网站怎么建立视频经典网站案例
目录
- 一. 🦁 写在前面
- 二. 🦁 在线使用感受
- 2.1 创建 ONLYOFFICE 账号
- 2.2 编辑pdf文档
- 2.3 pdf直接创建表格
- 三. 🦁 写在最后

一. 🦁 写在前面
所谓桌面编辑器就是一种用于编辑文本、图像、视频等多种自媒体的软件工具,具有丰富的功能和工具,可以对文本进行格式化、排版,对图像进行裁剪、调整颜色和对比度,对视频进行剪辑、合并和添加特效等。它还可以支持多种文件格式,如文本文件、图像文件、音频文件和视频文件等,用户可以在编辑器中打开、保存和导出不同的文件类型。
常见的桌面编辑器有很多,如 Word、Excel和PowerPoint,但是处理pdf文件、幻灯片等文件,我觉得体验感最好的还是这个 ONLYOFFICE 桌面编辑器,它已经推出到了8.1版本,已经是一款非常成熟的办公套件,适用于 Linux、Windows 和 macOS。

其分为两个版本,在线使用网址如下:
- 在线办公套件:https://www.onlyoffice.com/zh/office-suite.aspx
- 在线 PDF 编辑器、阅读器和转换器:https://www.onlyoffice.com/zh/pdf-editor.aspx
本地下载软件地址如下:
- https://www.onlyoffice.com/zh/download-desktop.aspx
二. 🦁 在线使用感受
在线体验了一下,分享一波感受!
2.1 创建 ONLYOFFICE 账号
创建好账号后,进入到主页面,这里狮子上传一个pdf文档来编辑。
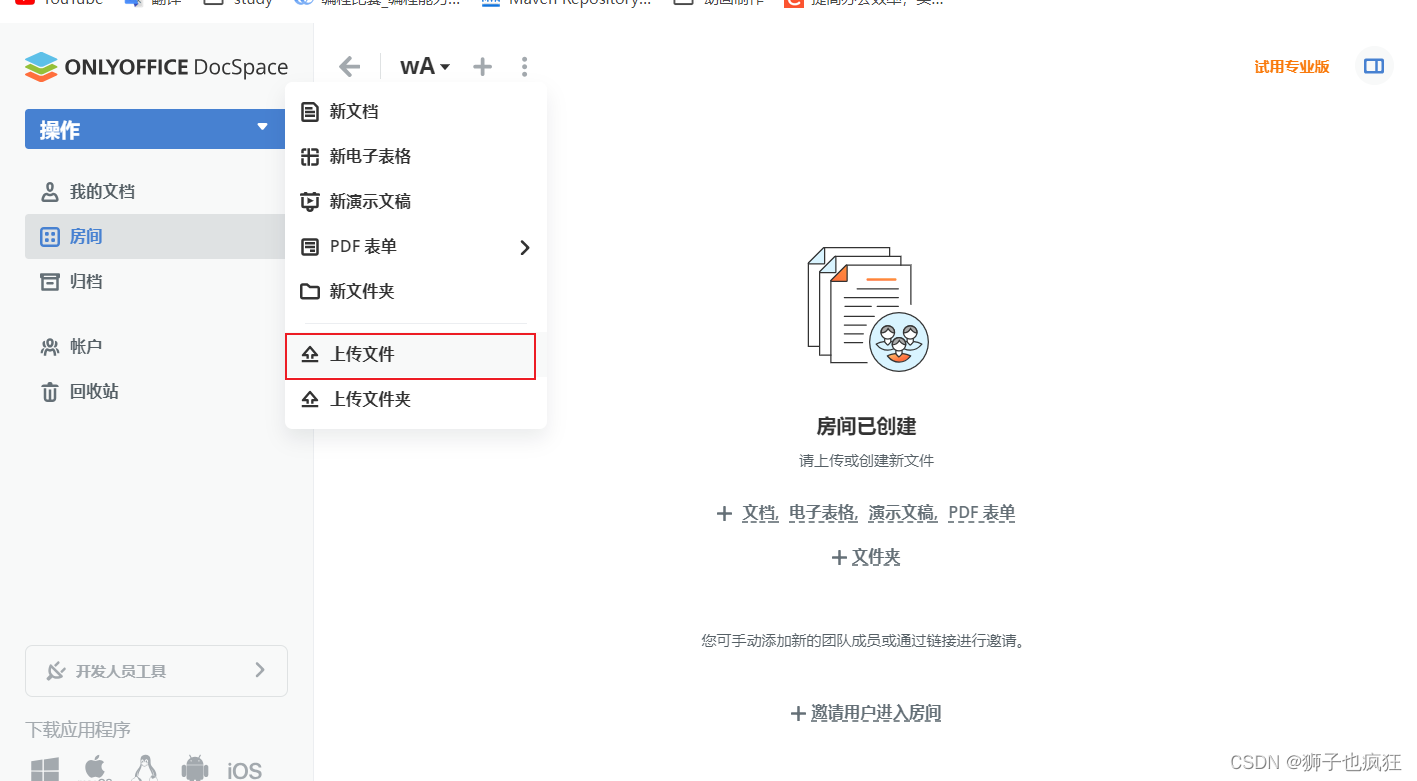
文档如下:

2.2 编辑pdf文档
- 编辑pdf文字
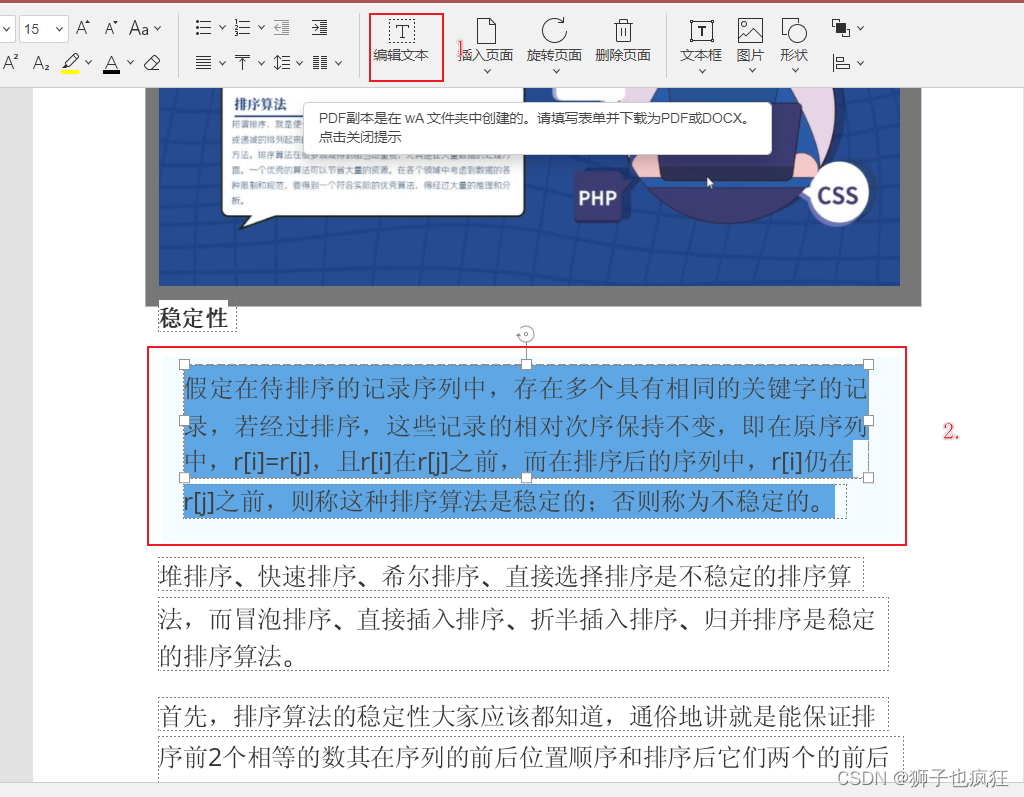
点击编辑文字后,就可以丝滑编辑pdf的文字,这个操作狮子也在wps这个office软件上用过,但是需要氪金,现在有了ONLYOFFICE,你还会想要氪金么,哈哈哈! - 编辑页面
除了编辑文字,页面编辑也很6,可以插入新的页面,也可以旋转页面和删除页面!
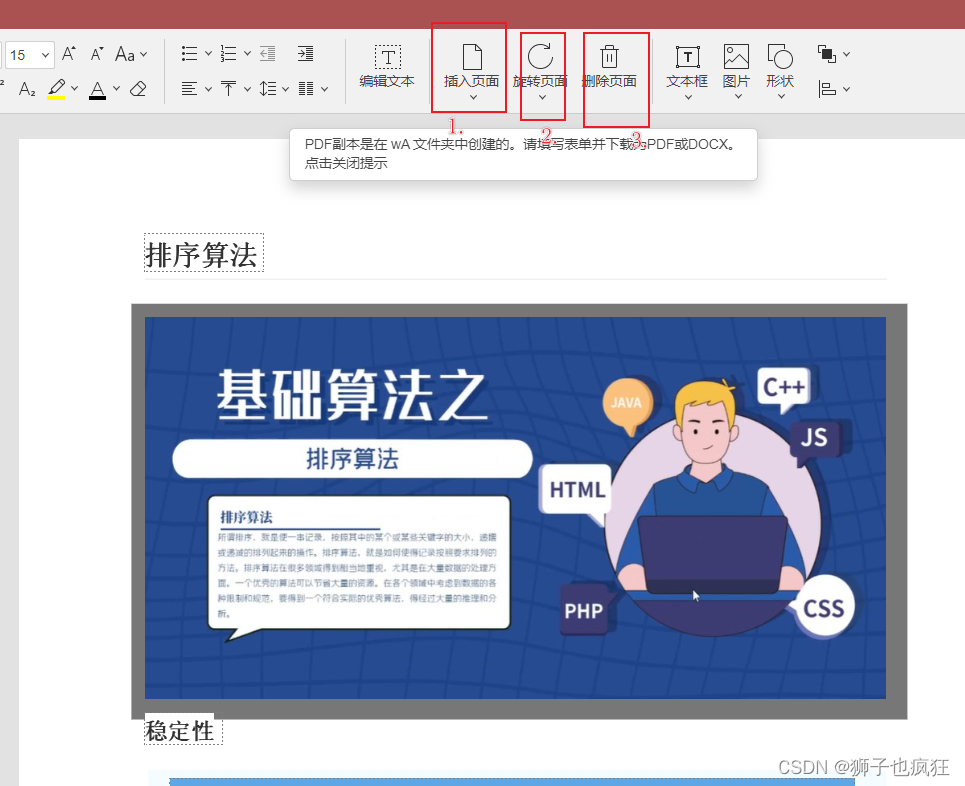
其效果如下:
- 插入所需要的新页面
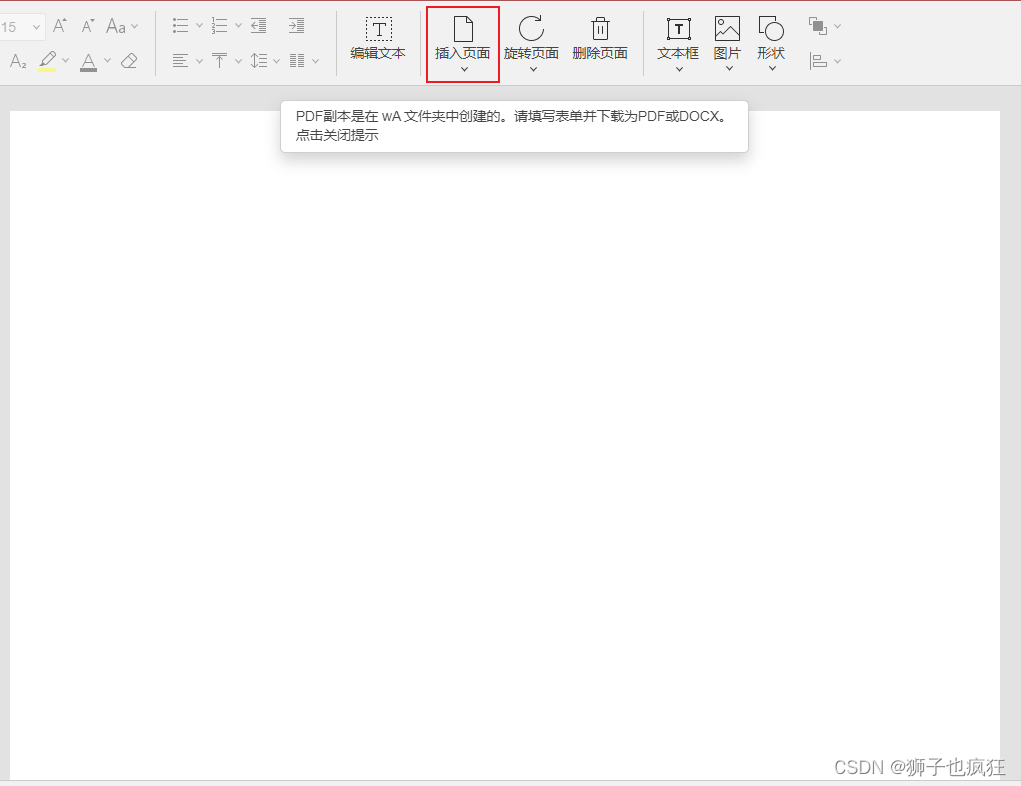
- 便于从不同角度进行打印和展示
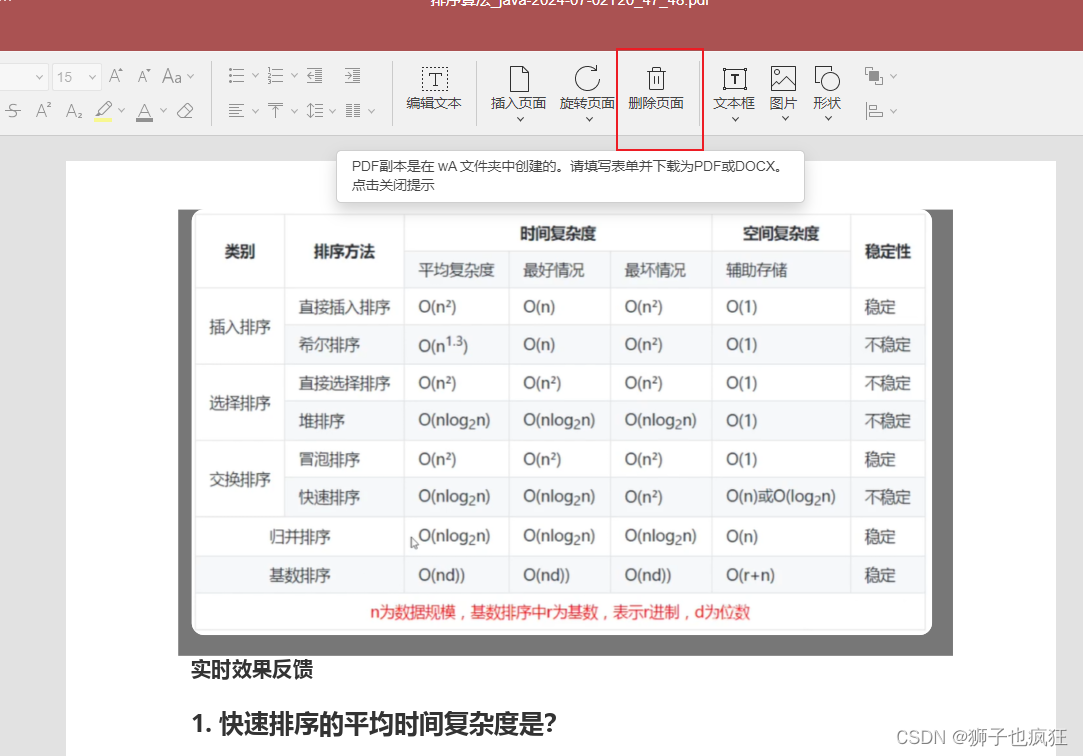
- 删除不需要的页面
- 添加文本注释和标注
甲方可以对不清楚的文档添加注释,让乙方修改!
操作很简单,点击批注这一选项后,然后右键点击需要批注的文本即可!
2.3 pdf直接创建表格
说完前面简单的基本功能外,咱们来看看更新8.1版本后的强大特性之——pdf创建表单功能!
以往咱们创建复杂表格时,只能在word文档创建,并不能直接操作pdf,现在咱们可以直接在pdf上操作啦!
我这里新插入一个空白页面:
点击插入——>表格,然后就可以选择对应的表格横列数,然后自动给你生成啦!生成的表单颜值挺在线的!
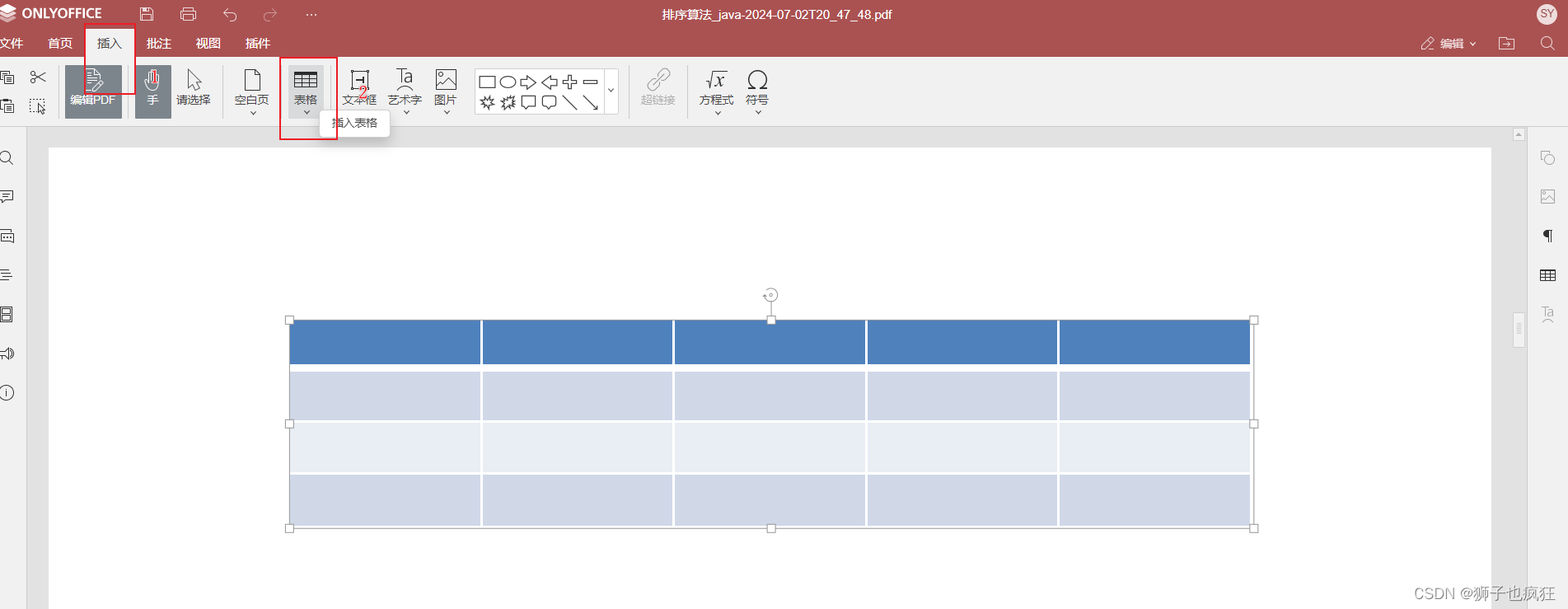
右键之后还会发下能操作表格的一系列设置,真的挺用心的!
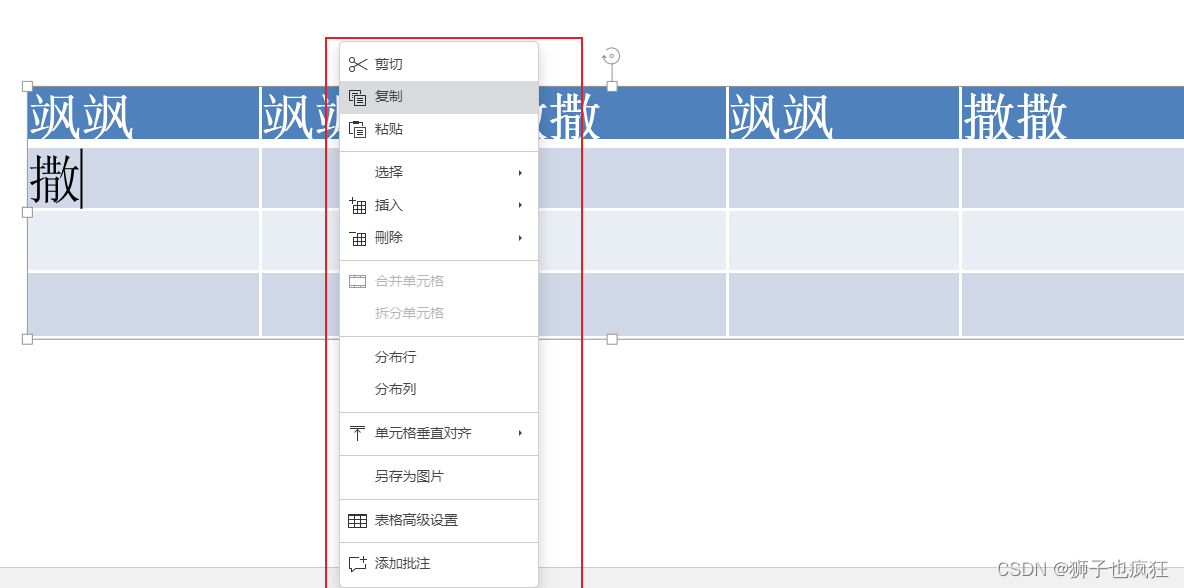
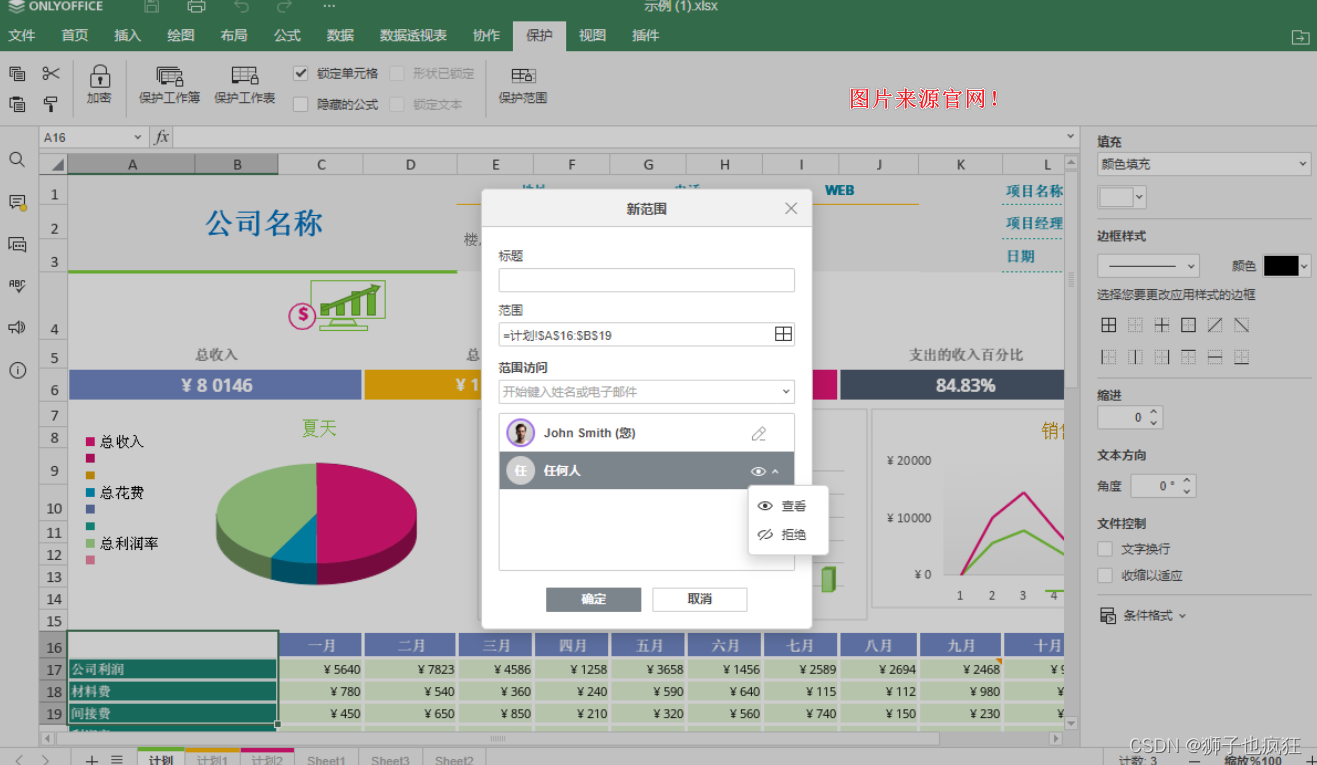
其次,表格数据更有安全保护机制,限制查看受保护范围内的单元格,以保护重要数据。
路径:保护 ➙ 保护范围
如图:
三. 🦁 写在最后
又到结尾了,其实这款应用真的挺不错,除了上面说的功能,还有很多其它不错的操作pdf的功能!主要是个人免费使用,不像某office软件,动一动都要收费!搞起来叭,遥遥领先!

🦁 其它优质专栏推荐 🦁
🌟《Java核心系列(修炼内功,无上心法)》: 主要是JDK源码的核心讲解,几乎每篇文章都过万字,让你详细掌握每一个知识点!
🌟 《springBoot 源码剥析核心系列》:一些场景的Springboot源码剥析以及常用Springboot相关知识点解读
欢迎加入狮子的社区:『Lion-编程进阶之路』,日常收录优质好文
更多文章可持续关注上方🦁的博客,2023咱们顶峰相见!