河南省建设部省厅网站乌市做网站的公司
一、大气
首先和光线追踪类似,大气渲染也有类似的渲染公式,在实际处理中也有类似 Blinn-Phong的拟合模型。关键参数是当前点到天顶的角度和到太阳的角度

二、大气散射理论
光和介质的接触:
- Absorption 吸收
- Out-scattering 散射
- Emission 自发光
- In-scattering 其他介质的光散射过来
四种方式累积起来形成RTE公式

体渲染公式:其实就是RTE公式的导数
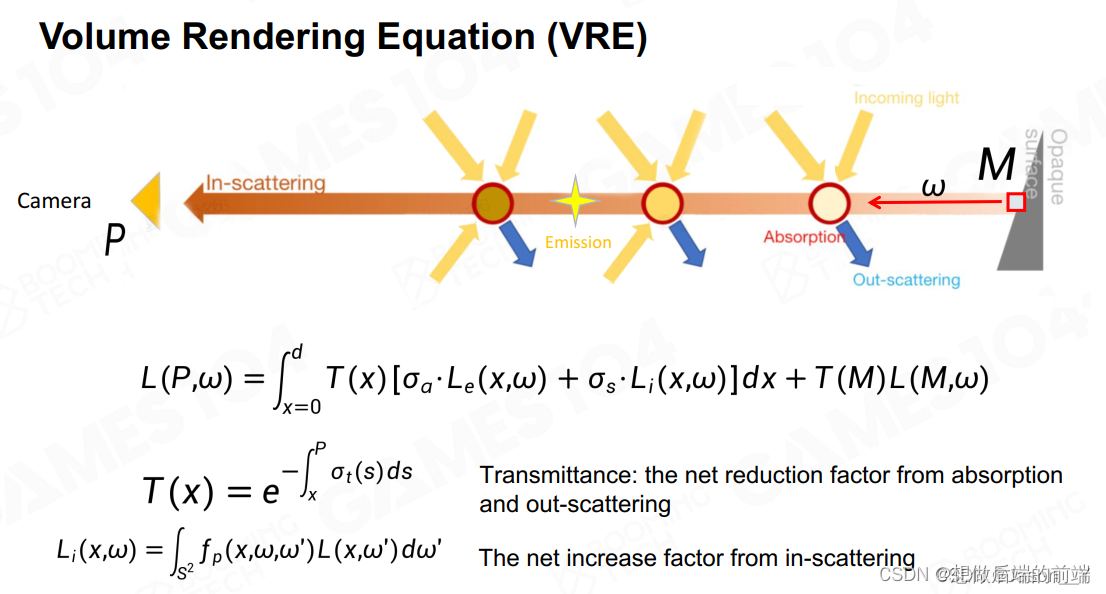
2.1 大气中的真实物理
大气中真实存在两种介质:气体分子和气溶胶分子,前者往往小于太阳光中各种光的波长,而后者一般接近这些波长。
因此散射也分为了两种:
2.2 散射
Rayleigh Scattering(瑞利散射)
当空气中介质尺寸远小于波长的时候(气体分子):
空气中的光是四面八方均匀散射,不太具有方向性
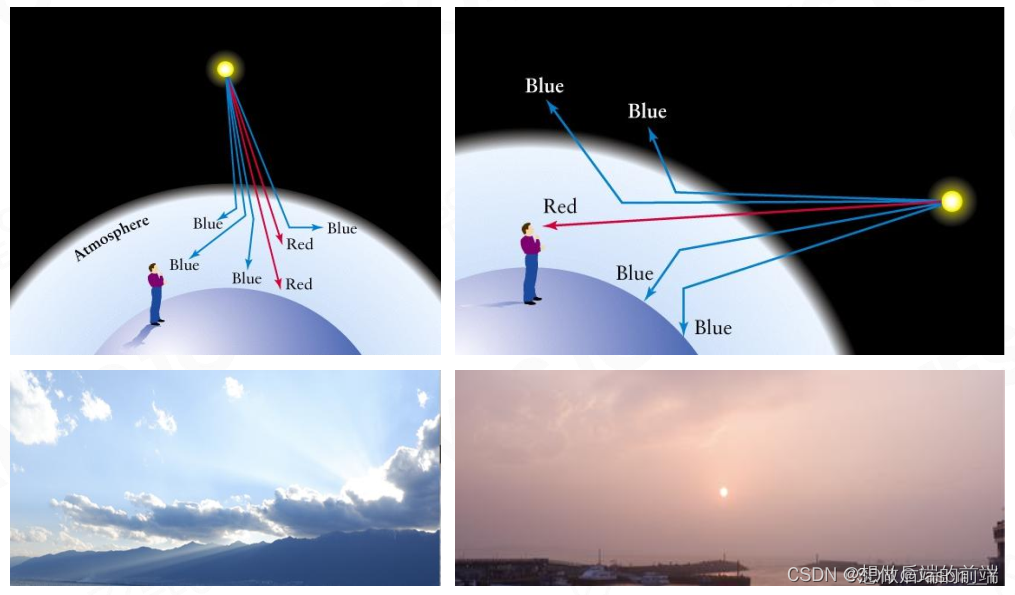
对于越短的波长(蓝紫光),它散射的越远,对越长的波长(红光),散射的越近
详细来说,其散射公式如下:

其中θ是光散射出去的方向和入射角之间的角度,n是空气折射率。而密度比。ρ \rhoρ 这个数字在海平面上等于1,随ρ ( z ) = exp − h / H \rho(z) = \exp{-h/H},ρ(z)=exp−h/H 呈指数递减
几何部分决定了不同方向光的散射情况不同(但整体差别不太大,而且旋转不变);波长部分表明波长越短,散射越强;密度部分表明了海拔对散射的影响。
这也解释了天空在白天是蓝色在傍晚是偏红的原因:
Mie scattering(米氏散射)
当空气中介质尺寸接近或大于波长时(气溶胶):
- 有一定方向性
- 对波长不敏感
详细来说,其散射公式如下:
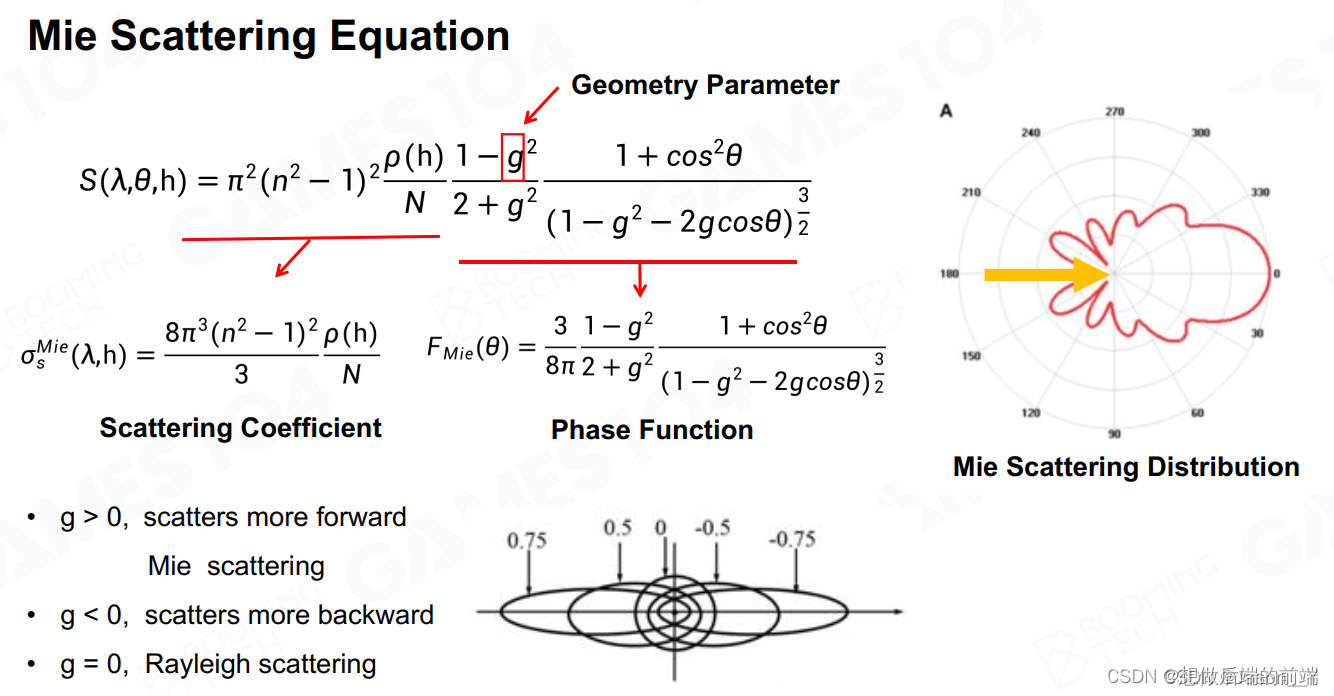
对比瑞利散射,多了几何参数g的影响。
其实际生活影响就是雾和太阳光环:

2.3 吸收
空气中主要是臭氧和甲烷能够吸收波长的光,比如臭氧吸收红橙黄,甲烷吸收红光。比如海王星上大量甲烷导致其显现蓝色。
实际计算过程中往往假设这些气体是均匀分布在整个大气中的(虽然实际上并不是,比如臭氧集中在大气上层)
三、实时大气渲染

3.1 预计算LUT
实际计算时,Ray Marching是最常用的方法。其原理主要是依照路径逐步计算累积,如下图:
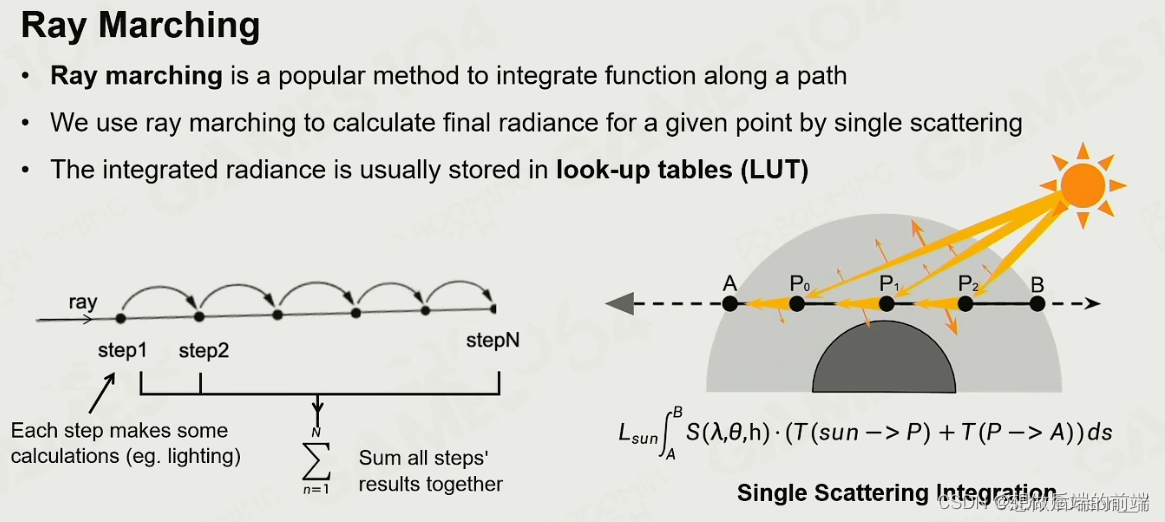
其中T就是所谓通透度(密度)
和普通物体的实时渲染类似,预计算也在该领域得到运用,LUT就是一个将许多复杂计算进行预计算保存下来的表格。在通透度方面,一个公式得以提出:
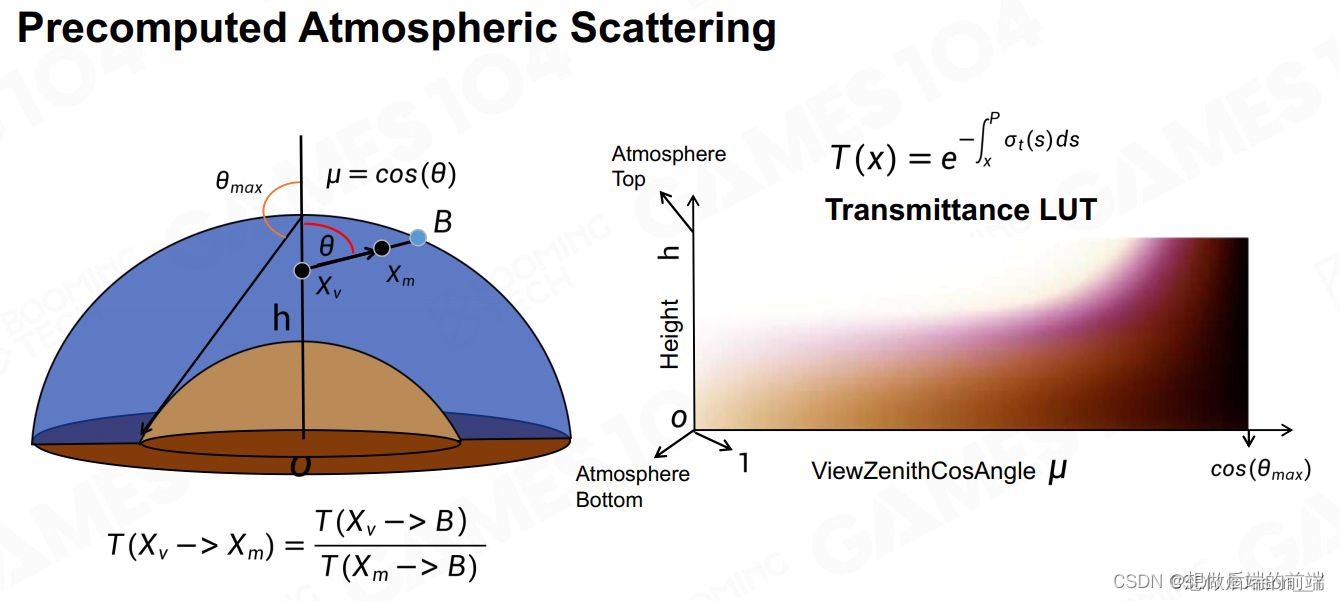
我们注意到,两个点之间的通透度关系借此只由两个参数决定( h 和 θ )由此,我们可以得到一个关于传播通透度的LUT表。
提出这个公式之后,原来的单次散射公式就可以表示为:
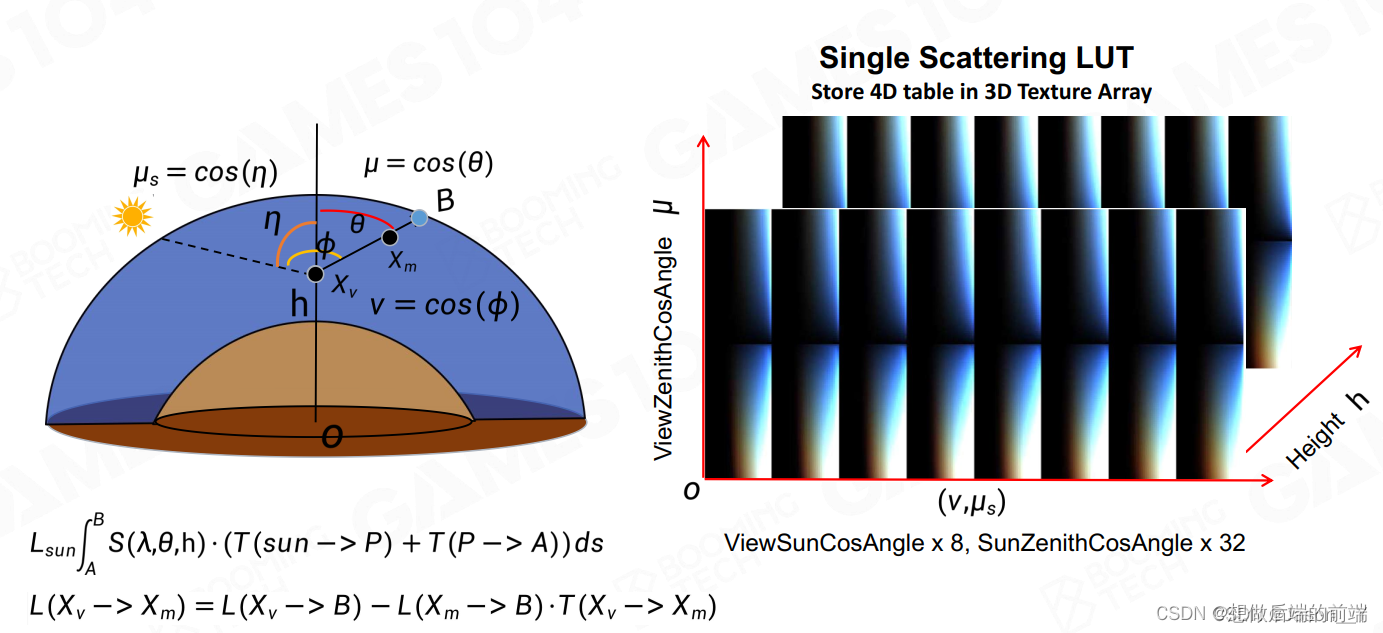
这里最重要的是一种参数化思想(和上面一样),利用三个参数 η 太阳顶角)、θ (观察顶角)和 ϕ (太阳到观察视角之间水平角度)再加上当前高度 h 表示站在所有点在所有太阳角度下看任何方向的情况。(这三个角都是方位角并进一步通过cos计算得到相应结果( μ s 、μ 以及 v )。我们将这个4D表示存到多个3Dtexture array(其实3D texture的插值更合理)里面方便查询。
因此,我们获得了通透度LUT表和单次散射LUT表,利用这两张表,就可以计算出二次、三次以及更多次散射的LUT表
缺点:
- 预计算成本很高。首先是多次散射的迭代计算成本高,其次是在移动端没法用。(即使在PC端可能也有很多毫秒甚至一秒,但可能分到很多帧去完成)
- 没法处理动态环境调整。比如从晴天变成下雨的雾天,此时需要均匀过度,每一帧都要插值计算,所以没法处理。包括艺术家调节参数也不方便
- 虽然获得预计算表,但单单是去逐像素进行高维的插值查询也是成本很高的(所以经常需要为了效率去下采样)
3.2 简化版
因为上述缺点,一种更简化的多次散射方案被提出,其特点在于认为任何散射都是各向同性的,向所有方向均匀散射,所以对一个介质来说,其所有邻居介质收到来自它的散射能量都是相同的,因而一次散射带来的结果只是整体削减(吸收)了固定百分比。
在这种设定下,多次散射也就单纯变成了一次散射的指数变化(等比数列),而一个介质收到的不同次数的散射总量就是其求和(等比数列求和)。
这样一来,由于极大加快了速度,所以这种方法可以每一帧都进行计算。从而导致原方法LUT参数中的高度 h 以及太阳顶角 η都不需要参与预计算(因为都实时更新了),所以新方法的LUT表中只需要计算出观察的天顶角 θ 和一个水平方向环绕360度的夹角 ϕ (对应原来太阳到观察视角水平方向的夹角)即可。化四维为二维。
再加入相机距离可以进一步获得3D的LUT表来实现ray marching

四、云的渲染

Billboard Cloud:

Volumetric Cloud Modeling

云渲染从最早学术界的Mesh方法到早起游戏的单纯叠贴图,逐渐发展到了用于3A行业的Volumetric Cloud Modeling。其本身有各种优点:
- 真实的云的形状
- 可以实现大尺寸的云
- 支持动态天气
- 支持动态的体积光照和阴影
同时也具有一个明显的缺点:
- 效率低下,成本昂贵
- 其具体依赖于一个称为Weather Texture的东西,而它由两个部分组成:
天空中云的随机分布:

- 云的厚度(从0到1表示)
- 利用这两个部分就可以实现比如云的移动(对1进行平移)以及厚度变化等
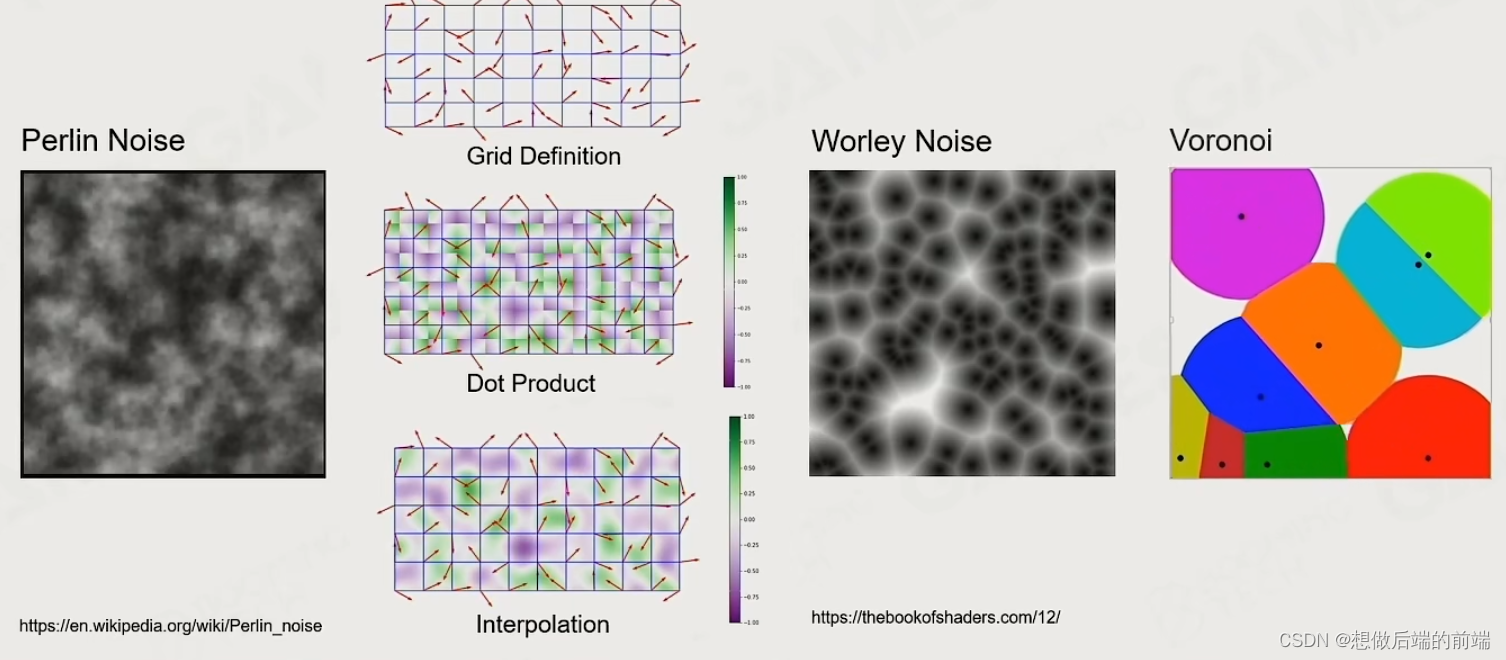
但是单单这样做会导致云的形状变成柱状,所以引入了Noise,比如Perlin Noise(棉絮状噪声)和Worley Noise(细胞结构状)等,先利用低频把云的规则边缘模糊化,再加上一些高频来优化细节。
实际如何进行渲染呢?Ray Marching。具体来说分四步:
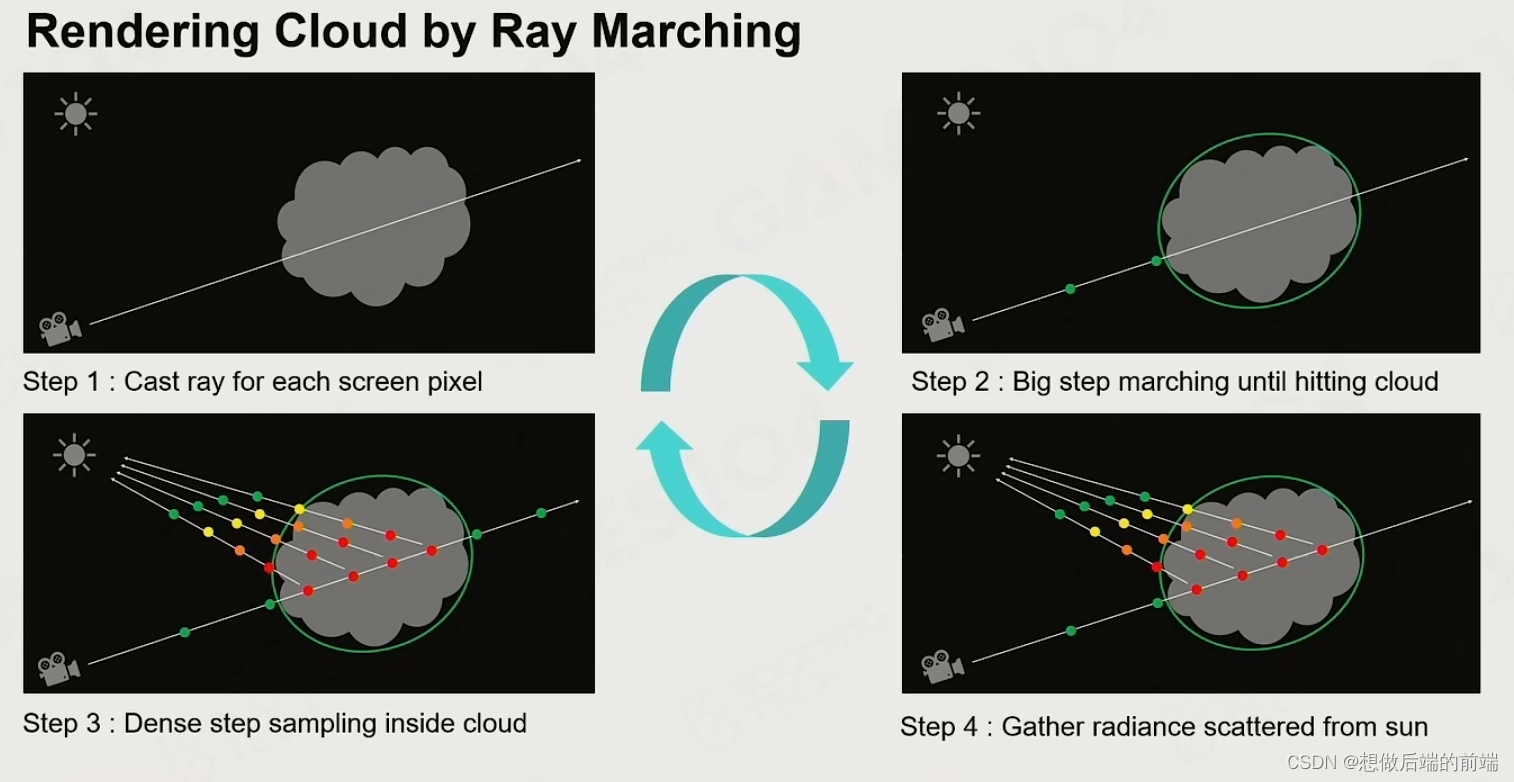
- 对每个屏幕像素做射线
- 在该射线未接触到任何云之前大步前进
- 碰到云之后密集计算
- 利用前述方法计算,但进行简化(因为云比较密,所以可以做这个假设)