网站建设类公司网页脚本设计

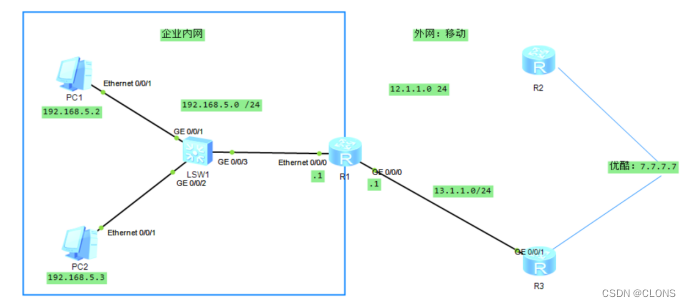
目标:默认数据全部经过移动上网,联通低带宽。
R1
[ ]ip route-static 0.0.0.0 24 12.1.1.2
目的地址 掩码 下一条
[ ]ip route-static 0.0.0.0 24 13.1.1.3 preference 65
目的地址 掩码 下一条 设置优先级为65
R2
配接口
[ ]int e0/0/0/0
[ int e0/0/0/0 ]ip add 12.1.1.2 24
[ int e0/0/0/0 ]int LoopBack 0
[ R2 LoopBack0 ]ip add 7.7.7.7 24
配静态
[ ]ip route-static 192.168.5.0 24 12.1.1.1
目的地址 掩码 下一条
R3
配接口后配loopback口
[ int e0/0/0/0 ]int LoopBack 0
[ R2 LoopBack0 ]ip add 7.7.7.7 24
配静态
[ ]ip route-static 192.168.5.0 24 13.1.1.1
目的地址 掩码 下一条
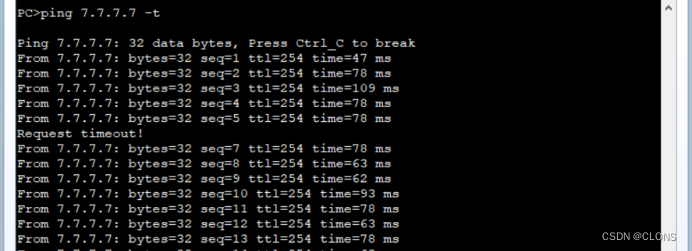
测试连通性
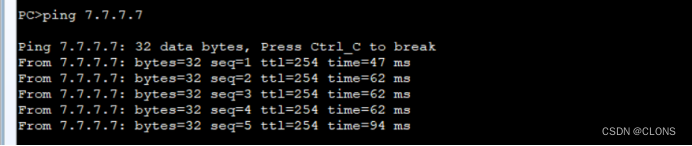
单条线路故障测试