亦庄网站建设,龙岗菠菜网站建设,网站结构设计,网站建设花钱吗文章目录 福昕 PDF 搜索高亮过的文本 福昕 PDF 搜索高亮过的文本
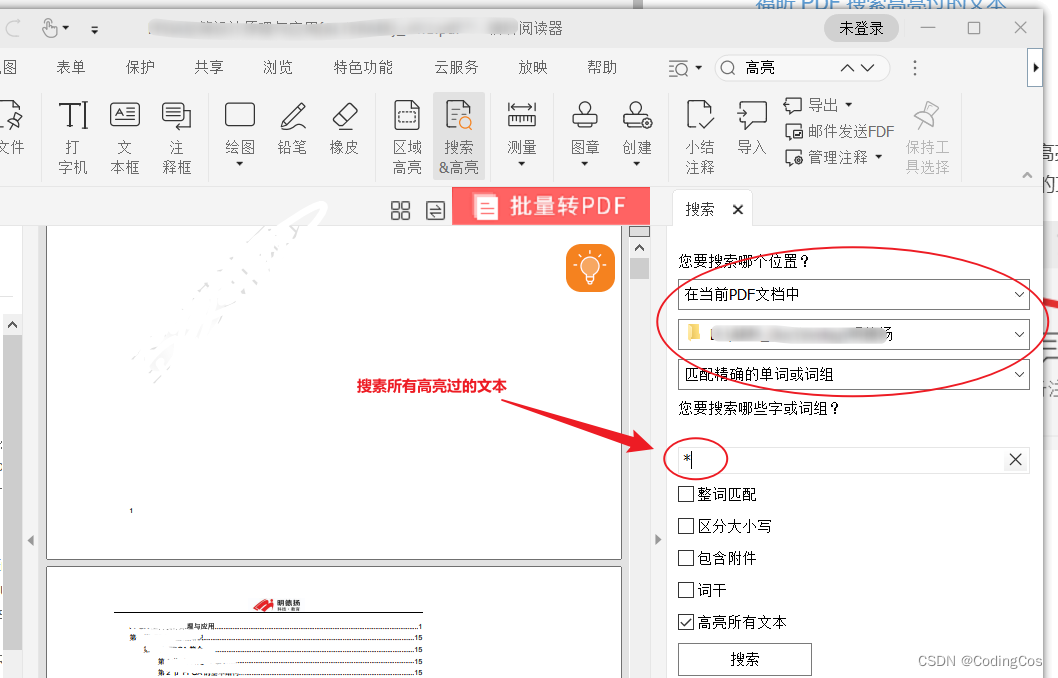
在 pdf 文档阅读过程中,我们需要经常高亮一些文本,以方便下次阅读时找到重点。我这边使用的是 福昕PDF 阅读器,下面就介绍下如何在福昕阅读器中搜索已经高亮过的文本。
文章目录
福昕 PDF 搜索高亮过的文本
福昕 PDF 搜索高亮过的文本
在 pdf 文档阅读过程中,我们需要经常高亮一些文本,以方便下次阅读时找到重点。我这边使用的是 福昕PDF 阅读器,下面就介绍下如何在福昕阅读器中搜索已经高亮过的文本。