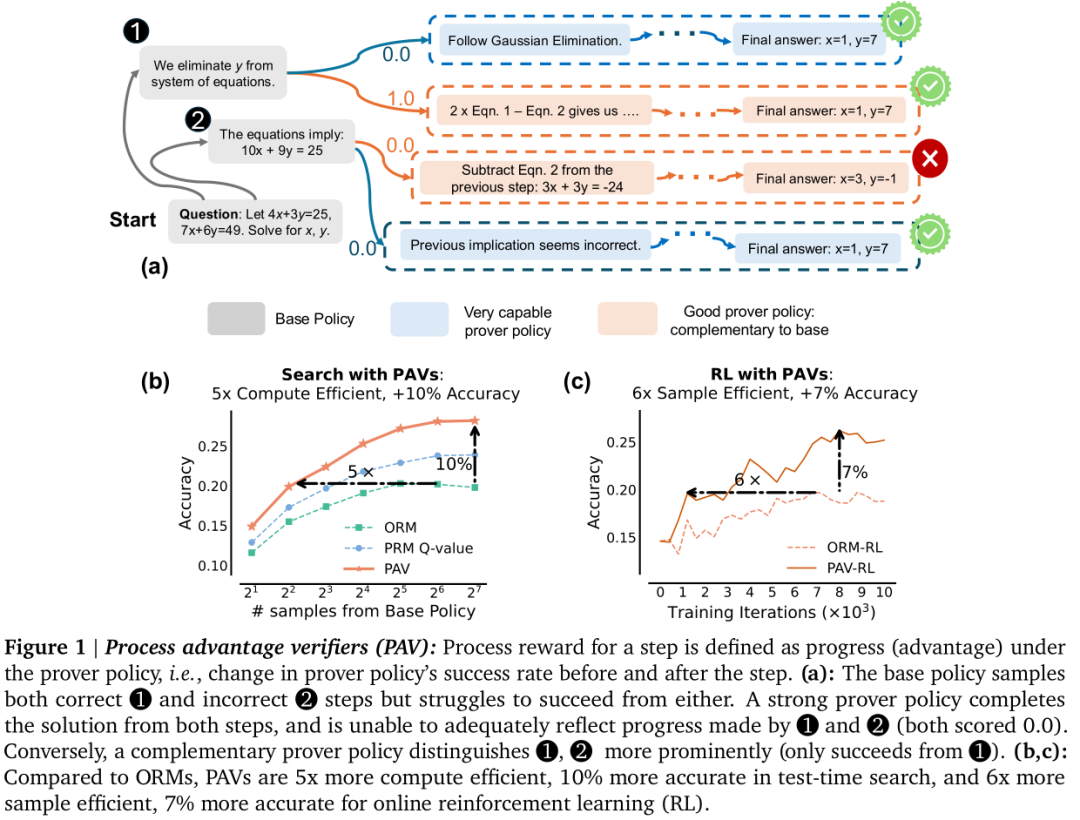
本文提出了一种名为过程优势验证器(Process Advantage Verifiers, PAVs)的方法,用于预测在特定的“证明者”策略下,每一步推理所取得的进展。这种方法的核心思想是,过程奖励应该衡量在执行某一步之后,对未来产生正确响应可能性的变化,即进步的度量。这种进步是在与基础策略不同的证明者策略下测量的。具体来说,作者首先定义了一个好的证明者策略,它应该能够与基础策略互补,即能够区分由基础策略产生的步骤,并且其步骤级别的优势与基础策略相一致。然后,作者通过训练PAVs来预测在这些证明者策略下的优势,并使用这些预测的优势作为过程奖励,结合ORMs的输出奖励,来训练和改进基础策略。
论文实验:
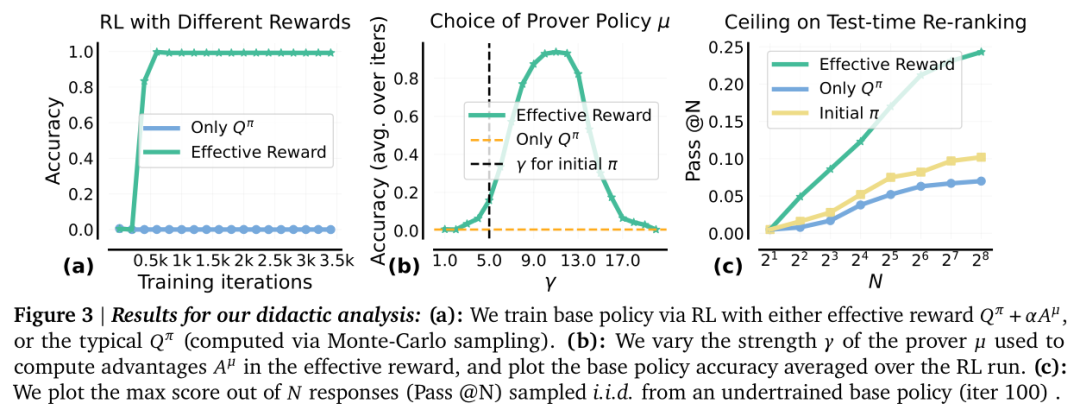
Figure 3 展示了使用过程奖励(PAVs)对于提升基础策略(base policy)在多步推理任务中性能的实验结果。这些实验旨在验证论文中提出的方法是否能够在实际应用中提高推理的准确性和效率。实验比较了仅使用结果奖励(Outcome Reward,ORM)与使用结合了过程奖励和结果奖励的有效奖励(Effective Reward,即 ORM + PAV)对基础策略进行强化学习的效果。结果显示,使用有效奖励(ORM + PAV)的训练方法能够在较少的训练迭代次数内达到更高的准确率,表明该方法能够更有效地利用过程奖励来指导模型学习。
论文链接:
https://arxiv.org/abs/2410.08146
原文来自:
NLP论文速读(谷歌出品)|缩放LLM推理的自动化过程验证器