南阳做网站优化公司网站运营核心
怎么把mkv文件转成mp4格式的方法你知道吗?我想很多朋友会遇到这样的情况,下载视频后发现无法打开。原来我们下载的视频格式是mkv,也许这个格式大家不是很熟悉的。那么今天就来认识一下,mkv是Matroska的一种媒体文件,mkv不同于DivX、XviD等视频编码格式,也不同于MP3、Ogg等音频编码格式,mkv是为这些音、视频提供外壳的“组合”和“封装”格式,换句话说就是一种容器格式,常见的 DAT(是VCD的一种编码格式)AVl、VOB、MPEG、RM 格式其实也都属于这种类型。
虽然打开mkv格式的文件不需要什么特定的播放器,但是还有很多播放器基本都不支持,不过有一些还需要解码分离器插件支持的。那么我们通常把mkv文件转成mp4格式来进行后续的操作,不论是播放或是编辑。那么怎么把mkv文件转成mp4格式的方法有哪些是简单的呢?今天小编就来分享几个方法供大家参考学习啦。
方法一:电脑上使用软件工具【优速视频处理大师】

步骤1:打开电脑,下载并安装优速视频处理大师。您可以在官方网站上下载软件安装包。一定要认准苏州跳跳鱼智能科技开发的产品哦。

步骤2:安装完成后打开软件,在首页选择【格式转换】功能。在此功能下点击左上角的“添加文件”按钮,选择要转换的MKV文件并进行上传。软件支持批量操作,可一次上传多个文件,文件数量不限制,只是处理的时间会相应加长。

步骤3:选择输出文件格式。在下方的输出格式选项中,选择“MP4”作为输出格式。您还可以根据需要选择其他输出选项格式,如FLV、AVI、WEBM等。除此之外还可以设置视频的清晰度、视频画质。视频分辨率。功能还是非常丰富强大的 。

步骤4:点击“开始转换”按钮,软件开始把mkv文件转成mp4格式。等待转换完成后会自动跳出输出文件夹,转换好的文件就保存在里面。

步骤5:查看输出文件夹里的文件,我们可以看到上传的mkv文件都转成mp4格式。而且视频质量没有受到损害,视频处理的又快又好。

通过以上的实际操作,我们发现优速视频处理大师是一款功能强大的视频处理软件,支持多种常见的媒体格式转换,并提供视频剪辑、分割、合并等多种功能。如果您需要进一步了解优速视频处理大师,请访问其官方网站有更多的惊喜哦。
方法二:使用在线工具video2edit
步骤1:打开video2edit应用程序,点击“添加文件”按钮,然后选择要转换的MKV文件。在“输出格式”下拉菜单中,选择“MP4”。

步骤2:配置其他选项(例如,输出文件夹或音频/视频编解码器等)。点击“开始转换”按钮。等待转换完成。转换完成后,您可以在指定的输出文件夹中找到转换后的MP4文件。
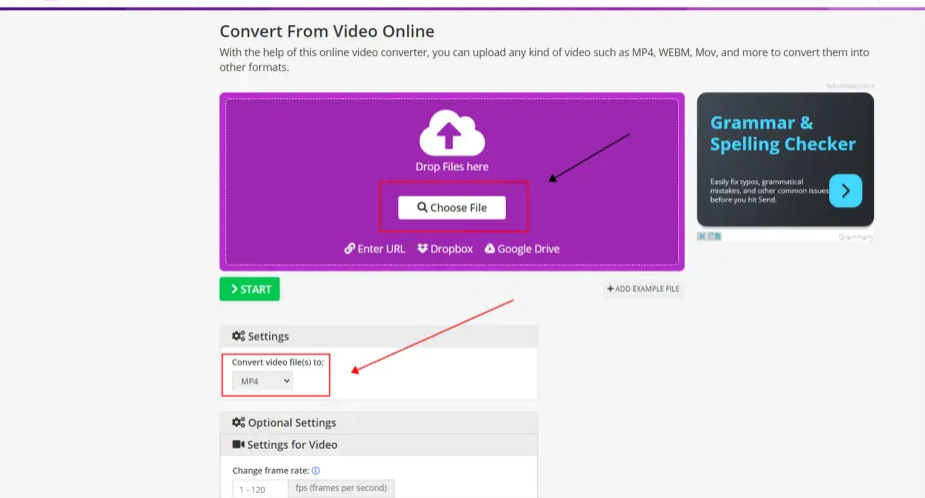
请注意,MKV和MP4都是数字多媒体容器格式,它们可以存储视频、音频、字幕和图像等类型的数据。MKV通常用于存储高质量视频,而MP4经常用于在线视频流媒体。因此,使用video2edit将MKV转换为MP4可能会降低视频质量和观看体验。
方法三:使用MkvToMp4工具
步骤1:下载并安装MkvToMp4软件。打开MkvToMp4软件。点击“Add”按钮,选择需要转换的MKV视频文件。在“Output filename”文本框中设置输出文件名和保存路径。如果您不确定输出格式和编码选项,请保留默认设置。

步骤2:点击“Convert”按钮,开始转换。转换过程可能需要一些时间,具体时间取决于输入文件大小和计算机性能。转换完成后,在指定的输出文件夹中找到转换后的MP4文件。
怎么把mkv文件转成mp4格式的方法小编就选择这么多进行分享了。相信你看了之后就能选择适合自己的。如果你还有其他视频处理需求也可以使用小编推荐的软件进行,因为优速视频处理大师是专业的视频处理软件来的,非常适合职场人来提升自己的工作效率。