在招聘网站做销售建网站卖阀门
目录
- 负数二进制表示
- Java中32位无符号数的取法
- 项目踩坑记录
- Java 0xffffffff隐式类型转换的坑
负数二进制表示
由于计算机中数据都以二进制表示,而负数的二级制是根据正数二进制取补码(补码就是先取反码,然后加1)得到,如:
一个int 类型的数值为5,其长度为32位,二进制表示为
00000000 00000000 00000000 00000101
-5是根据5的二进制表示每一位先取反码(0变1,1变0)得到
11111111 11111111 11111111 11111010
再对反码加1,得到-5的二进制表示
11111111 11111111 11111111 11111011
2、Integer.MAX_VALUE+1 = Integer.MIN_VALUE 与 Integer.MIN_VALUE-1 = Integer.MAX_VALUE
Integer.MAX_VALUE: 01111111 11111111 11111111 111111111: 00000000 00000000 00000000 00000001相加: 10000000 00000000 00000000 00000000
Integer.MIN_VALUE: 10000000 00000000 00000000 00000000
可以看出 Integer.MAX_VALUE+1 结果等于 Integer.MIN_VALUE
Integer.MIN_VALUE: 10000000 00000000 00000000 00000000-1: 11111111 11111111 11111111 11111111相加: 1 01111111 11111111 11111111 11111111
Integer.MAX_VALUE: 01111111 11111111 11111111 11111111
可以看出Integer.MIN_VALUE+1结果将多余位舍去即等于 Integer.MAX_VALUE
https://blog.csdn.net/weixin_39469127/article/details/98526363
Java中32位无符号数的取法
使用 long 型的 64 位十六进制数 0xFFFFFFFFL,对取得的 32 位(4字节)的整型数值,做按位与(&)操作,并以 long 型保存这个无符号数值,如下:long vUnsigned = bf.getInt() & 0xFFFFFFFFL;注:0xFFFFFFFFL 的高32位默认补0,末尾的 L 代表 long 型。注:事实上,Java的 Integer 中已经实现此方法:/*** Converts the argument to a {@code long} by an unsigned* conversion. In an unsigned conversion to a {@code long}, the* high-order 32 bits of the {@code long} are zero and the* low-order 32 bits are equal to the bits of the integer* argument.** Consequently, zero and positive {@code int} values are mapped* to a numerically equal {@code long} value and negative {@code* int} values are mapped to a {@code long} value equal to the* input plus 2<sup>32</sup>.** @param x the value to convert to an unsigned {@code long}* @return the argument converted to {@code long} by an unsigned* conversion* @since 1.8*/public static long toUnsignedLong(int x) {return ((long) x) & 0xffffffffL;}
项目踩坑记录
Agora SDK 对于 UID 的定义如下: JoinChannel
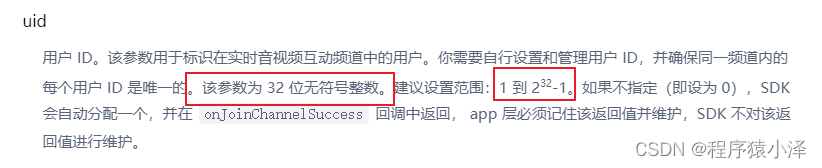
但是在回调中发现UID 为一个负数,与描述(该参数为 32 位无符号整数)不符,这是为什么呢?

原因:
SDK 的 建议 uid 范围(0-232 -1超过了 Java int 的范围 (-231 – 231 -1),所以3944526469 用 -350440827 表示了
解决方案:
如果想UID不出现负值,可以用得到的UID 做如下运算 UID&0xFFFFFFFFL 拿到原始UID
System.out.println(-350440827 & 0xFFFFFFFFL); //3944526469//System.out.println(2337050656& 0xFFFFFFFFL); // error integer number too large
System.out.println((3944526469L & 0xFFFFFFFFL)); //-350440827
System.out.println(-350440827 & 0xFFFFFFFFL); //3944526469
查看 Agora 源码 发现也是用这种方法做的
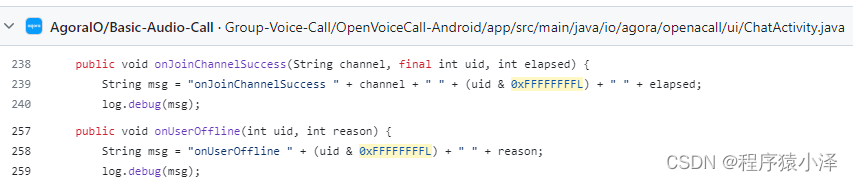
Java 0xffffffff隐式类型转换的坑
long&int最终会将int类型隐式转换成long类型,而0xffffffff的值为-1(java是使用补码存储数值的),在隐式类型转换过程中扩展为long类型-1(0xffffffffffffffff),并不是0x00000000ffffffff。
所以需要将0xffffffff写为0xffffffffL(long类型),这样才能避免隐式转换带来错误的结果。
public static void main(String[] args){long ipLong = 0x457145130A1901F6L;String ip = longToIp(ipLong&0xffffffffL);//取低32位,L表示long类型System.out.println(ipLong);System.out.println(ip);
}public static String longToIp(long longIP){StringBuffer sb=new StringBuffer("");//直接右移24位sb.append(String.valueOf(longIP>>>24));sb.append(".");//将高8位置0,然后右移16位sb.append(String.valueOf((longIP&0x00FFFFFF)>>>16));sb.append(".");sb.append(String.valueOf((longIP&0x0000FFFF)>>>8));sb.append(".");sb.append(String.valueOf(longIP&0x000000FF));return sb.toString();
}补充:整数默认int类型,在big&small表达式中,small为(byte)0xff、(short)0xffff、(int)0xffffffff 的-1隐式转换都会出现此类问题
参考链接:
- https://blog.csdn.net/moakun/article/details/85725236
- https://blog.csdn.net/weixin_39469127/article/details/98526363
- https://blog.csdn.net/weixin_43849277/article/details/108530201
- https://docs-legacy.agora.io/cn/extension_customer/API%20Reference/java_ng/API/toc_core_method.html?platform=Android#api_irtcengine_joinchannel2