阿里云申请域名做网站网站开发用qq登录
文章目录
- 1 想法概述
- 2 实际过程
- 阶段1 Add Noise
- 阶段2 Denoise
- 3 数学原理
- 4 为什么推理时要额外加入noise
- 5 一些不知道对不对的Summary
1 想法概述
从一张充满噪声的图中不断denoise,最终得到一张clear的图片。为了确定当前图片中噪声占比的大小,同时输入原图片和参数 t t t,参数 t t t用于标识一张图片中的噪声占比含量。
显然迭代第1次时图片的噪声含量和迭代第999次是不同的,因此需要输入这种信息t来进行标识。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7CjpzYoX-1692290104065)(【Diffusion】李宏毅2023机器学习Diffusion笔记/image-20230814190229199.png)]](https://img-blog.csdnimg.cn/4f4e17d3e69340118b4f01c429735850.png)
2 实际过程
阶段1 Add Noise
首先,准备好一组确定的参数 α 1 ˉ , α 2 ˉ , … , α T ˉ \bar{\alpha_1},\bar{\alpha_2},\dots,\bar{\alpha_T} α1ˉ,α2ˉ,…,αTˉ,用以表示时间步 t t t下样本和噪声的混合情况, t t t越大,噪声占比越高。然后重复以下过程直至收敛:
-
采样
-
从真实样本集中取出一个样本 x 0 x_0 x0
-
从 [ 1 , T ] [1,T] [1,T]的整数中采样出 t t t来表示时间步
-
从标准正态分布中采样出噪声 ϵ \epsilon ϵ
-
-
构造带噪声样本 x = α t ˉ x 0 + 1 − α t ˉ ϵ x=\sqrt{\bar{\alpha_t}}x_0+ \sqrt{1-\bar{\alpha_t}} \epsilon x=αtˉx0+1−αtˉϵ
-
将构造样本 x x x和时间步 t t t一同输入噪声预测器 ϵ θ ( ) \epsilon_\theta() ϵθ(),得到预测噪声 ϵ θ ( x , t ) \epsilon_\theta(x,t) ϵθ(x,t)。
-
目标函数为 ϵ θ ( x , t ) \epsilon_\theta(x,t) ϵθ(x,t)和采样出的真实噪声 ϵ \epsilon ϵ的 M S E MSE MSE
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-D7mqKw6q-1692290104066)(【Diffusion】李宏毅2023机器学习Diffusion笔记/image-20230814194524251.png)]](https://img-blog.csdnimg.cn/c04335120773405a8bdf66cd3009269b.png)
阶段2 Denoise
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-21zUXHgj-1692290104066)(【Diffusion】李宏毅2023机器学习Diffusion笔记/image-20230814201251917.png)]](https://img-blog.csdnimg.cn/31eb1bfa22734d9ba5246a0c317d3e00.png)
3 数学原理
- 极大似然估计近似等价于最小化KL散度(表示两个分布的相似性):
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-S3lKC0VE-1692290104066)(【Diffusion】李宏毅2023机器学习Diffusion笔记/image-20230817221857642.png)]](https://img-blog.csdnimg.cn/f71fb4de1faa4b4080fbadc62dba0b0a.png)
- 对任何分布 q ( z ∣ x ) q(z|x) q(z∣x),有:
log P θ ( x ) ≥ ∫ z q ( z ∣ x ) log P ( z , x ) q ( z ∣ x ) d z = E q ( z ∣ x ) [ log P ( z , x ) q ( z ∣ x ) ] \log P_\theta(x) \ge \int_{z}q(z|x)\log \frac{P(z,x)}{q(z|x)}dz = E_{q(z|x)}[\log \frac{P(z,x)}{q(z|x)}] logPθ(x)≥∫zq(z∣x)logq(z∣x)P(z,x)dz=Eq(z∣x)[logq(z∣x)P(z,x)]
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EMBIDtfT-1692290104067)(【Diffusion】李宏毅2023机器学习Diffusion笔记/image-20230817222057765.png)]](https://img-blog.csdnimg.cn/2383ae51d3b14fff84fbed64cb5fdd62.png)
- 所以对DDPM来说:
log P θ ( x ) ≥ E q ( x 1 : x T ∣ x 0 ) [ log P ( x 0 : x T ) q ( x 1 : x T ∣ x 0 ) ] \log P_\theta(x) \ge E_{q(x_1:x_T|x_0)}[\log \frac{P(x_0:x_T)}{q(x_1:x_T|x_0)}] logPθ(x)≥Eq(x1:xT∣x0)[logq(x1:xT∣x0)P(x0:xT)]
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FqgMWPQQ-1692290104067)(【Diffusion】李宏毅2023机器学习Diffusion笔记/image-20230817222642961.png)]](https://img-blog.csdnimg.cn/d91ef7dc43b54294850f028358d3f1a3.png)
- 结合正态分布的可加性:做N次独立的正态sampling,可能通过一次的sampling就能解决。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oyzChf3t-1692290104067)(【Diffusion】李宏毅2023机器学习Diffusion笔记/image-20230817225900399.png)]](https://img-blog.csdnimg.cn/767e444ef5204f839cc0b930f56e1349.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-w4gtTsG6-1692290104067)(【Diffusion】李宏毅2023机器学习Diffusion笔记/image-20230817231727538.png)]](https://img-blog.csdnimg.cn/bf47251d15fa41589595d129dc70d2a8.png)
- 对式3不断变换,最后可得(这个式子的过程可以不用看,也并不复杂,但是麻烦,理解结论就好):
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SY9fKeIh-1692290104068)(【Diffusion】李宏毅2023机器学习Diffusion笔记/image-20230817232929967.png)]](https://img-blog.csdnimg.cn/f4cea90358114568a48d9426017d81b9.png)
然后再经过一系列的运算求出来 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1|x_t,x_0}) q(xt−1∣xt,x0)依然是高斯分布,表示首尾 x 0 , x T x_0,x_T x0,xT固定住,产生 x t − 1 x_{t-1} xt−1的概率,是一个和network无关的分布。而 P ( x t − 1 ∣ x t ) P(x_{t-1}|x_t) P(xt−1∣xt)是由网络决定的,我们不考虑它的variance,只考虑mean。如果我们希望这两个分布越接近越好,那就想办法让两个分布的mean越接近越好。
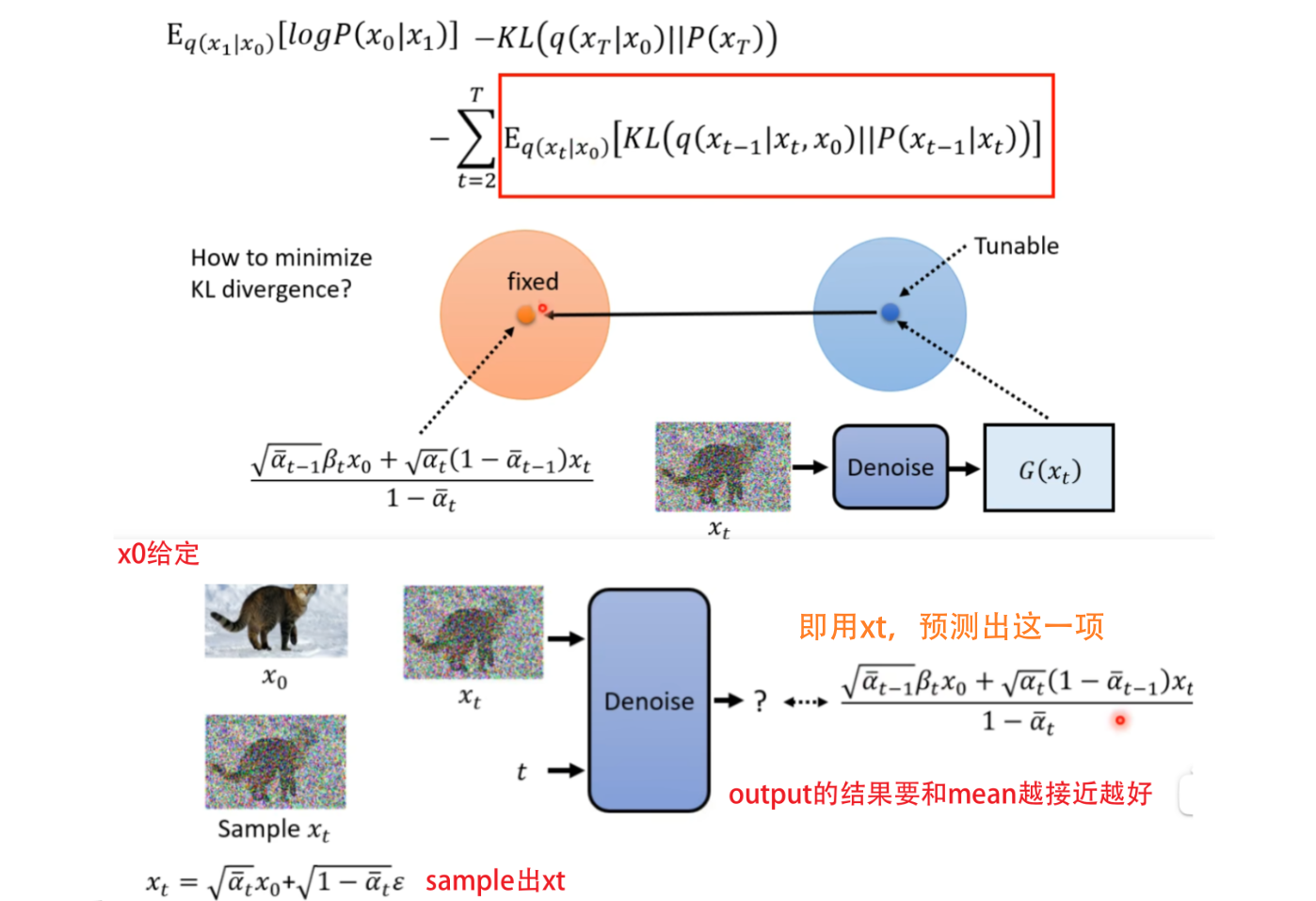
化简:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-B0OFKfc5-1692290104068)(【Diffusion】李宏毅2023机器学习Diffusion笔记/image-20230817233152037.png)]](https://img-blog.csdnimg.cn/94875687bc15457f8d78d4a50400a5d5.png)
实际需要预测出的部分:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OpE6Y02O-1692290104069)(【Diffusion】李宏毅2023机器学习Diffusion笔记/image-20230817234731710.png)]](https://img-blog.csdnimg.cn/058ce2f63eaa42ef97aa502ab8d92950.png)
4 为什么推理时要额外加入noise
李宏毅老师的一点Guess,生成式任务,概率最大的结果,未必就是最好的结果。人写的文章用词可能更suprising。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BxAIdBaQ-1692290104069)(【Diffusion】李宏毅2023机器学习Diffusion笔记/image-20230817235534101.png)]](https://img-blog.csdnimg.cn/2b08a21cf6bb432e806ba75c8e148d30.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-w8wYcaVO-1692290104069)(【Diffusion】李宏毅2023机器学习Diffusion笔记/image-20230817235706919.png)]](https://img-blog.csdnimg.cn/ced2475cfe794eeca024204e5f32ceaf.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vmK39t6D-1692290104069)(【Diffusion】李宏毅2023机器学习Diffusion笔记/ab7e3c6482dc90f4bfc5857991f4375.jpg)]](https://img-blog.csdnimg.cn/41fca1f566d14926833764da62bd92ec.png)
5 一些不知道对不对的Summary
-
希望近似 P d a t a ( x ) P_{data}(x) Pdata(x)和 P θ ( x ) P_\theta(x) Pθ(x)的分布,而对给定的 x x x,使 P θ ( x ) P_\theta(x) Pθ(x)最大化可以转换为使其下界最大化,从而转换为使 E q ( x 1 : x T ∣ x 0 ) [ log P ( x 0 : x T ) q ( x 1 : x T ∣ x 0 ) ] E_{q(x_1:x_T|x_0)}[\log \frac{P(x_0:x_T)}{q(x_1:x_T|x_0)}] Eq(x1:xT∣x0)[logq(x1:xT∣x0)P(x0:xT)]最大化。
-
在假设 x t = β t x t − 1 + 1 − β t z t − 1 x_t=\sqrt{\beta_t}x_{t-1}+\sqrt{1-\beta_t}z_{t-1} xt=βtxt−1+1−βtzt−1的前提下,可以推出 x t = α t ˉ x 0 + 1 − α t ˉ z x_t=\sqrt{\bar{\alpha_t}}x_{0}+\sqrt{1-\bar{\alpha_t}}z xt=αtˉx0+1−αtˉz
-
从而可以进一步化简 E q ( x 1 : x T ∣ x 0 ) [ log P ( x 0 : x T ) q ( x 1 : x T ∣ x 0 ) ] E_{q(x_1:x_T|x_0)}[\log \frac{P(x_0:x_T)}{q(x_1:x_T|x_0)}] Eq(x1:xT∣x0)[logq(x1:xT∣x0)P(x0:xT)]为三项,其余两项与Network无关,可只考虑中间一项,该项由 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1|x_t,x_0}) q(xt−1∣xt,x0)和 P ( x t − 1 ∣ x t ) P(x_{t-1}|x_t) P(xt−1∣xt)的KL散度之和组成,
-
q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t,x_0) q(xt−1∣xt,x0)表示首尾 x 0 , x T x_0,x_T x0,xT固定住产生 x t − 1 x_{t-1} xt−1的概率,可求得是一个和network无关的高斯分布,均值可以表示为:
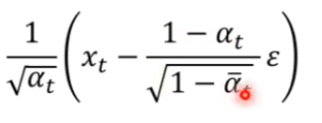
-
而 P ( x t − 1 ∣ x t ) P(x_{t-1}|x_t) P(xt−1∣xt)是由网络决定的,我们不考虑它的variance,只考虑mean。
-
如果我们希望这两个分布越接近越好,那就想办法让两个分布的mean越接近越好。而上式中,仅有 ϵ \epsilon ϵ需要确定,因此我们希望网络能够预测这个值,从而完成推理。预测出这一项 ϵ \epsilon ϵ的过程,可以看作为从 x 0 x_0 x0和 x t x_t xt预测出 x t − 1 x_{t-1} xt−1的过程。