O2O网站开发工程师视频网站做cpa
一种新型的代理——Autonomous Agents(自治代 理或自主代理), 在 LangChain 的代理、工具和记忆这些组件的支持下,它们能够在无需外部干预的情况下自主 运行,这在真实世界的应用中具有巨大的价值。
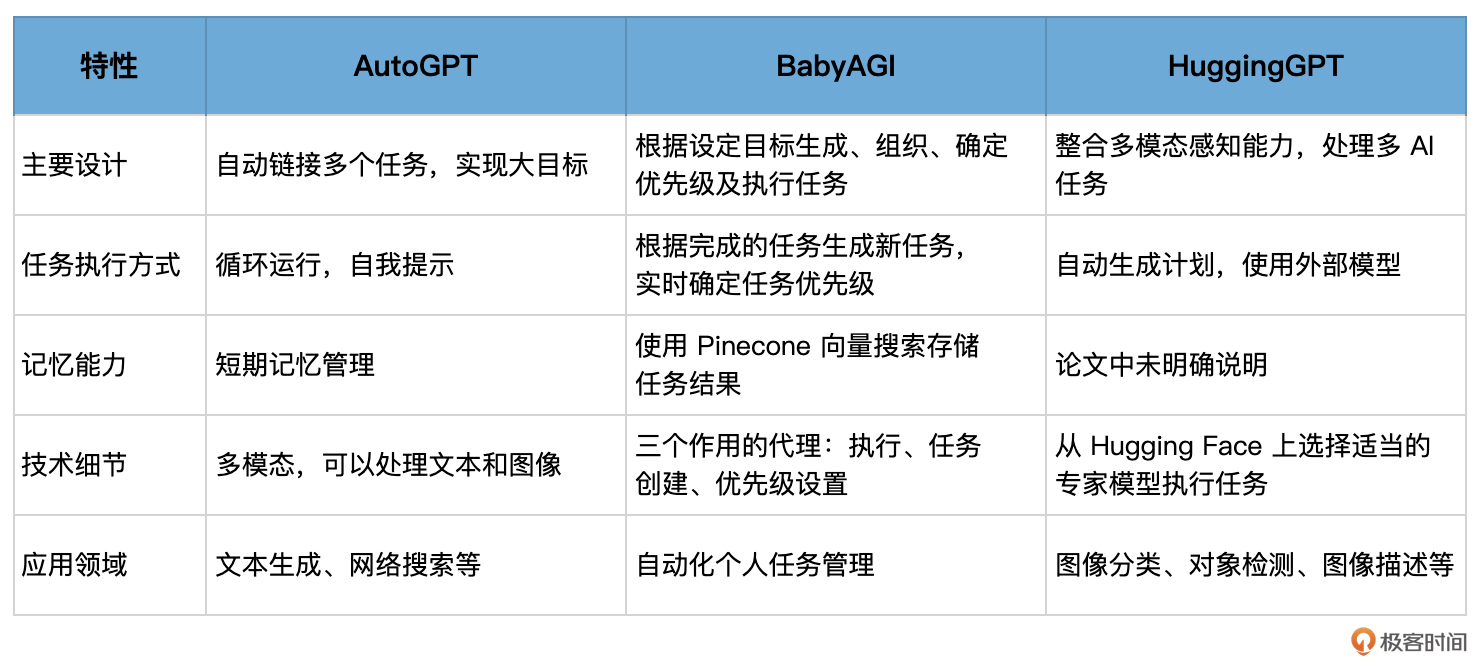
AutoGPT
它的主要功能是自动链接多个任务,以实现用户设定的大目标
用户只需提供一个提示或一组自然语言指令,Auto-GPT 就会通过自动化多步提示过程,将目标分解为子任务,以达到其目标。
技术上,Auto-GPT 使用短期记忆管理来保存上下文;同时 Auto-GPT 是多模态的,可以处 理文本和图像作为输入。
从具体应用上说,Auto-GPT 可以用于各种任务,例如生成文本、执行特定操作和进行网络搜 索等。它还可以作为研究助手,帮助用户进行科学研究、市场研究、内容创建、销售线索生 成、业务计划创建、产品评论、播客大纲制定等。
当然,Auto-GPT 并不完善,作为一个实验性质的项目,它还存在诸多挑战,比如它的运行成 本可能很高,而且它可能会分心或陷入循环。技术上,它的缺陷是没有长期记忆。
Baby AGI
你向系统提出一个目标之后,它将不断优先考虑需要实现或完成的任务,以 实现该目标。具体来说,系统将形成任务列表,从任务列表中拉出优先级最高的第一个任务, 使用 OpenAI API 根据上下文将任务发送到执行代理并完成任务,一旦这些任务完成,它们就 会被存储在内存(或者 Pinecone 这类向量数据库)中,然后,根据目标和上一个任务的结果 创建新任务并确定优先级。 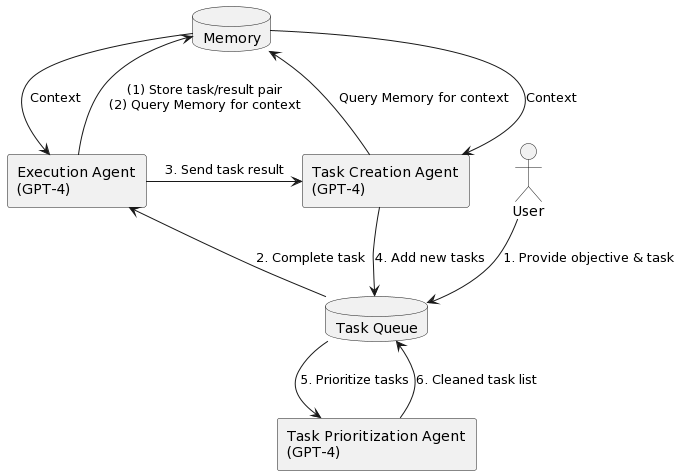
HuggingGPT
HuggingGPT 的工作流程包 括四个阶段
- 任务规划:LLM(例如 ChatGPT)解析用户请求,生成任务列表,并确定任务之间的执行 顺序和资源依赖关系。
- 模型选择:LLM 根据 Hugging Face 上的专家模型描述,为任务分配适当的模型。
- 任务执行:整合各个任务端点上的专家模型,执行分配的任务。
- 响应生成:LLM 整合专家的推断结果,生成工作流摘要,并给用户提供最终的响应。

根据气候变化自动制定鲜花存储策略
我们就解析一下 LangChain 中 BabyAGI 的具体实现
我们导入相关的库
# 设置API Key
import os
os.environ["OPENAI_API_KEY"] = 'Your OpenAI API Key# 导入所需的库和模块
from collections import deque
from typing import Dict, List, Optional, Any
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.embeddings import OpenAIEmbeddings
from langchain.llms import BaseLLM, OpenAI
from langchain.vectorstores.base import VectorStore
from pydantic import BaseModel, Field
from langchain.chains.base import Chain
from langchain.vectorstores import FAISS
import faiss
from langchain.docstore import InMemoryDocstore
初始化 OpenAIEmbedding 作为嵌入模型,并使用 Faiss 作为向量数据库存储任 务信息
# 定义嵌入模型
embeddings_model = OpenAIEmbeddings()
# 初始化向量存储
embedding_size = 1536
index = faiss.IndexFlatL2(embedding_size)
vectorstore = FAISS(embeddings_model.embed_query, index, InMemoryDocstore({}), {})
定义任务生成链,基于给定的条件,这个链可以创建新任务
# 任务生成链
class TaskCreationChain(LLMChain):"""负责生成任务的链"""@classmethoddef from_llm(cls, llm: BaseLLM, verbose: bool = True) -> LLMChain:"""从LLM获取响应解析器"""task_creation_template = ("You are a task creation AI that uses the result of an execution agent"" to create new tasks with the following objective: {objective},"" The last completed task has the result: {result}."" This result was based on this task description: {task_description}."" These are incomplete tasks: {incomplete_tasks}."" Based on the result, create new tasks to be completed"" by the AI system that do not overlap with incomplete tasks."" Return the tasks as an array.")prompt = PromptTemplate(template=task_creation_template,input_variables=["result","task_description","incomplete_tasks","objective",],)return cls(prompt=prompt, llm=llm, verbose=verbose)
定义任务优先级链,这个链负责重新排序任务的优先级。给定一个任务列表,它会返回 一个新的按优先级排序的任务列表。
***************
从结构上看,内容以循环方式进行组织,首先是 TASK LIST(任务列表),接着是 NEXT TASK(下一个任务),然后是 TASK RESULT(任务结果)。
每个任务结果似乎都是基于前一个任务的输出。随着自主代理思考的逐步深入,子任务的重点 从获取当前的天气数据,到确定最佳的花朵储存策略,再到对策略的实际执行和调整。
6 轮循环之后,在任务的最终结果部分提供了具体的步骤和策略,以确保花朵在最佳的条件下 储存。至于这个策略有多大用途,就仁者见仁智者见智了吧。
从目前项目需求的角度来讲,LangChain在企业应用较多的地方还是通过企业内部的文档 资料,开发RAG文档系统,用于资料检索。目前有很多这方面的项目,研究型的,以及企业希望实 际部署的。 从纯AI应用角度,我看到有合作的初创公司在开发基于LLM的个人助理。从产品设计的角度,发布的 App会比单纯使用ChatGPT更方遍,比如说可以根据你手机内的图片自动记账,自动添加行程表什么 的。 很多可能性。同学也可以多参与一些AI的峰会,交流会。看看大家都在用AI和大模型做什么。我也 是管中窥豹。只知一二。