ppt 如何做网站交互式wordpress 4.0 id不连续
vue 与 iframe 通讯
- 发送数据
- vue 向 iframe 发送数据
- iframe 向 vue 发送数据
- 接收信息( vue & iframe 通用)
- 实现相互通讯
- 通讯流程图
- 实现代码
- vue 页面
- iframe页面
- iframe 内部重定向访问地址,更新 vue 路由
- 访问跨域
- 代码下载
前言:vue嵌套iframe实现步骤
发送数据
vue 向 iframe 发送数据
// utils/common.js/** vue向iframe发送数据* content iframe.contentWindow* type 事件类型* data 传送的数据*/export function sendPostMessage(content, type, data = {}) {content.postMessage({ type, data }, '*');}
iframe 向 vue 发送数据
// update.html & base.html & includes.html ...function sendPostMessage(type, data = {}) {window.parent.postMessage({ type, data }, "*");}
接收信息( vue & iframe 通用)
实例化PubSub时, 入参需提前定义,不然接收不到消息
// utils/iframe-message.js/*** 接收页面 postMessage 发送的信息* Pubsub提供多种类型供订阅,使用方法如下:* 1. 需要接收webSocket的地方,import eventsPub from '本文件路径'* 2. eventsPub.on(类型, callback)* 例:* const receive = data => console.log('eventName', data)* eventsPub.on('eventName', receive)* 3.不需要继续接收时调用* eventsPub.remove("eventName", receive) 移除callback*//** 重要: postMessageEvent 中的 type 需提前定义 */class PubSub {list = {};constructor(events) {this.list = {};events.forEach(v => {this.list[v] = [];});}on(ev, callback) {if (this.list[ev]) {this.list[ev].push(callback);return true;} else {return false;}}emit(ev, data) {// data拷贝: 防止其他callback修改dataconst dataStr = JSON.stringify(data);if (this.list[ev]) {this.list[ev].forEach((v) => {try {v(JSON.parse(dataStr));} catch (err) {console.log("callback error:", err, v);}});return true;} else {return false;}}remove(ev, callback) {if (callback && this.list[ev]) {this.list[ev].forEach((v, i) => {if (v === callback) {this.list[ev].splice(i, 1);}});return true;} else {return false;}}}// 订阅的类型需要在postMessageEvent中提前定义好const postMessageEvent = ["PAGE_ISREADY"]const eventsPub = new PubSub(postMessageEvent);window.addEventListener("message", function (e) {if (e.data?.type) {eventsPub.emit(e.data.type, e.data.data)}});export default eventsPub;
实现相互通讯
通讯流程图
vue路由更新 及 iframe地址刷新时,两者之间的通讯流程
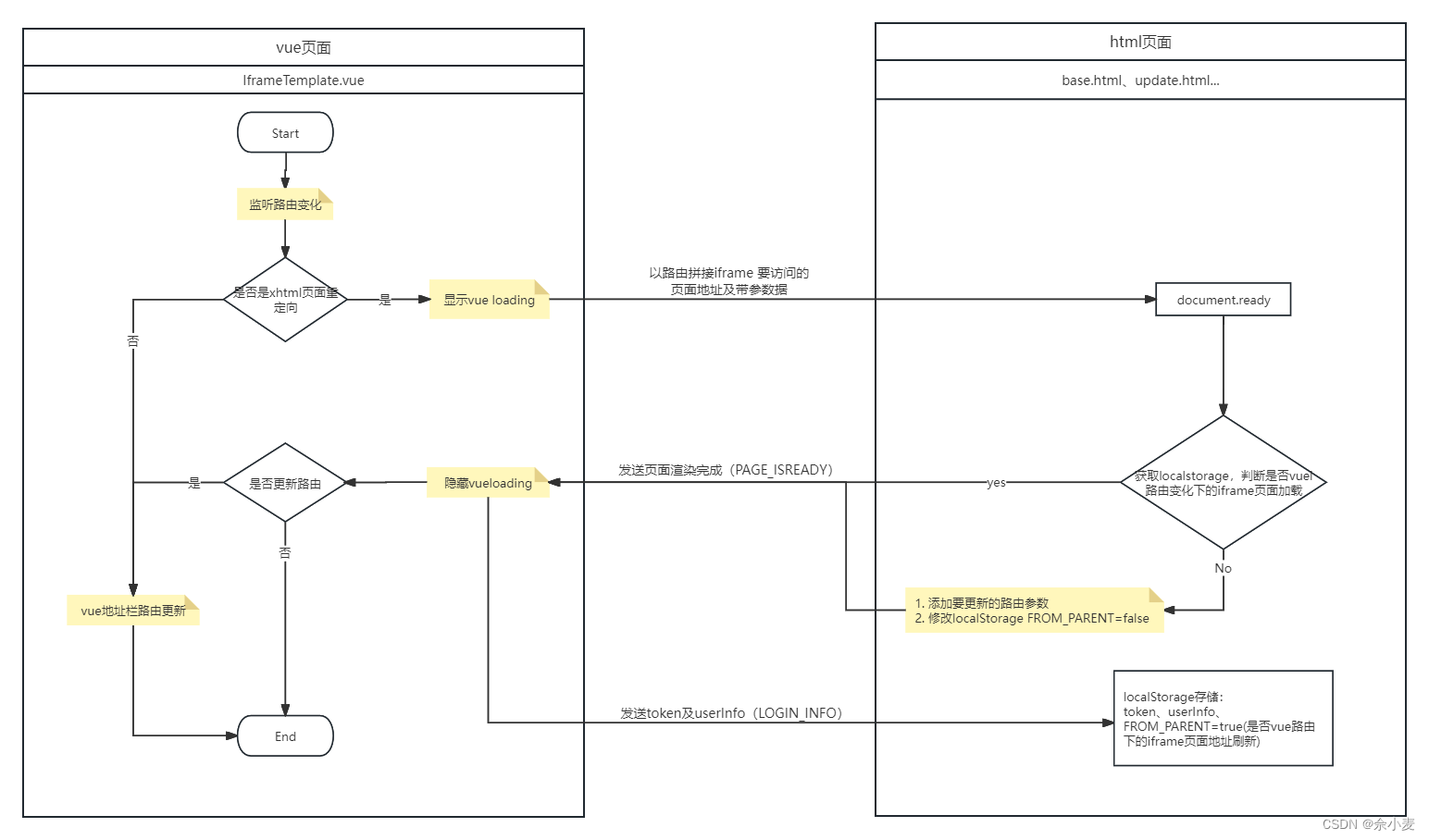
实现代码
vue 页面
// IframeTemplate.vueimport { onMounted, onBeforeUnmount } from "vue";import eventsPub from "@utils/iframe-message.js"import { sendPostMessage } from "@utils/common.js"onMounted(() => {// 接收信息eventsPub.on("PAGE_ISREADY", pageIsReady)});onBeforeUnmount(() => {eventsPub.remove("PAGE_ISREADY", pageIsReady)});function pageIsReady() {// console.log("PAGE_ISREADY")updateIframeLoginInfo()}// 发送信息/** iframe 页面登录信息同步 */function updateIframeLoginInfo() {const iframeWindow = $("#common-iframe")[0].contentWindowsendPostMessage(iframeWindow, "LOGIN_INFO", {token: localStorage.getItem("TOKEN"),userInfo: localStorage.getItem("USER") || "{}"})}
iframe页面
// utils/iframe-message.js// 将该文件写成原生写法: 删除 remove 之后的代码// 添加下边的代码/** 创建消息接收实例 */const postMessageEvent = ["LOGIN_INFO"]const eventsPub = new PubSub(postMessageEvent);/** 接收父页面的消息 */window.addEventListener("message", function (e) {if (e.data?.type) {eventsPub.emit(e.data.type, e.data.data)}});/** 发送消息 */function sendPostMessage(type, data = {}) {window.parent.postMessage({ type, data }, "*");}
// base.html、includes.html、update.html...// 在所有的页面中引入iframe-message.js、jquery.js<script type="text/javascript" src="./js/jquery.js"></script><script type="text/javascript" src="./js/iframe-message.js"></script>// 并添加下边的代码<script type="text/javascript">/** 获取当前登录用户信息并存储 */function setUserInfo(data) {const { token, userInfo } = data;const curToken = localStorage.getItem("TOKEN")const curUser = localStorage.getItem("USER")curToken != token && localStorage.setItem("TOKEN", token)curUser != userInfo && localStorage.setItem("USER", userInfo)}$(document).ready(() => {// GET VUE MESSAGEeventsPub.on("LOGIN_INFO", setUserInfo)// NOTIFY VUE MESSAGEsendPostMessage("PAGE_ISREADY", { iframeIsReady: true })})</script>
iframe 内部重定向访问地址,更新 vue 路由
需将iframe的地址添加到vue路由上
-
iframe页面判断是否是内部跳转,并将页面地址发送到vue// base.html...function setUserInfo(data) {// 其他...localStorage.setItem("FROM_PARENT", true)}$(document).ready(() => {// 其他.../** iframe内部页面跳转,加载完成 - */const fromParent = localStorage.getItem("FROM_PARENT")localStorage.removeItem("FROM_PARENT")// 判断是否是vue 页面重定向的const { pathname, href, search } = window.locationlet path = pathname.split(".")[0];sendPostMessage("PAGE_ISREADY", !fromParent ? {} : { path })})``` -
vue接收到地址后,页面路由修改,但iframe页面不需要再刷新// IframeTemplate.vue// 监听路由变更watch(route, () => {const historyParams = history.state.params// 只更新路由时,iframe 页面地址不更新if (historyParams && historyParams.justRoute && isFrameSrcUpdate == route.path && !isMounted) {isFrameSrcUpdate = "";return;}// iframe 页面地址更新createIframe()});/** iframe 页面加载完毕* 1. 登陆信息同步* 2. iframe 内部跳转,页面地址变化后,vue route也修改(但页面不刷新)*/function pageIsReady(data) {updateIframeLoginInfo()if (data?.path) {let { path, name, query } = dataisFrameSrcUpdate = path;const exit = router.getRoutes().find(i => i.path == path)/** iframe 发送了一个未添加路由的页面* 1. 添加该页面路由,为能正常访问* 2. 在当前页面刷新后,会有路由不存在的问题,* 需在整体添加路由的位置将当前页面添加进进去*/!exit && router.addRoute({path,name,meta: { isIframe: true },component: () => import("../views/IframePage.vue")})// justRoute:只更新路由,不刷新页面router.push({ path, query, state: { params: { justRoute: true } } });}}
访问跨域
- 问题:
部署到环境上后,vue页面访问iframe地址会有访问跨域问题。 - 解决方案:
在部署vue 服务器配置时允许访问iframe的域名。
如: Apache 部署vue 的服务器配置上添加一行配置:Header always append X-Frame-Options <iframe访问的域名>
代码下载
查看代码地址