公司网站首页导航html辽中网站建设
反转链表题目描述
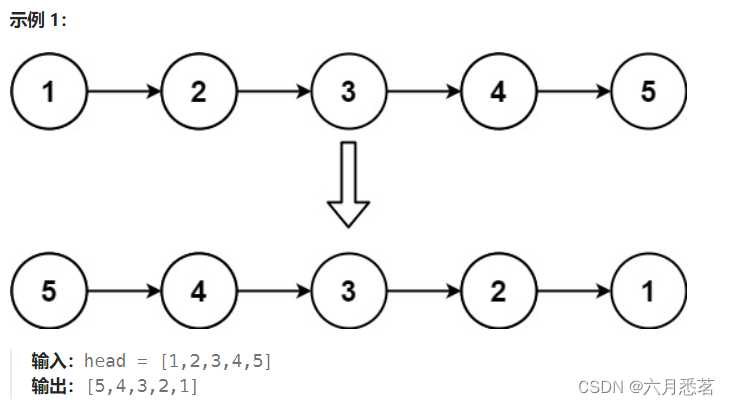
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。

题解1-迭代
假设链表为 1→2→3→∅,我们想要把它改成 ∅←1←2←3。
在遍历链表时,将当前节点的 next 指针改为指向前一个节点。由于节点没有引用其前一个节点,因此必须事先存储其前一个节点。在更改引用之前,还需要存储后一个节点。最后返回新的头引用。
// 函数:反转单链表
struct ListNode* reverseList(struct ListNode* head) {// 初始化前驱节点为 NULLstruct ListNode* prev = NULL;// 当前节点指向头节点struct ListNode* curr = head;// 循环直到当前节点为空(到达链表末尾)while (curr) {// 临时保存当前节点的下一个节点struct ListNode* next = curr->next;// 将当前节点的指针指向前驱节点,完成反转curr->next = prev;// 更新前驱节点为当前节点prev = curr;// 更新当前节点为下一个节点curr = next;}// 循环结束时,prev 指向原链表的尾节点,也就是反转后链表的头节点// 返回 prev,即反转后的链表头节点return prev;
}在上述代码中,prev 并不是直接加入节点的。相反,prev 是用来指向当前节点的前一个节点的。在链表反转过程中,prev 会跟随着 curr 节点向前移动,而 curr 则指向当前正在处理的节点。加入节点的顺序是通过将当前节点的 next 指针指向前一个节点来实现的,从而改变了链表的连接顺序,达到反转链表的效果。
具体来说,在代码中的循环中,每一次迭代都会执行以下操作:
- 将当前节点
curr的下一个节点保存到临时变量next中。 - 将当前节点
curr的next指针指向前一个节点prev,实现了链表节点的反转。 - 更新
prev指向curr,将curr设为下一轮迭代的前驱节点。 - 将
curr设为next,准备处理下一个节点。
通过不断迭代链表,并在每一步中更新指针的指向,实现了链表的反转。这样,循环结束时,prev 指向的是原链表的尾节点,即新的头节点,完成了链表的反转。
题解2递归

// 函数:反转单链表
struct ListNode* reverseList(struct ListNode* head) {// 如果链表为空或者只有一个节点,则直接返回头节点,因为反转后结果不变if (head == NULL || head->next == NULL) {return head;}// 递归调用,反转以头节点的下一个节点为头的子链表struct ListNode* newHead = reverseList(head->next);// 将当前头节点的下一个节点的下一个节点指向当前头节点,实现链表反转head->next->next = head;// 将当前头节点的下一个节点指向 NULL,防止形成环head->next = NULL;// 返回反转后的新头节点return newHead;
}这段代码实现了一个递归方法来反转单链表。它的思路是先递归地反转以头节点的下一个节点为头的子链表,然后将当前头节点的下一个节点的 next 指针指向当前头节点,再将当前头节点的 next 指针指向 NULL,最后返回反转后的新头节点。
这种递归方法的关键是理解递归的调用过程,以及在每一级递归中如何改变链表节点之间的连接关系,从而实现链表的反转。
作者:力扣官方题解
链接:https://leetcode.cn/problems/reverse-linked-list/solutions/551596/fan-zhuan-lian-biao-by-leetcode-solution-d1k2/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。