上海医疗 网站制作云梦网站开发
一、前言
Python爬取二手房数据并保存到Excel表中是一个常见的数据爬取与处理任务。您可以使用Python中的库如Requests、BeautifulSoup来爬取网页数据,再使用Pandas库将数据保存到Excel表中。
爬虫(Web crawler)是一种自动化程序,用于在互联网上按照一定规则抓取信息。它会自动访问网页、提取数据并进行处理,通常用于搜索引擎、数据采集、监控等方面。
爬虫的基本工作流程通常包括以下几个步骤:
-
发起请求:向指定的网页发送HTTP请求。
-
获取响应:接收网页服务器返回的HTTP响应,其中包含网页内容。
-
解析内容:对网页内容进行解析,提取所需的信息,通常使用HTML解析库如BeautifulSoup。
-
孯理数据:对提取的数据进行处理、清洗、存储等操作。
-
循环迭代:根据设定的规则,继续访问其他链接,重复上述步骤。
二、安装对应的库
在Pycharm中下载好相应的库:requests、bs4、BeautifulSoup、pandas等。具体下载方式有三种,这里我只是列出常见的一种,如下效果图:

三、具体数据爬取效果图
以安居客二手房官网为实现对象,爬取某地区二手房的详细情况,这里我爬取金城江(地名)二手房为列效果图如下(仅供参考):
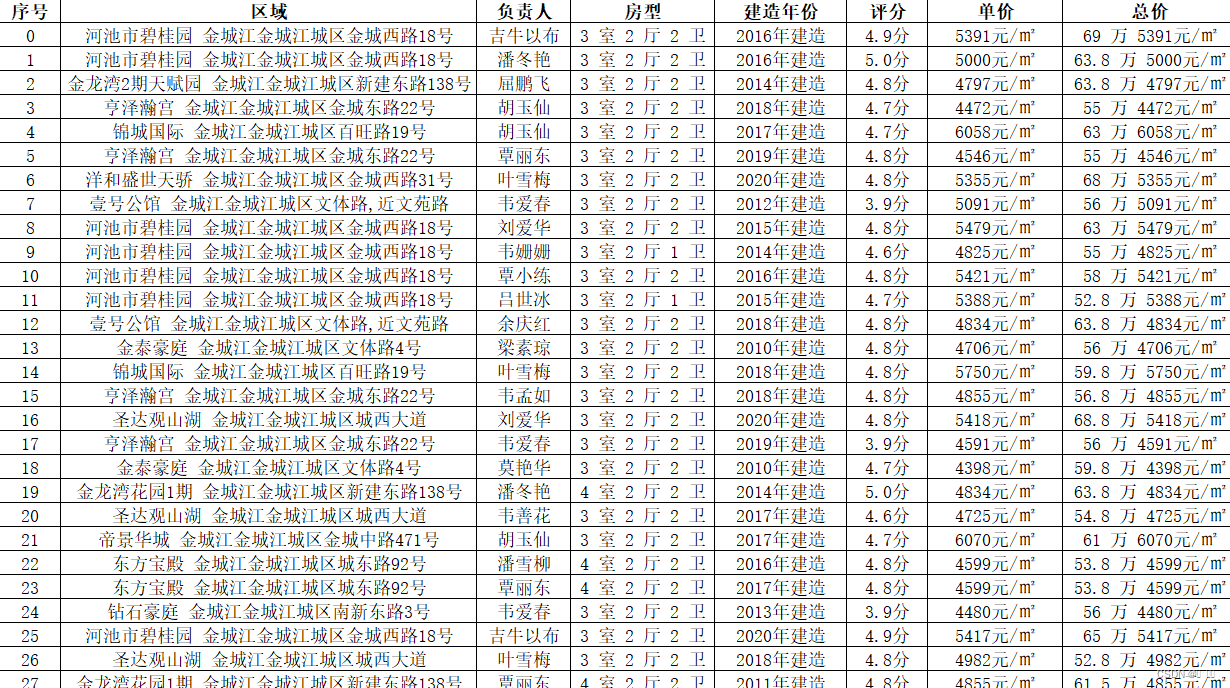
四、实现爬取过程相关数据的代码的截取
首先根据个人的需求来进行相关信息指定的相关官网对象数据的爬取,进入到相对应的官网,这里我进入的官网是安居客二手房:https://hechi.anjuke.com/,选择地址是金城江,所以在爬取的代码的URL为该地址指定的链接:https://hechi.anjuke.com/sale/jinchengjianqu/。相关代码如下:
url = f"https://hechi.anjuke.com/sale/jinchengjianqu{page_number}/"