网站开发部门叫什么win7下使用wordpress

目录
一、概述
( 1 ) 介绍
( 2 ) 关联关系映射
( 3 ) 关联讲述
二、一对一关联映射
2.1 数据库创建
2.2 配置文件
2.3 代码生成
2.4 编写测试
三、一对多关联映射
四 、多对多关联映射
给我们带来的收获
一、概述
( 1 ) 介绍
关联关系映射是指在数据库中,通过定义表之间的关联关系,将多个表的数据进行关联查询和映射的过程。通过关联关系映射,可以方便地获取相关联表的数据,并将其映射到对应的实体类中。
Mybatis是一种Java持久层框架,它提供了一种将数据库表和Java对象之间进行关联关系映射的方式。在Mybatis中,可以通过配置文件或注解的方式,定义表之间的关联关系,并将查询结果映射到对应的Java对象中。通过Mybatis的关联关系映射,可以方便地进行复杂的数据库查询操作。
在Mybatis中,可以通过配置映射文件来实现关联关系的映射。通过定义实体类和映射文件,可以将数据库中的多个表进行关联查询,并将查询结果映射到实体类的属性上。
在进行数据库查询操作时,通过关联查询获取到关联表中的相关数据,并将其映射到实体类中的关联属性上。
总结来说,关联关系映射是指通过配置映射文件,将数据库中的关联表进行关联查询,并将查询结果映射到实体类的关联属性上。通过扩展关联关系映射,可以方便地进行复杂的数据库查询操作,提高查询效率和简化数据操作的代码。
( 2 ) 关联关系映射
关联关系映射在Mybatis中主要通过三种方式实现:一对一关联和一对多关联及多对多关联。
一对一关联:
在一对一关联中,两个表之间存在一对一的关系,例如学生表和身份证表,一个学生只有一个身份证,而一个身份证也只属于一个学生。在Mybatis中,可以通过在实体类中定义关联属性,然后在映射文件中使用<association>标签来定义关联关系。通过配置映射关系,可以查询到学生表和身份证表的数据,并将其映射到对应的实体类中。
一对多关联:
在一对多关联中,两个表之间存在一对多的关系,例如部门表和员工表,一个部门可以有多个员工,而一个员工只属于一个部门。在Mybatis中,可以通过在实体类中定义关联属性,然后在映射文件中使用<collection>标签来定义关联关系。通过配置映射关系,可以查询到部门表和员工表的数据,并将其映射到对应的实体类中。
多对多关联:
是指两个表之间存在多对多的关联关系,即一个表的一条记录可以对应另一个表的多条记录,反之亦然。在数据库中,多对多关系通常需要通过中间表来实现。
在Mybatis中,可以通过定义中间表来映射多对多关系。假设有两个表,学生表和课程表,一个学生可以选择多门课程,而一门课程也可以被多个学生选择。为了映射这种多对多关系,需要创建一个中间表,例如选课表,用来记录学生和课程的关联关系。
( 3 ) 关联讲述
在关联关系映射中,还可以使用嵌套查询和延迟加载等技术来优化查询性能。嵌套查询是指在查询主表数据时,同时查询关联表的数据;延迟加载是指在需要使用关联数据时才进行查询,避免一次性查询所有关联数据。这些技术可以根据具体需求进行配置和使用。
在进行关联关系映射时,可以使用不同的标签来配置不同的关联关系,如<association>标签用于一对一关联,<collection>标签用于一对多关联。通过配置映射关系,可以根据具体需求查询到相关的数据,并将其映射到实体类中。
总结来说,关联关系映射是Mybatis中非常重要的特性之一,关联关系映射是指通过配置映射文件,将数据库中的关联表进行关联查询,并将查询结果映射到实体类的关联属性上。通过扩展关联关系映射,可以方便地进行复杂的数据库查询操作,也方便地进行表之间的关联查询和映射操作,提高了数据查询和操作的灵活性和效率及简化数据操作的代码。
二、一对一关联映射
这里进行一对一关联关系实例演示
这里的代码基于我博客文章中的 : Spring与Mybatis集成且Aop整合
2.1 数据库创建
创建名为 t_hibernate_book (书籍表) 数据表
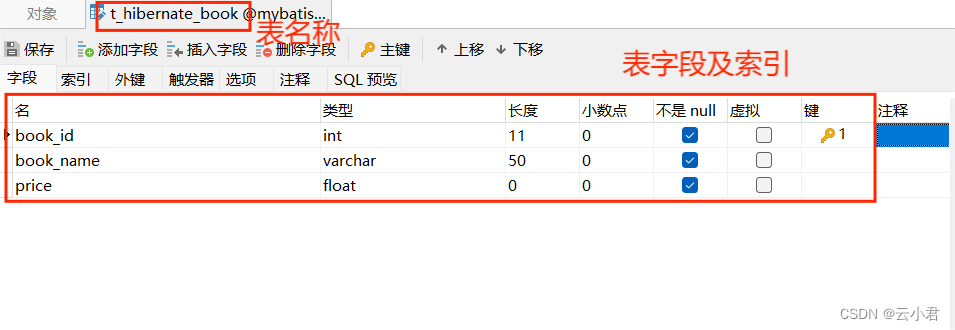
创建名为 t_hibernate_book_category (书籍类别表) 数据表
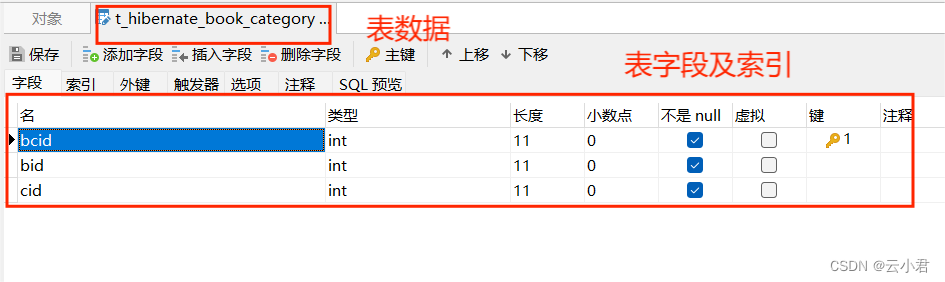
其中名为 bid 的属性字段为 t_hibernate_book (书籍表) 的 bid(主键) 的外键
其中名为 cid 的属性字段为 t_hibernate_category (类别表) 的 category_id (主键) 的外键
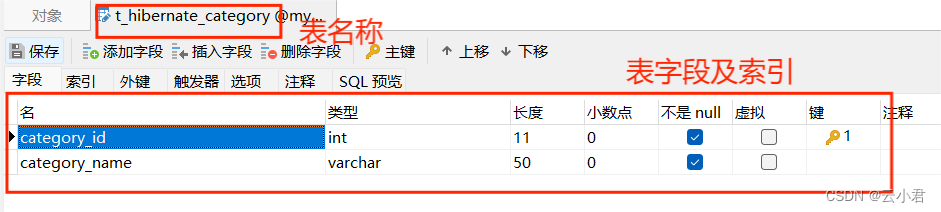
创建名为 t_hibernate_category (类别表) 数据表
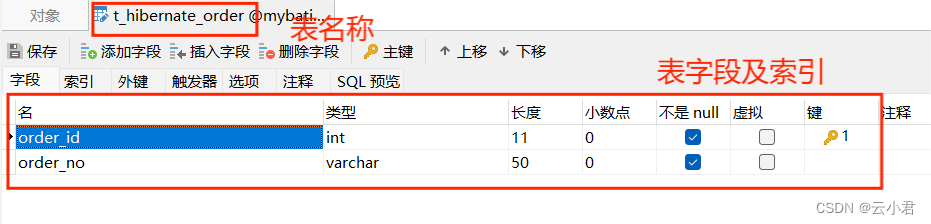
创建名为 t_hibernate_order (订单表) 数据表
创建名为 t_hibernate_order_item (订单详情表) 数据表
其中名为 order_id 的属性字段为 t_hibernate_order (订单表) 的 oid (主键) 的外键
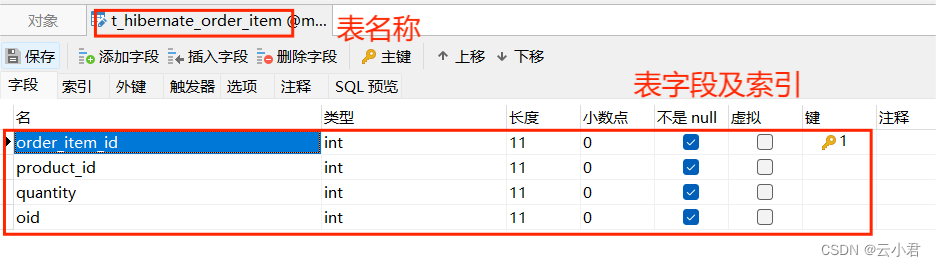
2.2 配置文件
修改名为 generatorConfig.xml 的 配置文件,修改后的所有代码如下 :
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE generatorConfiguration PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN""http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd" >
<generatorConfiguration><!-- 引入配置文件 --><properties resource="jdbc.properties"/><!--指定数据库jdbc驱动jar包的位置--><classPathEntry location="D:\\temp\\mvn_repository\\mysql\\mysql-connector-java\\5.1.44\\mysql-connector-java-5.1.44.jar"/><!-- 一个数据库一个context --><context id="infoGuardian"><!-- 注释 --><commentGenerator><property name="suppressAllComments" value="true"/><!-- 是否取消注释 --><property name="suppressDate" value="true"/> <!-- 是否生成注释代时间戳 --></commentGenerator><!-- jdbc连接 --><jdbcConnection driverClass="${jdbc.driver}"connectionURL="${jdbc.url}" userId="${jdbc.username}" password="${jdbc.password}"/><!-- 类型转换 --><javaTypeResolver><!-- 是否使用bigDecimal, false可自动转化以下类型(Long, Integer, Short, etc.) --><property name="forceBigDecimals" value="false"/></javaTypeResolver><!-- 01 指定javaBean生成的位置 --><!-- targetPackage:指定生成的model生成所在的包名 --><!-- targetProject:指定在该项目下所在的路径 --><javaModelGenerator targetPackage="com.CloudJun.model"targetProject="src/main/java"><!-- 是否允许子包,即targetPackage.schemaName.tableName --><property name="enableSubPackages" value="false"/><!-- 是否对model添加构造函数 --><property name="constructorBased" value="true"/><!-- 是否针对string类型的字段在set的时候进行trim调用 --><property name="trimStrings" value="false"/><!-- 建立的Model对象是否 不可改变 即生成的Model对象不会有 setter方法,只有构造方法 --><property name="immutable" value="false"/></javaModelGenerator><!-- 02 指定sql映射文件生成的位置 --><sqlMapGenerator targetPackage="com.CloudJun.mapper"targetProject="src/main/java"><!-- 是否允许子包,即targetPackage.schemaName.tableName --><property name="enableSubPackages" value="false"/></sqlMapGenerator><!-- 03 生成XxxMapper接口 --><!-- type="ANNOTATEDMAPPER",生成Java Model 和基于注解的Mapper对象 --><!-- type="MIXEDMAPPER",生成基于注解的Java Model 和相应的Mapper对象 --><!-- type="XMLMAPPER",生成SQLMap XML文件和独立的Mapper接口 --><javaClientGenerator targetPackage="com.CloudJun.mapper"targetProject="src/main/java" type="XMLMAPPER"><!-- 是否在当前路径下新加一层schema,false路径com.oop.eksp.user.model, true:com.oop.eksp.user.model.[schemaName] --><property name="enableSubPackages" value="false"/></javaClientGenerator><!-- 配置表信息 --><!-- schema即为数据库名 --><!-- tableName为对应的数据库表 --><!-- domainObjectName是要生成的实体类 --><!-- enable*ByExample是否生成 example类 --><!--<table schema="" tableName="t_book" domainObjectName="Book"--><!--enableCountByExample="false" enableDeleteByExample="false"--><!--enableSelectByExample="false" enableUpdateByExample="false">--><!--<!– 忽略列,不生成bean 字段 –>--><!--<!– <ignoreColumn column="FRED" /> –>--><!--<!– 指定列的java数据类型 –>--><!--<!– <columnOverride column="LONG_VARCHAR_FIELD" jdbcType="VARCHAR" /> –>--><!--</table>--><table schema="" tableName="t_hibernate_book" domainObjectName="HBook"enableCountByExample="false" enableDeleteByExample="false"enableSelectByExample="false" enableUpdateByExample="false"></table><table schema="" tableName="t_hibernate_category" domainObjectName="Category"enableCountByExample="false" enableDeleteByExample="false"enableSelectByExample="false" enableUpdateByExample="false"></table><table schema="" tableName="t_hibernate_book_category" domainObjectName="HBookCategory"enableCountByExample="false" enableDeleteByExample="false"enableSelectByExample="false" enableUpdateByExample="false"></table><table schema="" tableName="t_hibernate_order" domainObjectName="Order"enableCountByExample="false" enableDeleteByExample="false"enableSelectByExample="false" enableUpdateByExample="false"></table><table schema="" tableName="t_hibernate_order_item" domainObjectName="OrderItem"enableCountByExample="false" enableDeleteByExample="false"enableSelectByExample="false" enableUpdateByExample="false"></table></context>
</generatorConfiguration>
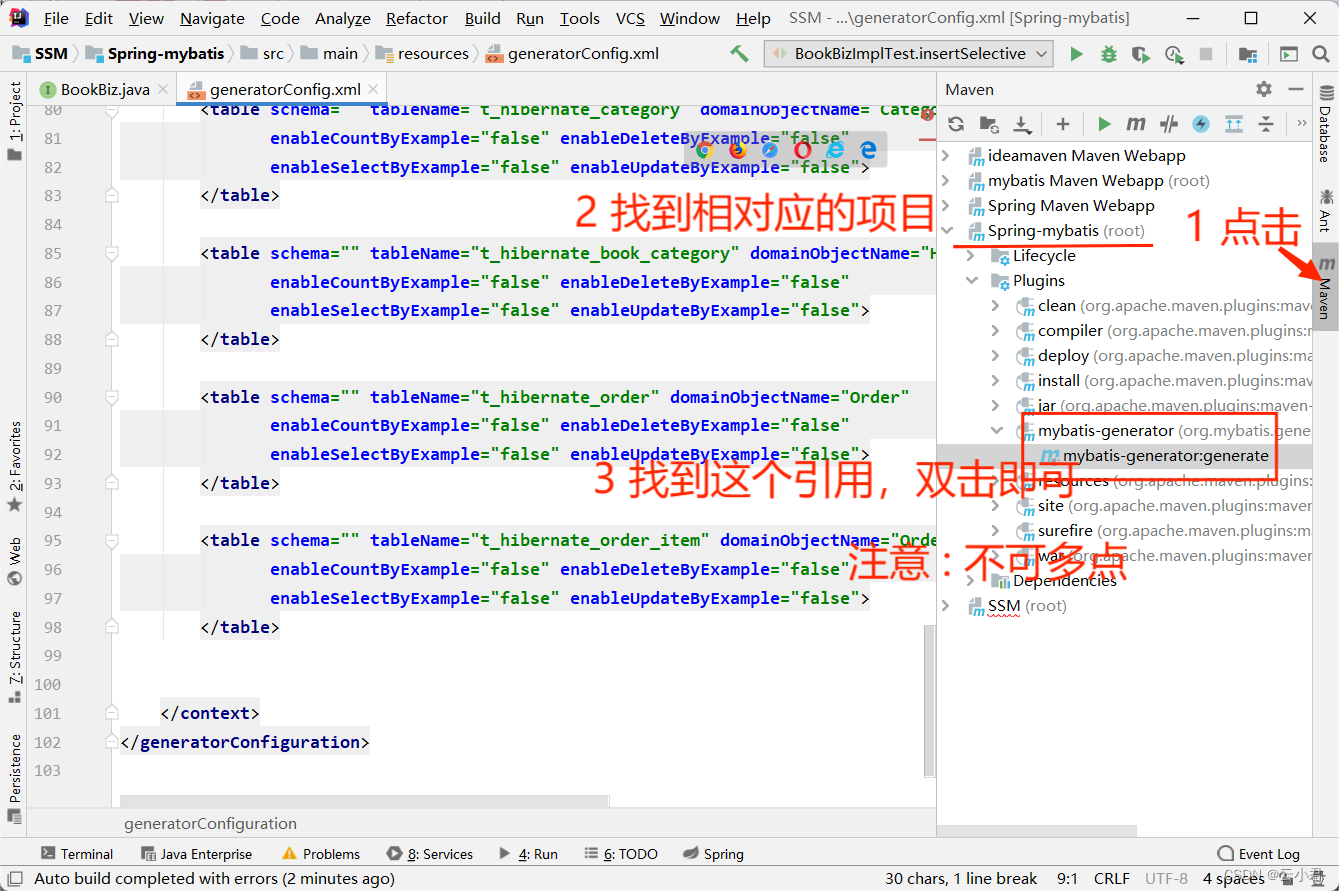
2.3 代码生成
配置好 generatorConfig.xml 的配置文件后进行,自动生成代码,操作如图 :
代码生成后就会出现以下的实体类对象,配置文件,接口类,如图 :
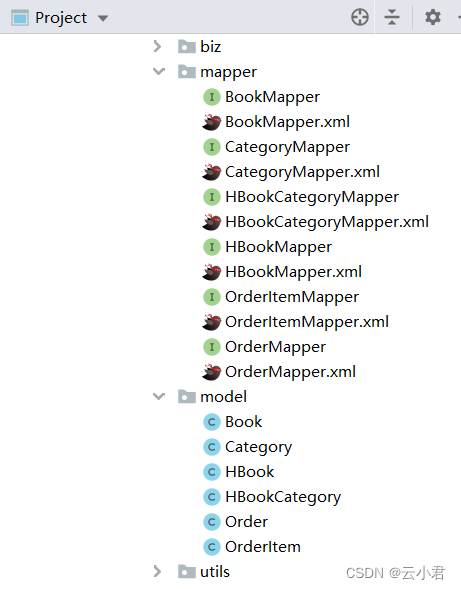
然后将每个实体类对象里面重写一下toString()方法
2.4 编写测试
创建一个 名为 OrderItemVo 的类,继承OrderItem类,及属性有Order对象
package com.CloudJun.vo;import com.CloudJun.model.Order;
import com.CloudJun.model.OrderItem;/*** @author CloudJun* @create 2023-08-26 15:54*/
public class OrderItemVo extends OrderItem {private Order order;public Order getOrder() {return order;}public void setOrder(Order order) {this.order = order;}}
在自动生成的OrderItemMapper.xml配置文件中进行增加以下配置
<resultMap id="OrderItemMap" type="com.CloudJun.vo.OrderItemVo" ><result column="order_item_id" property="orderItemId" ></result><result column="product_id" property="productId" ></result><result column="quantity" property="quantity" ></result><result column="oid" property="oid" ></result><association property="order" javaType="com.CloudJun.model.Order"><result column="order_id" property="orderId" ></result><result column="order_no" property="orderNo" ></result></association> </resultMap> <select id="selectByBiid" resultMap="OrderItemMap" parameterType="java.lang.Integer" >SELECT * FROMt_hibernate_order o ,t_hibernate_order_item oiWHERE o.order_id = oi.oidAND oi.order_item_id = #{oiid} </select>
在自动生成的 OrderItemMapper 接口中进行增加以下代码
OrderItemVo selectByBiid(@Param("oiid") Integer oiid);
创建一个接口名为 : OrderItemBiz 接口
package com.CloudJun.biz;import com.CloudJun.model.OrderItem; import com.CloudJun.vo.OrderItemVo; import org.apache.ibatis.annotations.Param;public interface OrderItemBiz {OrderItemVo selectByBiid(Integer oiid);}
实现以上创建的接口,创建一个实现了名为 OrderItemBizImpl 类
package com.CloudJun.biz.impl;import com.CloudJun.biz.OrderItemBiz; import com.CloudJun.mapper.OrderItemMapper; import com.CloudJun.vo.OrderItemVo; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Service;/*** @author CloudJun* @create 2023-08-26 16:23*/ @Service public class OrderItemBizImpl implements OrderItemBiz {@Autowiredprivate OrderItemMapper orderItemMapper;@Overridepublic OrderItemVo selectByBiid(Integer oiid) {return orderItemMapper.selectByBiid(oiid);} }
创建一个测试类 名为 Test01 ,用来进行方法测试
package com.CloudJun.biz.impl;import com.CloudJun.biz.OrderBiz; import com.CloudJun.biz.OrderItemBiz; import com.CloudJun.vo.OrderItemVo; import com.CloudJun.vo.OrderVo; import org.junit.After; import org.junit.Before; import org.junit.Test; import org.junit.runner.RunWith; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.test.context.ContextConfiguration; import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;/*** @author CloudJun* @create 2023-08-26 15:03*/ @RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(locations={"classpath:spring-context.xml"}) public class Test01 {@Autowiredprivate OrderItemBiz orderItemBiz;@Beforepublic void setUp() throws Exception {}@Afterpublic void tearDown() throws Exception {}@Testpublic void selectByBiid() {OrderItemVo orderItemVo = orderItemBiz.selectByBiid(27);System.out.println(orderItemVo);System.out.println(orderItemVo.getOrder());}}
执行测试类中selectByBiid()的方法,结果如图 :

三、一对多关联映射
创建一个 名为 OrdeVo 的类,继承Order类,及属性有List<OrderItem>集合
用来存储查询到的OrderItem对象,因为是一对多所有查询出有多个对象
package com.CloudJun.vo;import com.CloudJun.model.Order;
import com.CloudJun.model.OrderItem;
import com.CloudJun.utils.PageBean;import java.util.ArrayList;
import java.util.List;/*** @author CloudJun* @create 2023-08-26 14:54*/
public class OrderVo extends Order {private List<OrderItem> orderItems = new ArrayList<OrderItem>();public List<OrderItem> getOrderItems() {return orderItems;}public void setOrderItems(List<OrderItem> orderItems) {this.orderItems = orderItems;}}
在自动生成的 OrderMapper.xml 配置文件中增加以下配置
<resultMap id="OrderVoMap" type="com.CloudJun.vo.OrderVo"><result column="order_id" property="orderId" ></result><result column="order_no" property="orderNo" ></result><collection property="orderItems" ofType="com.CloudJun.model.OrderItem"><result column="order_item_id" property="orderItemId" ></result><result column="product_id" property="productId" ></result><result column="quantity" property="quantity" ></result><result column="oid" property="oid" ></result></collection></resultMap><select id="selectByOid" resultMap="OrderVoMap" parameterType="java.lang.Integer" >SELECT * FROMt_hibernate_order o ,t_hibernate_order_item oiWHERE o.order_id = oi.oidAND o.order_id = #{oid}</select>
在自动生成的 OrderMapper接口中进行增加以下代码
OrderVo selectByOid(@Param("oid") Integer oid);
创建一个接口名为 : OrderBiz 接口
package com.CloudJun.biz;import com.CloudJun.vo.OrderVo;public interface OrderBiz {OrderVo selectByOid(Integer oid);}
在实现以上 OrderBiz 接口,创建一个实现类,名为 OrderBizImpl
package com.CloudJun.biz.impl;import com.CloudJun.biz.OrderBiz; import com.CloudJun.mapper.OrderMapper; import com.CloudJun.vo.OrderVo; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Service;/*** @author CloudJun* @create 2023-08-26 15:06*/ @Service public class OrderBizImpl implements OrderBiz {@Autowiredprivate OrderMapper orderMapper;@Overridepublic OrderVo selectByOid(Integer oid) {return orderMapper.selectByOid(oid);} }
在测试类( Test01 )中增加以下测试方法及接口
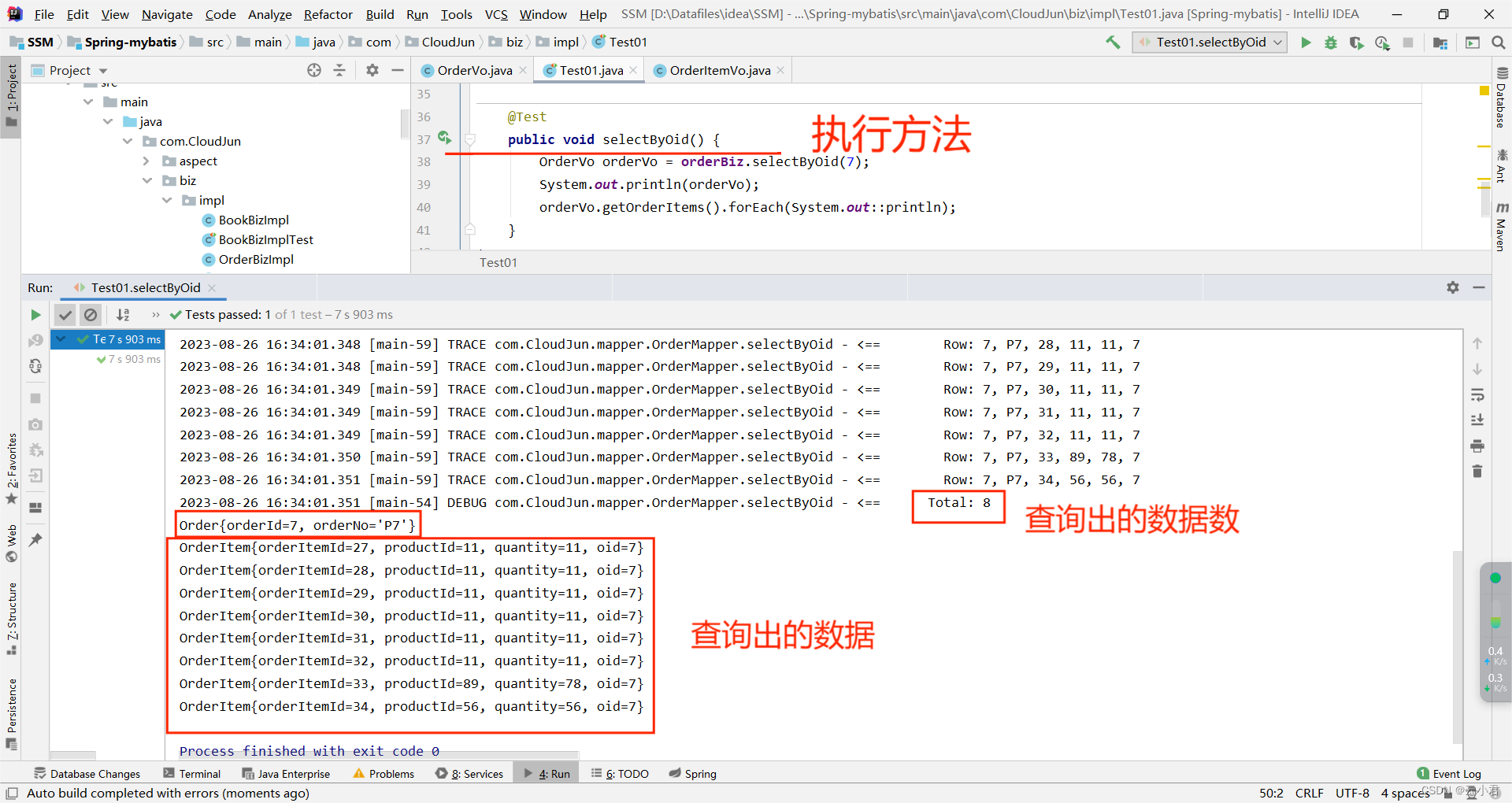
@Autowiredprivate OrderBiz orderBiz;@Testpublic void selectByOid() {OrderVo orderVo = orderBiz.selectByOid(7);System.out.println(orderVo);orderVo.getOrderItems().forEach(System.out::println);}
执行其中的方法进行测试,结果为如图 :
四 、多对多关联映射
在自动生成的 HBookMapper.xml 配置文件中增加以下配置
<resultMap id="HBookVoMap" type="com.CloudJun.vo.HBookVo" ><result column="book_id" property="bookId"></result><result column="book_name" property="bookName"></result><result column="price" property="price"></result><collection property="categories" ofType="com.CloudJun.model.Category"><result column="category_id" property="categoryId"></result><result column="category_name" property="categoryName"></result></collection></resultMap><select id="selectByBookId" resultMap="HBookVoMap" parameterType="java.lang.Integer" >SELECT * FROMt_hibernate_book b,t_hibernate_book_category bc ,t_hibernate_category cWHERE b.book_id = bc.bidAND bc.cid = c.category_idAND b.book_id = #{bid}</select>在自动生成的 HBookMapper 接口 中增加以下方法
HBookVo selectByBookId(@Param("bid") Integer bid);
创建一个接口名为 HBookBiz
package com.CloudJun.biz;import com.CloudJun.vo.HBookVo;
import org.apache.ibatis.annotations.Param;public interface HBookBiz {HBookVo selectByBookId(@Param("bid") Integer bid);}在实现以上 HBookBiz 接口,创建一个实现类,名为 HBookBizImpl
package com.CloudJun.biz.impl;import com.CloudJun.biz.HBookBiz;
import com.CloudJun.mapper.HBookMapper;
import com.CloudJun.vo.HBookVo;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;/*** @author CloudJun* @create 2023-08-26 17:43*/
@Service
public class HBookBizImpl implements HBookBiz {@Autowiredprivate HBookMapper hBookMapper;@Overridepublic HBookVo selectByBookId(Integer bid) {return hBookMapper.selectByBookId(bid);}}
在测试类( Test01 )中增加以下测试方法及接口
@Autowiredprivate HBookBiz hbookBiz;@Testpublic void selectByBookId() {HBookVo hBookVo = hbookBiz.selectByBookId(8);System.out.println(hBookVo);hBookVo.getCategories().forEach(System.out::println);}
执行其中的方法进行测试,结果为如图 :

在自动生成的 CategoryMapper.xml 配置文件中增加以下配置
<resultMap id="CategoryVoMap" type="com.CloudJun.vo.CategoryVo"><result column="category_id" property="categoryId"></result><result column="category_name" property="categoryName"></result><collection property="books" ofType="com.CloudJun.model.HBook"><result column="book_id" property="bookId"></result><result column="book_name" property="bookName"></result><result column="price" property="price"></result></collection></resultMap><select id="selectByCategoryId" resultMap="CategoryVoMap" parameterType="java.lang.Integer" >SELECT * FROMt_hibernate_book b,t_hibernate_book_category bc ,t_hibernate_category cWHERE b.book_id = bc.bidAND bc.cid = c.category_idAND c.category_id = #{cid}</select>在自动生成的 CategoryMapper 接口 中增加以下方法
CategoryVo selectByCategoryId(@Param("cid") Integer cid);
创建一个接口名为 CategoryBiz
package com.CloudJun.biz;import com.CloudJun.vo.CategoryVo;public interface CategoryBiz {CategoryVo selectByCategoryId( Integer cid);}在实现以上 CategoryBiz 接口,创建一个实现类,名为 CategoryBizImpl
package com.CloudJun.biz.impl;import com.CloudJun.biz.CategoryBiz;
import com.CloudJun.mapper.CategoryMapper;
import com.CloudJun.vo.CategoryVo;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;/*** @author CloudJun* @create 2023-08-26 17:56*/
@Service
public class CategoryBizImpl implements CategoryBiz {@Autowiredprivate CategoryMapper categoryMapper;@Overridepublic CategoryVo selectByCategoryId(Integer cid) {return categoryMapper.selectByCategoryId(cid);}}
在测试类( Test01 )中增加以下测试方法及接口
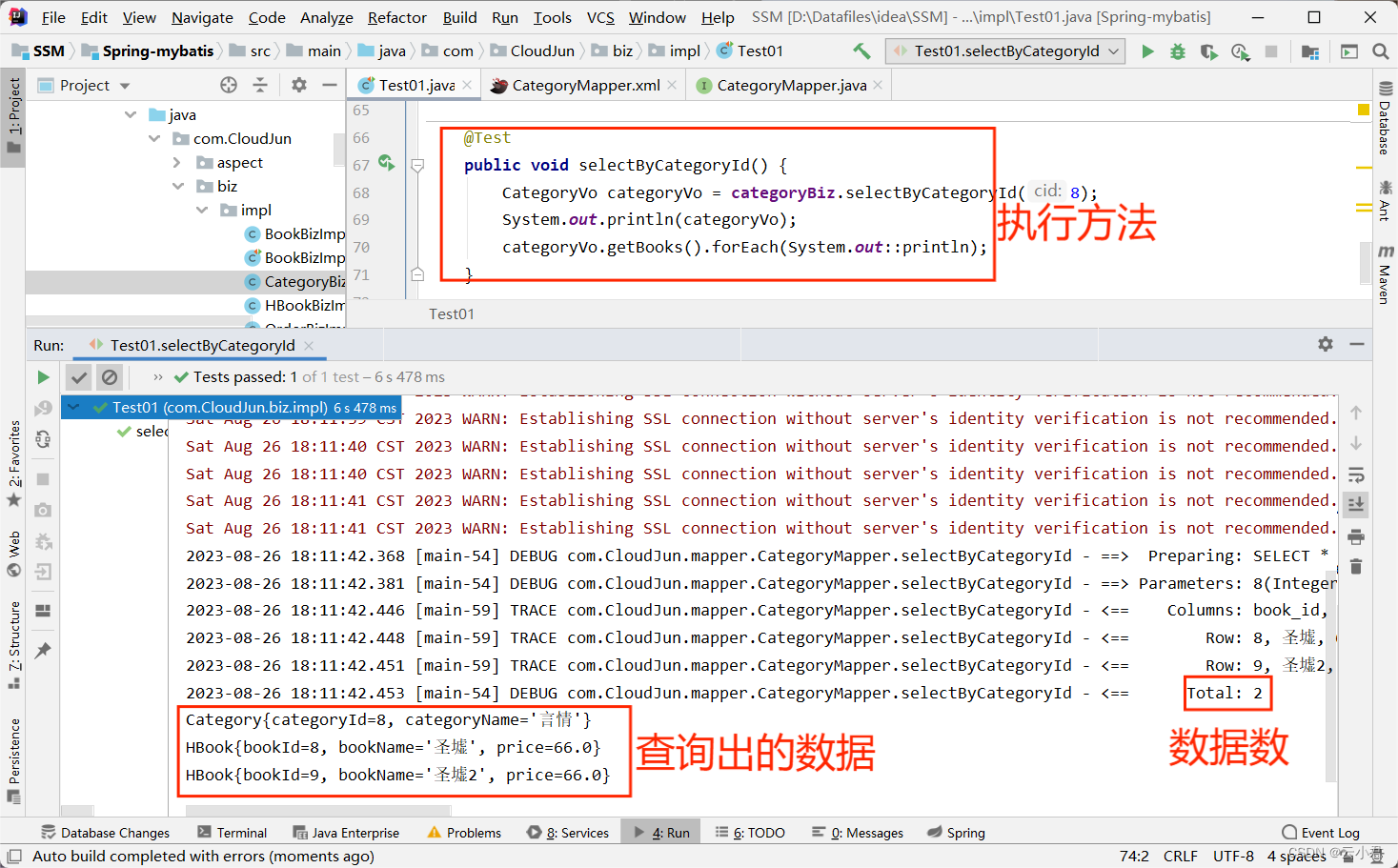
@Autowiredprivate CategoryBiz categoryBiz; @Testpublic void selectByCategoryId() {CategoryVo categoryVo = categoryBiz.selectByCategoryId(8);System.out.println(categoryVo);categoryVo.getBooks().forEach(System.out::println);}
执行其中的方法进行测试,结果为如图 :
给我们带来的收获
学习Mybatis的关联关系映射可以带来以下收获和认识:
- 1. 灵活的数据查询:通过关联关系映射,可以方便地进行多表关联查询,获取到关联表中的相关数据。这样可以减少数据库查询的次数,提高查询效率,并且可以一次性获取到所有关联数据,减少了后续数据操作的开销。
- 2. 数据的一致性和完整性:在进行关联关系映射时,可以通过定义中间表和映射关系,保证数据的一致性和完整性。在插入、更新和删除数据时,需要同时维护中间表的数据,以保证关联关系的正确性。
- 3. 简化数据操作:通过关联关系映射,可以将关联表中的数据映射到实体类的关联属性上,使得获取关联数据变得简单和直观。不需要手动编写复杂的SQL语句,只需要通过配置映射文件,就可以方便地获取到关联数据。
- 4. 提高代码的可读性和可维护性:通过Mybatis的关联关系映射,可以将数据操作的逻辑和SQL语句分离,使得代码更加清晰和易于理解。同时,通过使用映射文件,可以方便地修改和维护数据操作的逻辑,提高代码的可维护性。
总结来说,学习Mybatis的关联关系映射可以带来灵活的数据查询、数据的一致性和完整性、简化数据操作以及提高代码的可读性和可维护性等好处。通过掌握关联关系映射的知识,可以更加有效地进行数据库操作和数据查询,提高开发效率和代码质量。
