高负载php网站开发长沙开发网站的公司哪家好
文章目录
- Word软件手动安装Zotero插件
- 方法一
- 方法二
- 参考资料
Word软件手动安装Zotero插件
方法一
- 关闭word
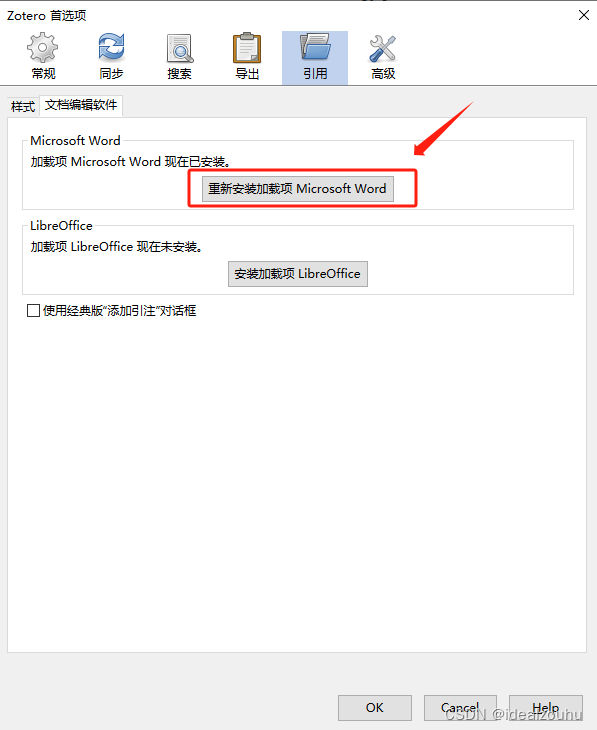
- 在zotero中依次点击
编辑—首选项—引用—文字编辑软件—重新安装加载项Microsoft word
方法二
-
寻找Zotero.dotm存储位置, 例如
D:\Program Files\Zotero\extensions\zoteroWinWordIntegration@zotero.org\install\Zotero.dotm -
Word菜单栏,点击
文件→选项→加载项,管理栏选择模板,然后单击“转到” -
点击
添加, 导入Zotero.dotm模板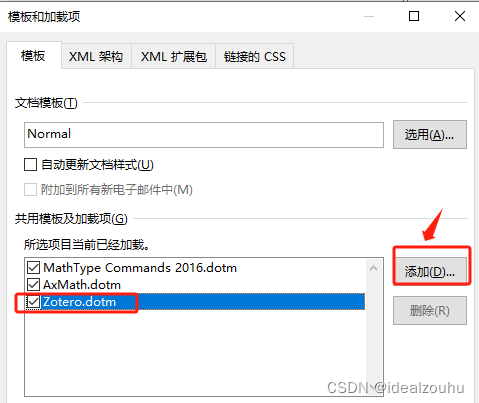
值得注意的是,上面的解决方案每次打开word时都需要重新打开加载项勾选该模板,只能解一时之急;
常驻解决方案:
-
直接将Zotero.dotm文件复制到
C:\Users\用户名\AppData\Roaming\Microsoft\Word\STARTUP。然后,在word加载项里面可以查看加载模板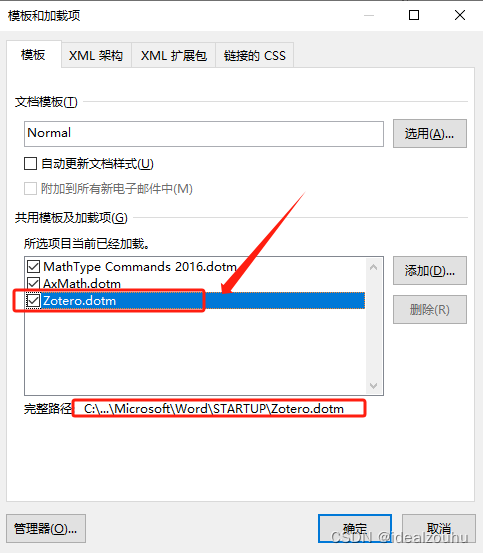
参考资料
如何在Word中手动安装Zotero插件 - 知乎 (zhihu.com)