网站建设优化是干嘛百度官方网站登录
文章目录
- 一、独立看门狗概述
- 1.1 独立看门狗
- 二、常用寄存器和库函数配置
- 2.1 独立看门狗框图
- 2.2 键值寄存器IWDG_KR
- 2.3 预分频寄存器IWDG_PR
- 2.4 重装载寄存器IWDG_RLR
- 2.5 状态寄存器IWDG_SR
- 2.6 IWDG独立看门狗操作库函数
- 三、手写独立看门狗实验
- 3.1 操作步骤
- 3.2 iwdg.c
- 3.3 iwdg.h
- 3.4 mian.c
一、独立看门狗概述
在由单片机构成的微型计算机系统中,由于单片机的工作常常会受到来自外界电磁场的干扰,造成程序的跑飞,而陷入死循环,程序的正常运行被打断,由单片机控制的系统无法继续工作,会造成整个系统的陷入停滞状态,发生不可预料的后果,所以出于对单片机运行状态进行实时监测的考虑,便产生了一种专门用于监测单片机程序运行状态的模块或者芯片,俗称“看门狗”(watchdog) 。
在启动正常运行的时候,系统不能复位。
在系统跑飞(程序异常执行)的情况,系统复位,程序重新执行。
对于两个看门狗
- STM32内置两个看门狗,提供了更高的安全性,时间的精确性和使用
的灵活性。两个看门狗设备(独立看门狗/窗口看门狗)可以用来检测和
解决由软件错误引起的故障。当计数器达到给定的超时值时,触发一个
中断(仅适用窗口看门狗)或者产生系统复位。 - 独立看门狗(IWDG)由专用的低速时钟(LSI)驱动,即使主时钟发生
故障它仍有效。- 独立看门狗适合应用于需要看门狗作为一个在主程序之外 能够完全独立工
作,并且对时间精度要求低的场合。
- 独立看门狗适合应用于需要看门狗作为一个在主程序之外 能够完全独立工
- 窗口看门狗由从APB1时钟分频后得到时钟驱动。通过可配置的时间窗口
来检测应用程序非正常的过迟或过早操作。- 窗口看门狗最适合那些要求看门狗在精确计时窗口起作用的程序。
1.1 独立看门狗
- 在键值寄存器(IWDG_KR)中写入0xCCCC,开始启用独立看门狗。此时计数器开始从其复位值0xFFF递减,当计数器值计数到尾值0x000时会产生一个复位信号(IWDG_RESET)。
- 无论何时,只要在键值寄存器IWDG_KR中写入0xAAAA(通常说的喂狗), 自动重装载寄存器IWDG_RLR的值就会重新加载到计数器,从而避免看门狗复位。
- 如果程序异常,就无法正常喂狗,从而系统复位。
二、常用寄存器和库函数配置
2.1 独立看门狗框图
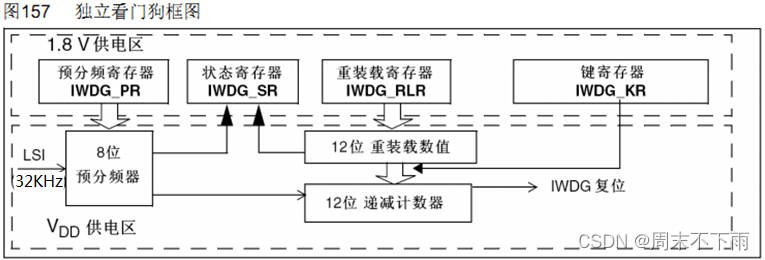
- 键值寄存器IWDG_KR: 0~15位有效
- 预分频寄存器IWDG_PR:0~2位有效。具有写保护功能,要操作先取消写保护
- 重装载寄存器IWDG_RLR:0~11位有效。具有写保护功能,要操作先取消写保护
- 状态寄存器IWDG_SR:0~1位有效
2.2 键值寄存器IWDG_KR
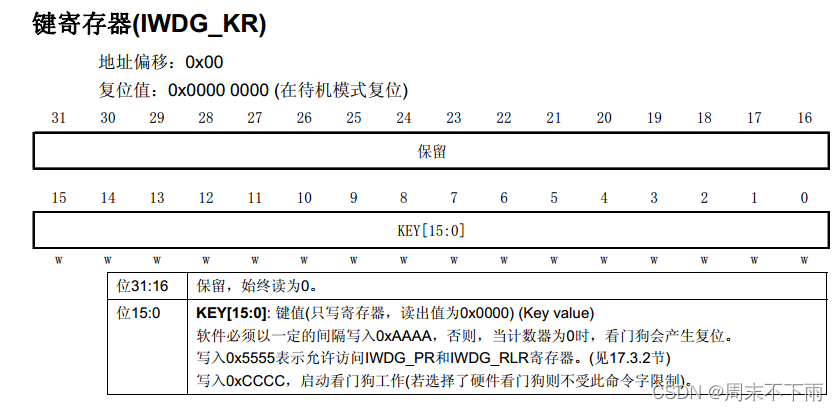
取消写保护,写入
0X5555;启动看门狗,写入0XCCCC;定时喂狗,写入0XAAAA
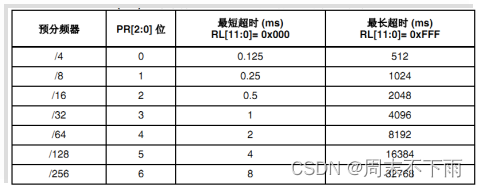
2.3 预分频寄存器IWDG_PR

就是进行分频配置
独立看门狗超时时间
溢出时间计算: Tout=((4×2^prer) ×rlr) /32 (M4)
时钟频率LSI=32K, 一个看门狗时钟周期就是最短超时时间。
最长超时时间= (IWDG_RLR寄存器最大值)X看门狗时钟周期
2.4 重装载寄存器IWDG_RLR
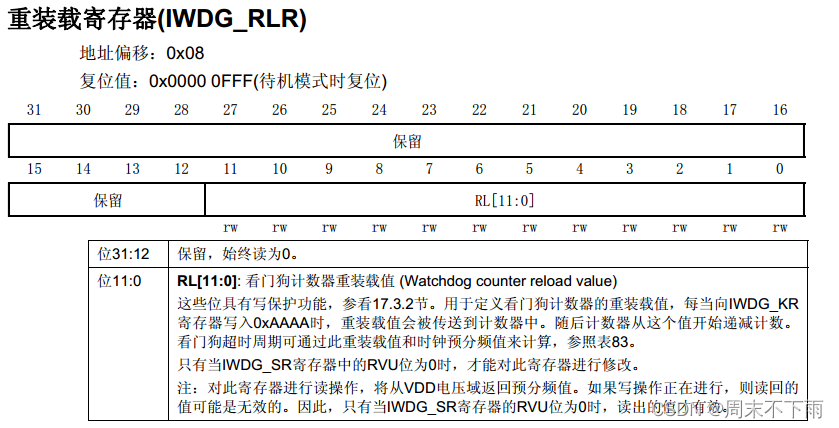
在键值寄存器内写入
0XAAAA,重装载寄存器将进行重装载
2.5 状态寄存器IWDG_SR
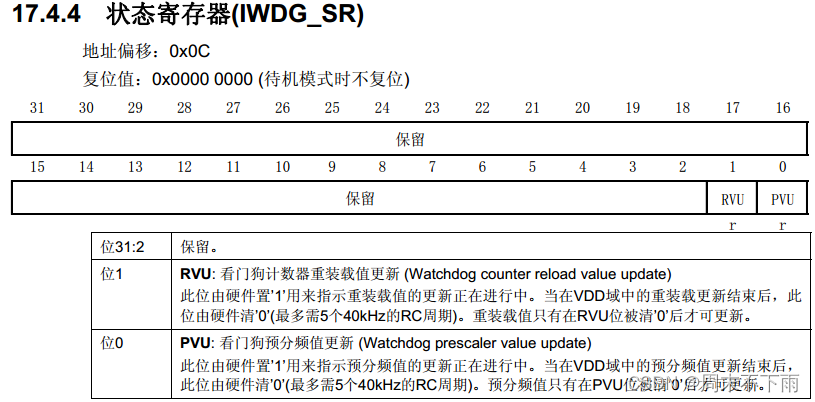
2.6 IWDG独立看门狗操作库函数
void IWDG_WriteAccessCmd(uint16_t IWDG_WriteAccess);//取消写保护:0x5555使能
void IWDG_SetPrescaler(uint8_t IWDG_Prescaler);//设置预分频系数:写PR
void IWDG_SetReload(uint16_t Reload);//设置重装载值:写RLR
void IWDG_ReloadCounter(void);//喂狗:写0xAAAA到KR
void IWDG_Enable(void);//使能看门狗:写0xCCCC到KR
FlagStatus IWDG_GetFlagStatus(uint16_t IWDG_FLAG);//状态:重装载/预分频 更新
三、手写独立看门狗实验
在FWLIB要加入
3.1 操作步骤
取消寄存器写保护:
IWDG_WriteAccessCmd();
设置独立看门狗的预分频系数,确定时钟:
IWDG_SetPrescaler();
设置看门狗重装载值,确定溢出时间:
IWDG_SetReload();
使能看门狗
IWDG_Enable();
应用程序喂狗:
IWDG_ReloadCounter();
溢出时间计算:
Tout=((4×2^prer) ×rlr) /32 (M4)
3.2 iwdg.c
#include "iwdg.h"void IWDG_Init(u8 prer,u16 rlr)
{IWDG_WriteAccessCmd(IWDG_WriteAccess_Enable);IWDG_SetPrescaler(prer);IWDG_SetReload(rlr);IWDG_ReloadCounter();IWDG_Enable();}3.3 iwdg.h
#ifndef __IWDG_H
#define __IWDG_H
#include "sys.h"//prer是预分频系数,rlr重载值
void IWDG_Init(u8 prer,u16 rlr);#endif3.4 mian.c
#include "sys.h"
#include "delay.h"
#include "usart.h"
#include "led.h"
#include "beep.h"
#include "key.h"
#include "iwdg.h"//ALIENTEK 探索者STM32F407开发板 实验3
//按键输入实验-库函数版本
//技术支持:www.openedv.com
//淘宝店铺:http://eboard.taobao.com
//广州市星翼电子科技有限公司
//作者:正点原子 @ALIENTEK int main(void)
{ delay_init(168); //初始化延时函数LED_Init(); //初始化LED端口 BEEP_Init(); //初始化蜂鸣器端口KEY_Init(); //初始化与按键连接的硬件接口delay_ms(500);LED0=0; //先点亮红灯IWDG_Init(4,500); //·/64·分频,0.5KHZ,2ms,所以500个周期,及1秒while(1){if(KEY_Scan(0)==WKUP_PRES){IWDG_ReloadCounter();}delay_ms(10);}}