网站seo基本流程做个小型购物网站要多少钱

和你一起终身学习,这里是程序员Android
经典好文推荐,通过阅读本文,您将收获以下知识点:
一、Service not registered 异常导致手机重启
二、Service not registered 解决方案
一、Service not registered 异常导致手机重启
1.重启 的部分Log如下:
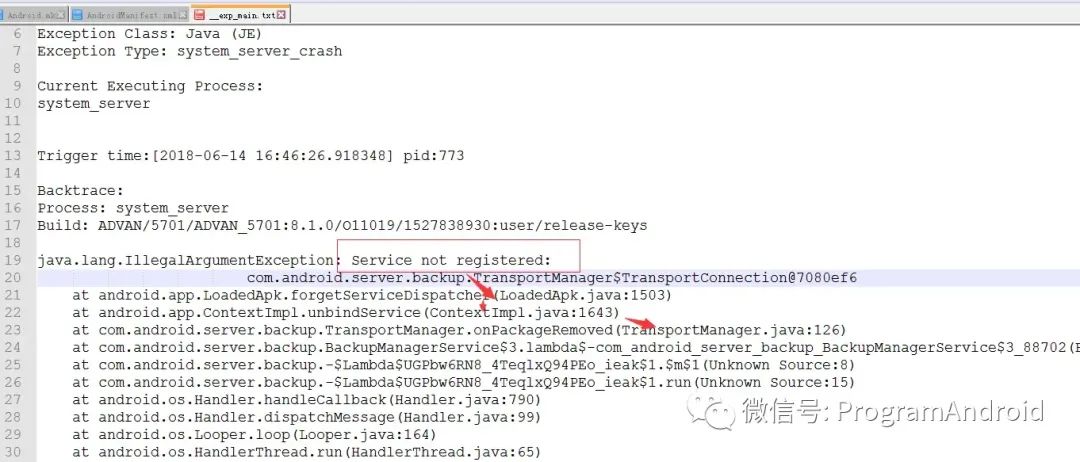
Service not registered 重启异常
二、Service not registered 解决方案
从 Log 中分析发现异常信息,并尝试进行如下修改。
1.修改ContextImpl类
文件路径如下:\frameworks\base\core\java\android\app\ContextImpl.java文件
优化unbindService方法实现如下:
@Overridepublic void unbindService(ServiceConnection conn) {if (conn == null) {throw new IllegalArgumentException("connection is null");}if (mPackageInfo != null) {IServiceConnection sd = mPackageInfo.forgetServiceDispatcher(getOuterContext(), conn);try {ActivityManager.getService().unbindService(sd);} catch (RemoteException e) {throw e.rethrowFromSystemServer();// add for Service not registered unbindService() triger reboot exception} catch (IllegalArgumentException e) {//com.google.android.gms.ui Service not registered Crashandroid.util.Log.e("wjwj","---ContextImpl GMS Crash---");e.printStackTrace();}// add for Service not registered unbindService() triger reboot exception} else {throw new RuntimeException("Not supported in system context");}}2.修改 TransportManager 类
文件路径如下:frameworks\base\services\backup\java\com\android\server\backup\TransportManager.java 将异常捕获,防止重启。
优化unbindService方法实现如下:
void onPackageRemoved(String packageName) {// Package removed. Remove all its transports from our list. These transports have already// been removed from mBoundTransports because onServiceDisconnected would already been// called on TransportConnection objects.synchronized (mTransportLock) {Iterator<Map.Entry<ComponentName, TransportConnection>> iter =mValidTransports.entrySet().iterator();while (iter.hasNext()) {Map.Entry<ComponentName, TransportConnection> validTransport = iter.next();ComponentName componentName = validTransport.getKey();if (componentName.getPackageName().equals(packageName)) {TransportConnection transportConnection = validTransport.getValue();iter.remove();if (transportConnection != null) {/* 360OS begin *//* unbindService() triger reboot exception,* catch it && add log to find out witch package do it. */try {Slog.d(TAG, "onPackageRemoved trace, componentName:"+ componentName.toString(), new Throwable());mContext.unbindService(transportConnection);} catch (IllegalArgumentException e) {Slog.e(TAG, "unbindService fail.", e);}/* 360OS end */log_verbose("Package removed, removing transport: "+ componentName.flattenToShortString());}}}}}参考文献:
【腾讯文档】Android Framework 知识库
https://docs.qq.com/doc/DSXBmSG9VbEROUXF5
友情推荐:
Android 开发干货集锦
至此,本篇已结束。转载网络的文章,小编觉得很优秀,欢迎点击阅读原文,支持原创作者,如有侵权,恳请联系小编删除,欢迎您的建议与指正。同时期待您的关注,感谢您的阅读,谢谢!

点击阅读原文,为大佬点赞!