网站建设策划怎么沟通怀化网站优化公司推荐
最近有位朋友在使用电脑浏览器的时候,遇到了是否停止运行此脚本的问题,不知道如何解决。其实,电脑在使用的时候,经常会出现很多问题的,比如浏览器“是否停止运行此脚本”的问题。下面就来看看详解浏览器提示是否停止运行此脚本的解决方法!

电脑出现提示是否停止运行此脚本怎么办?
方法一:浏览器设置
1、 启动IE浏览器,点击上方菜单栏位的工具。
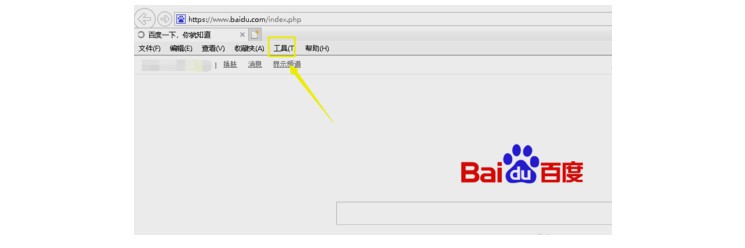
2、 在工具栏位选择internet选项。
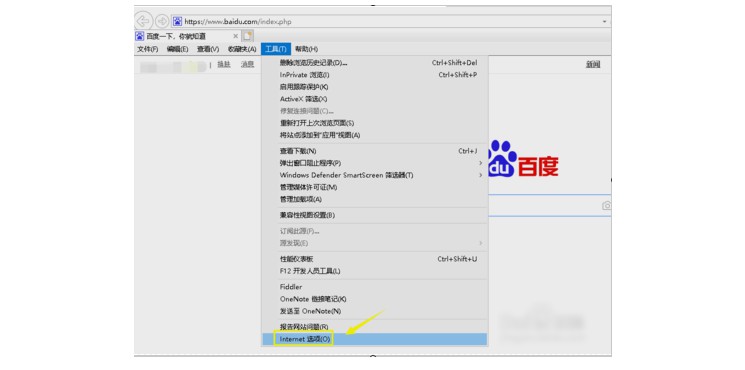
3、 在internet选项卡上点击高级选项卡。
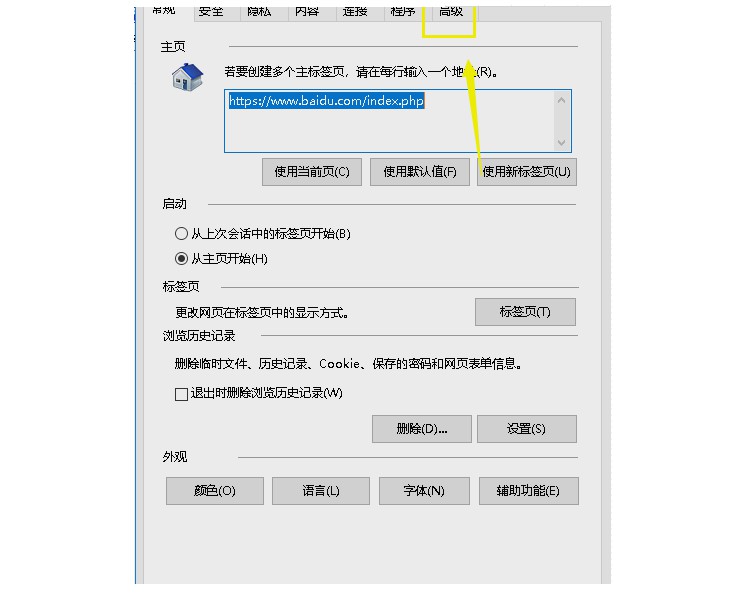
4、 点击下拉高级页面,找到禁用脚本功能选项。
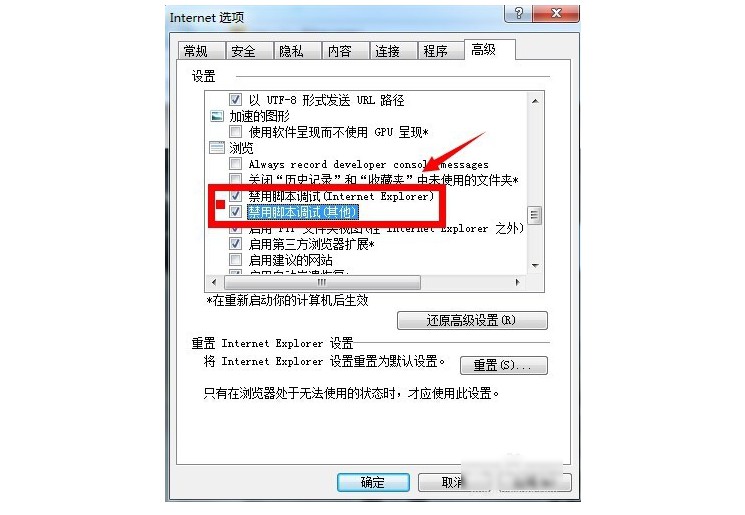
5、 将禁用脚本选项前的勾去掉,点击下方的应用按钮。
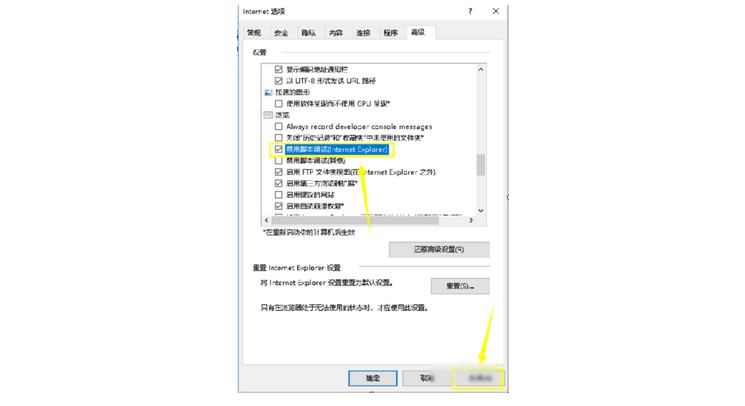
6、 最后,重启浏览器,即可解决浏览器是否停止运行此脚本的问题
方法二:注册表编辑器设置
1、 点击开始菜单中的“运行”,然后输入“Regedit”回车打开注册表编辑器。
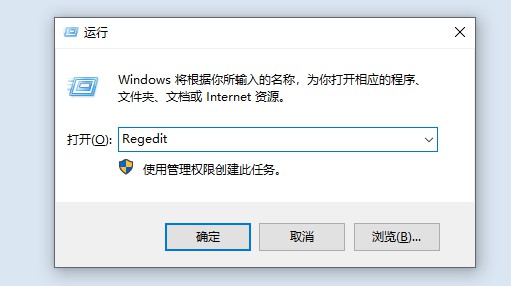
2、 然后,在注册表中定位到以下项:HKEY_CURRENT_USER\Software\Microsoft\Internet Explorer。
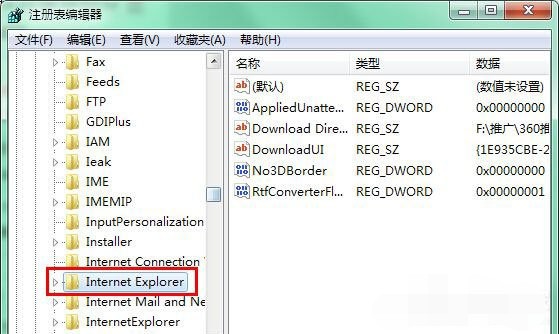
3、 右键点击Internet Explorer项,在菜单中选择“新建-项”,命名为“Styles”。
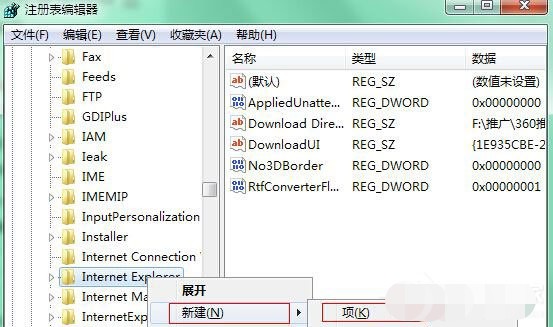
4、 然后选中“Styles”项,在右侧窗口中新建DWORD(32-位)值,并将新建的项目命名为MaxScriptStatements。
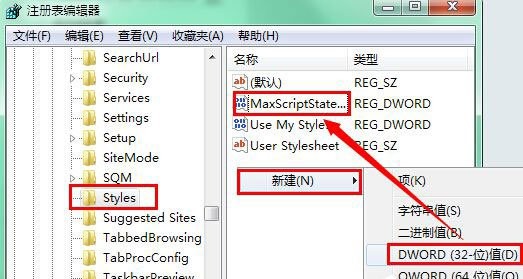
5、 双击MaxScriptStatements,然后将数值数据修改为0xFFFFFFFF,点击确定退出窗口,重启电脑即可。
其实,如果使用IE浏览器打开某些页面时,显示"是否停止运行此脚本",然后浏览器的运行速度会减慢,如果继续运行,您的计算机将停止响应。
方法三:修复浏览器
如果想要自动修复问题,只要下载MicrosoftFixit50403然后再“运行”,并按照修复此问题向导中的步骤执行操作即可。

方法四:重置IE9浏览器
1、 关闭所有Internet Explorer窗口,点击开始,在搜索框内输入inetcpl.cpl,按回车。
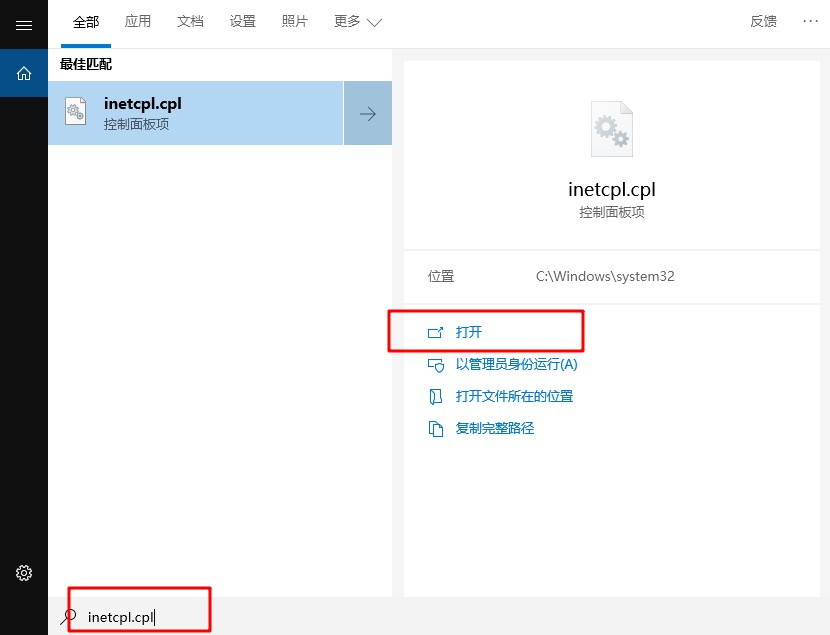
2、 点击高级选项卡,点击重置。
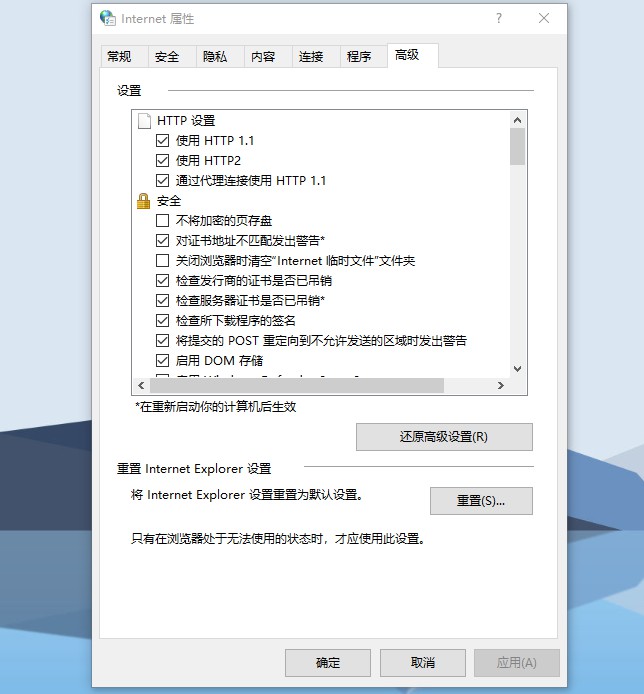
3、 然后,勾选删除个人设置,点击重置。
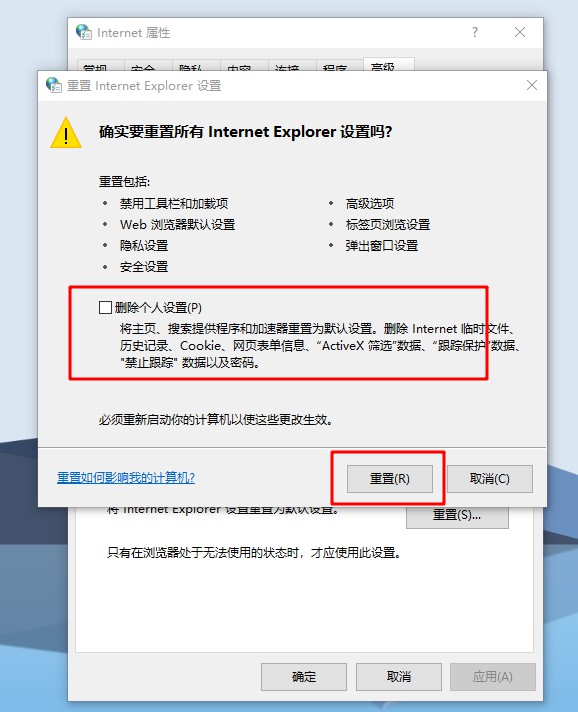
4、 最后,点击关闭,查看浏览器是否还会出现是否停止运行此脚本的提示
方法五:测试加载项
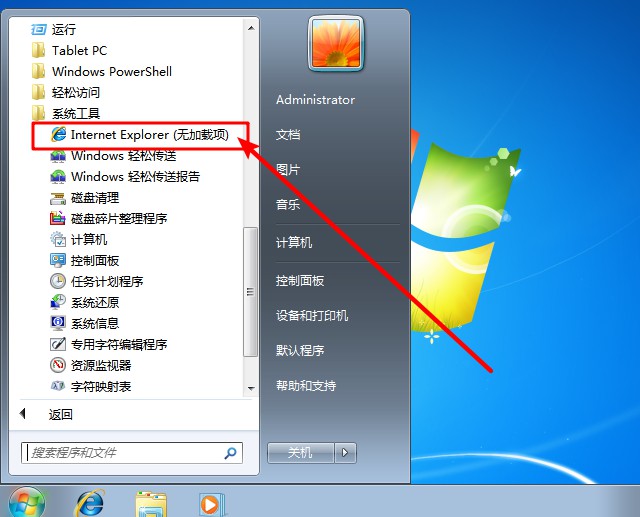
1、 或者,你可以尝试无加载项启动IE9,测试是否是加载项造成了IE9无法正常使用
2、 依次单击“开始”-“所有程序”-“附件”-“系统工具”,然后单击“Internet Explorer (无加载项)”即可
方法六:控制面板设置
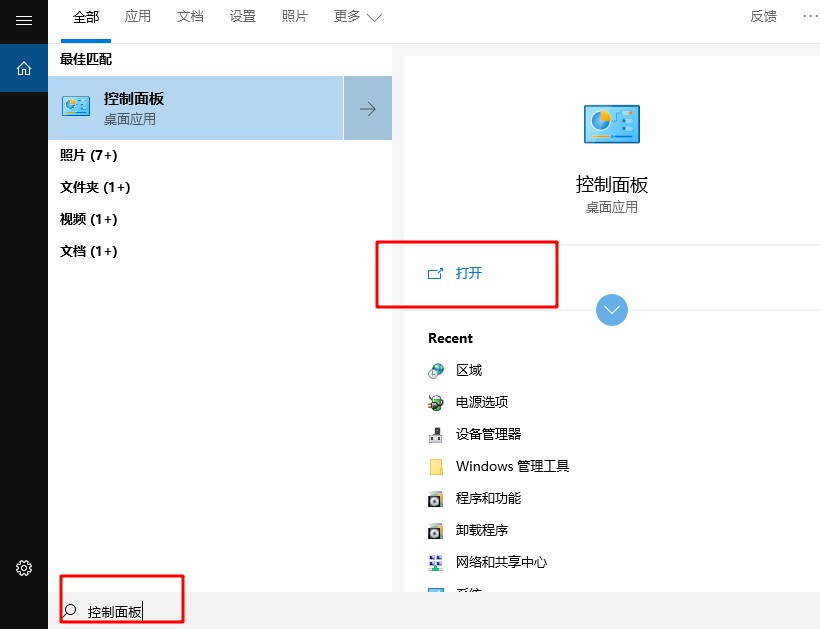
1、 桌面搜索框输入并打开控制面板
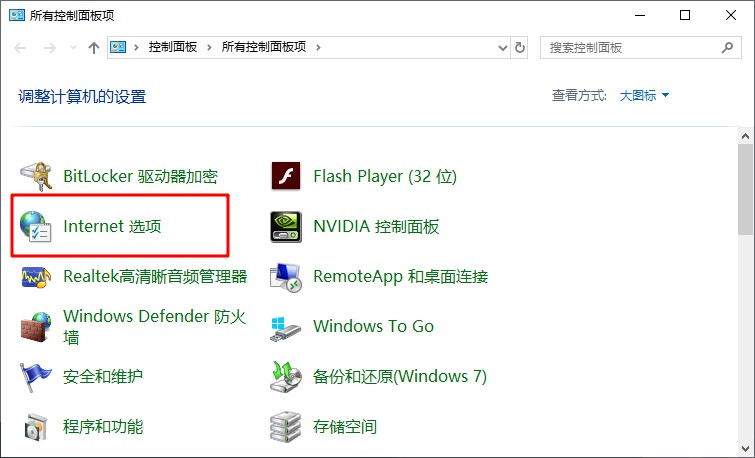
2、 找到并点击Internet选项
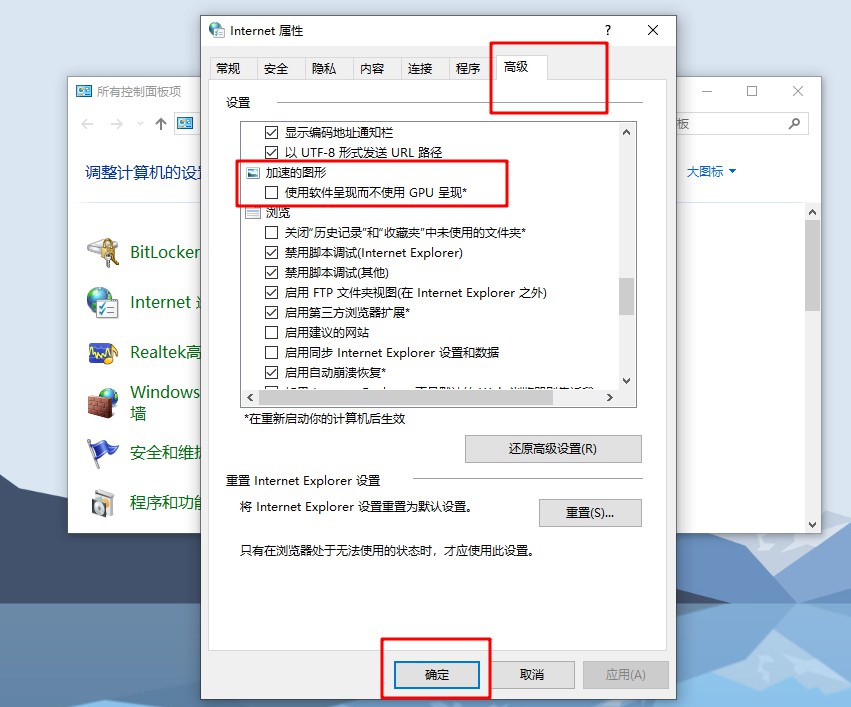
3、 继续点击切换到”高级“选项卡,在”加速的图形“条目下,勾选“使用软件呈现而不使用GPU呈现”即可
4、 以上所有操作完成后,看看还能不能正常使用IE9浏览器
5、
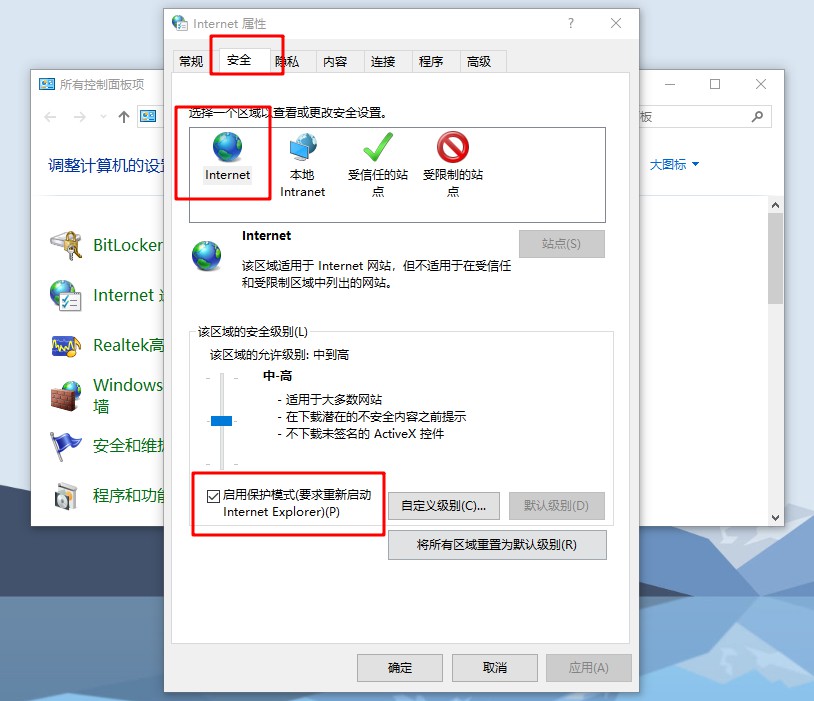
另外,还可以尝试消掉IE9的保护模式,同样点击开始-控制面板-Internet选项后,点击切换到“安全”选项卡,选中上方的Internet图标,将下方的“启用保护模式”的勾取消掉即可
以上就是电脑提示是否停止运行此脚本的6种解决方法。如果你的电脑浏览器也遇到了同样的问题,那么你可以根据实际的情况,来解决浏览器的问题,希望以上方法可以帮助到有需要的朋友。