免费海外网站建设企业名录大全网
头条号:科雷软件测试
学习目录
了解下电脑中的excel表格文件格式
安装xlwt库
xlwt库写入表格内容
1 导入xlwt库
2 用一个图展示下xlwt常用的函数
3 往表格写入一些内容并保存
4 设置样式
1 先初始化XFStyle
2 设置字体font
3 设置边框
4 设置对齐方式
5 设置单元格
6 设置行高和列宽
7 合并单元格
excel表格是大家经常用到的文件格式,各行各业都会跟它打交道。本次我们介绍经常用到的两个经典库,xlrd和xlwt,xlrd用于读取excel表格内容,xlwt用于写入excel表格内容。

了解下电脑中的excel表格文件格式
微软或者金山的excel表格编辑保存时一般要选择文件后缀,有xls和xlsx两类。
xls和xlsx后缀文件的主要区别:
- 文件格式:xls是二进制格式,而xlsx是基于XML的压缩方式。
- 版本:xls是Excel 2003及以前版本生成的文件格式,而xlsx是Excel 2007及以后版本生成的文件格式。
- 兼容性:xlsx格式向下兼容,而xls格式不支持向后兼容。
安装xlwt库
pip install xlwt -i https://mirrors.aliyun.com/pypi/simple/
xlwt库写入表格内容
1 导入xlwt库
执行import xlwt导入该库
2 用一个图展示下xlwt常用的函数

3 往表格写入一些内容并保存(不设置样式)
# encoding:设置编码,默认是ascii,一般设置为utf-8,可支持中文;
#style_compression保持默认即可
work_book = xlwt.Workbook(encoding='utf-8')# 创建一个sheet对象,相当于创建一个sheet页,填入sheet页的名称
sheet_data = work_book.add_sheet('sheet1')# 向sheet页中添加数据:函数write,参数分别带入(行号,列号,填入的值),行和列从0开始。
#其中还有一个参数style=Style.default_style,用于设置字体/单元格格式/对齐方式等,不设置会使用默认值。
sheet_data.write(0,0,'username') # 第1行第1列写入数据 此处先不用样式,后面介绍
sheet_data.write(0,1,'age') # 第1行第2列写入数据 此处先不用样式,后面介绍
sheet_data.write(1,0,'章三') # 第1行第1列写入数据 此处先不用样式,后面介绍
sheet_data.write(1,1,'22') # 第1行第2列写入数据 此处先不用样式,后面介绍#保存为后缀为xls或者xlsx的excel表
#保存为xlsx时,后续的设置样式不会生效 所以我们保存为xls后缀文件
work_book.save('1.xls')程序执行后,与程序同目录相同的位置生成1个excel表格,打开后如下所示:
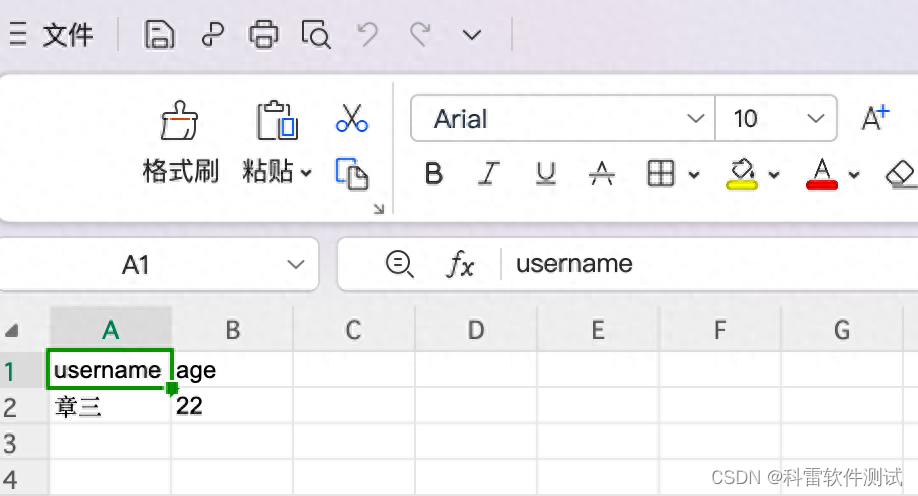
4 设置样式
上面提到write函数有个默认参数style=Style.default_style,而Style.default_style引用于xlwt下面的一个类Style.XFStyle

XFStyle 类中几个我们常用的属性:
- num_format_str 表示数据格式
- font 表示字体
- alignment 表示对齐方式
- borders 表示边框

1 先初始化XFStyle
style = xlwt.XFStyle()# 初始化样式2 设置字体font
因为xlwt的__init__.py文件已经从Formatting模块导入了Font类,我们直接通过xlwt.Font()定义字体样式
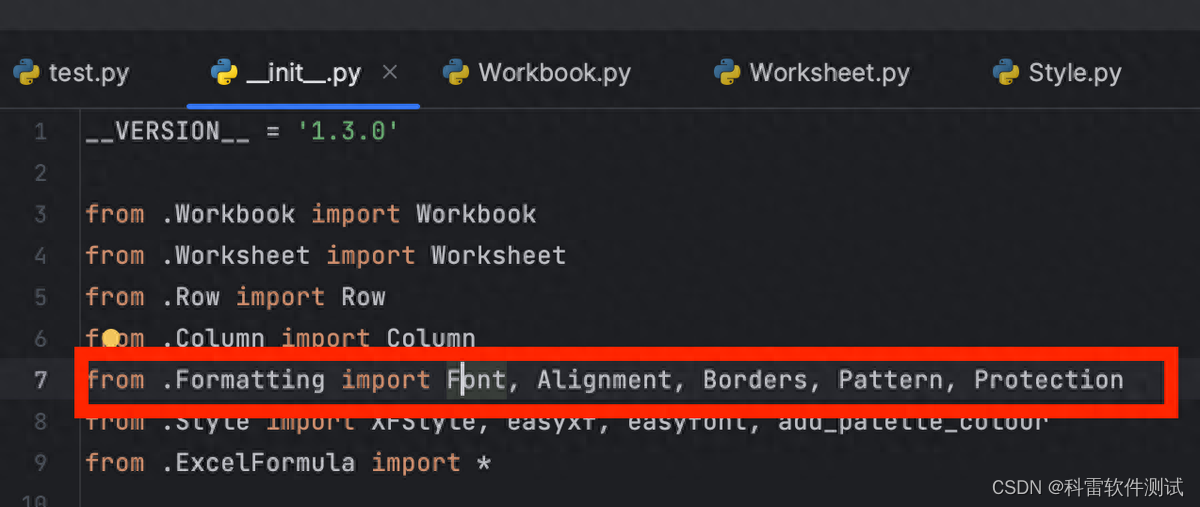
Font类初始化参数:
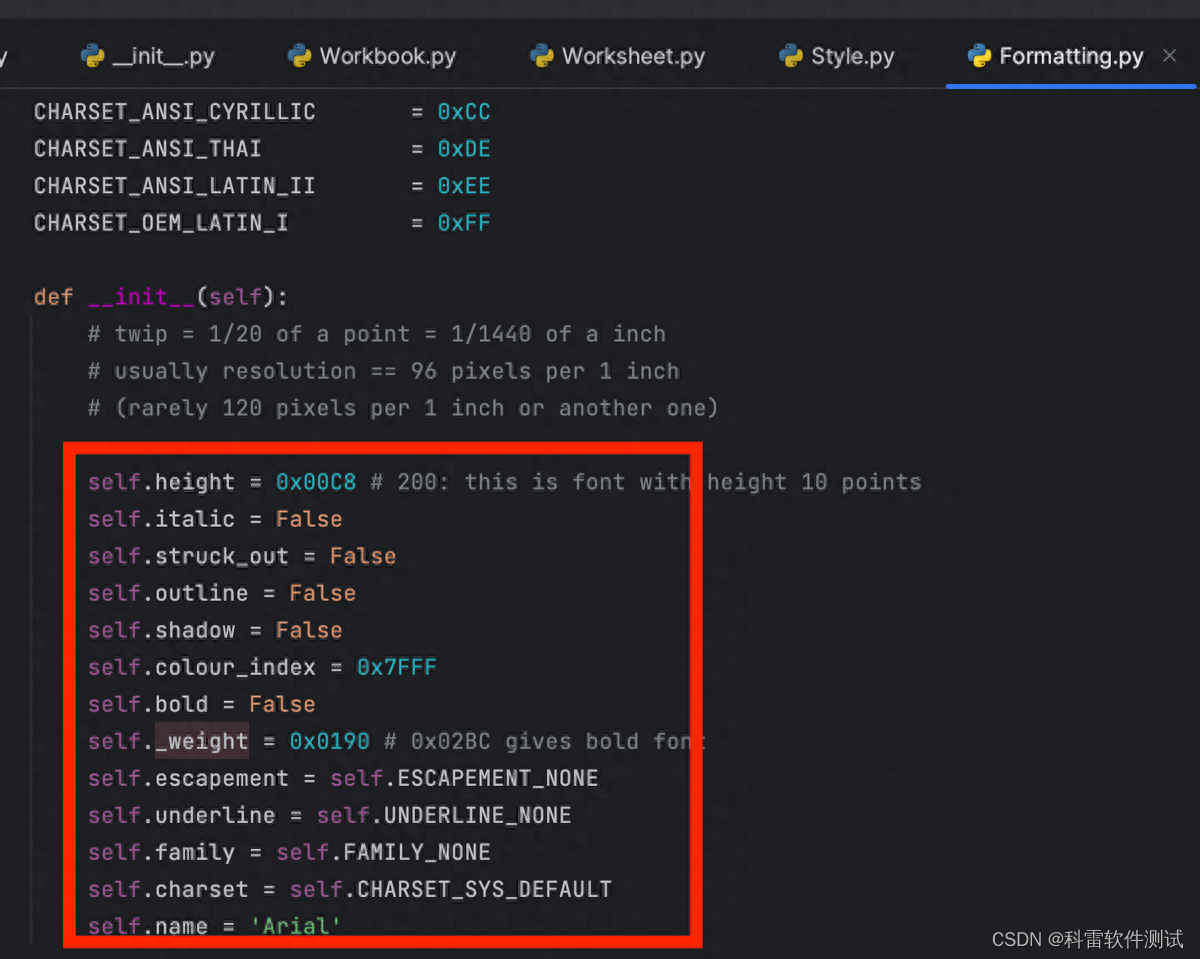
具体解释如下:
| height | 字体大小。默认值200代表字号10 (200也就是20*10,其中20为衡量单位,10为字号) |
| italic | 是否设置斜体。 |
| struck_out | 是否设置删除线。 |
| outline | 是否设置轮廓 |
| shadow | 是否设置阴影 |
| colour_index | 字体颜色 |
| bold | 是否设置加粗 |
| weight | 设置笔画宽度 |
| escapement | 是否设置为上下标 |
| underline | 是否设置下划线 |
| family | 设置字体集。 |
| charset | 设置字符集 |
| name | 设置字体名称 |
其中字体的颜色在style.py文件中找到一些设置值:
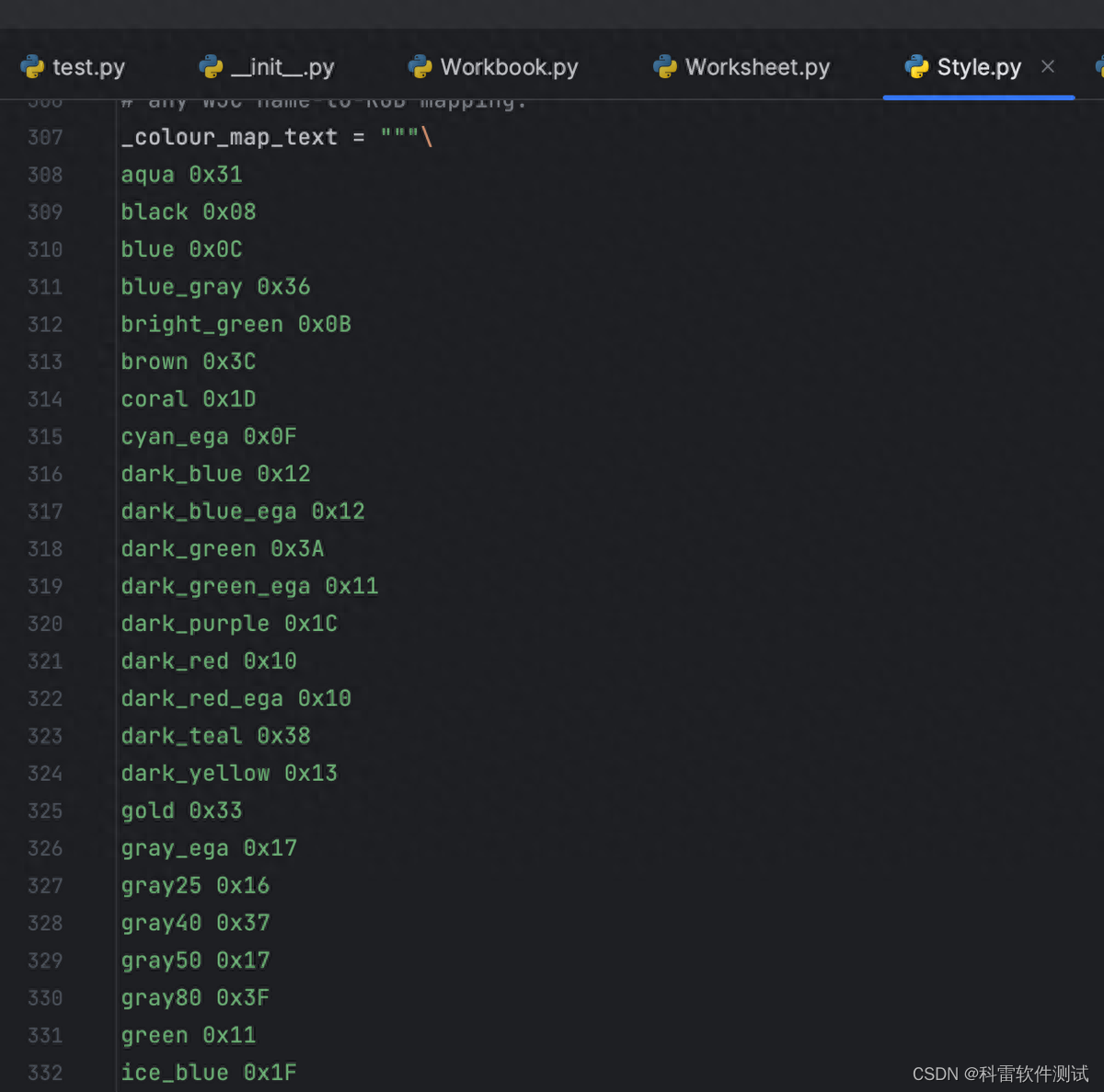
我们设置字体如下:
#为样式创建字体(font)
font = xlwt.Font()
# 指定字体的一些常用属性font.name = '宋' # 指定字体
font.height = 200 # 和excel字体大小比例是1:20
font.bold = True # 字体是否加粗
font.underline = True # 字体是否下划线
font.struck_out = True # 字体是否有横线
font.italic = True # 是否斜体字
font.colour_index = 0x3C # 字体颜色棕色
# 设定字体样式
style.font = font将write函数改为如下,重新执行,检查表格如下,字体设置已经生效
# 第1行第1列写入数据
sheet_data.write(0,0,'username',style=style)
# 第1行第2列写入数据
sheet_data.write(0,1,'age',style=style)
# 第1行第1列写入数据
sheet_data.write(1,0,'章三',style=style)
# 第1行第2列写入数据
sheet_data.write(1,1,'22',style=style)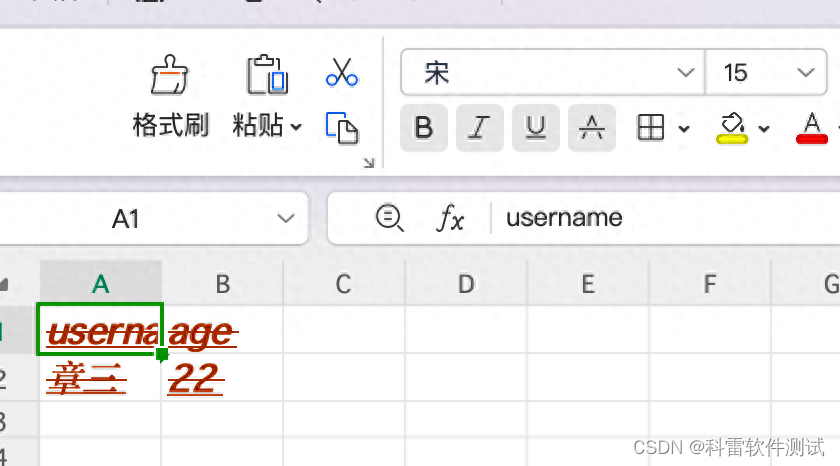

3 设置边框
跟设置字体一样,我们直接通过xlwt.Borders()定义边框样式。
Borders类初始化参数:
属性具体解释如下:
| left | 设置左边框 |
| right | 设置右边框 |
| top | 设置上边框 |
| bottom | 设置下边框 |
| diag | 设置对角线样式 |
| left_colour | 设置左边框颜色 |
| right_colour | 设置右边框颜色 |
| top_colour | 设置上边框颜色 |
| bottom_colour | 设置下边框颜色 |
| diag_colour | 设置对角线颜色 |
| need_diag1 | 设置是否显示左上-右下对角线 |
| need_diag2 | 设置是否显示左下-右上对角线 |
每个属性可以填的值在上面图中已经用红框标出。比如设置为粗实线,对应THICK(0x05)
我们设置边框如下:
#边框类初始化
borders = xlwt.Borders()
#定义属性值
borders.top = 0x04 #上边框样式
borders.bottom = 0x05 #下边框样式
borders.left = 0x06 #左边框样式
borders.right = 0x07 #右边框样式
borders.top_colour = 0x08 #上边框颜色
borders.bottom_colour = 0x36 #下边框颜色
borders.left_colour = 0x11 #左边框颜色
borders.right_colour = 0x12 #右边框颜色
borders.need_diag1 = 1 #设置显示左上-右下对角线
borders.diag = 0x02 #设置对角线样式
borders.diag_colour = 0x30 #设置对角线颜色
#赋值给样式
style.borders = borders
增加2行write函数如下,重新执行,检查表格如下,边框设置已经生效
# 第3行第3列写入数据
sheet_data.write(2,2,'',style=style)
# 第4行第4列写入数据
sheet_data.write(3,3,'',style=style) 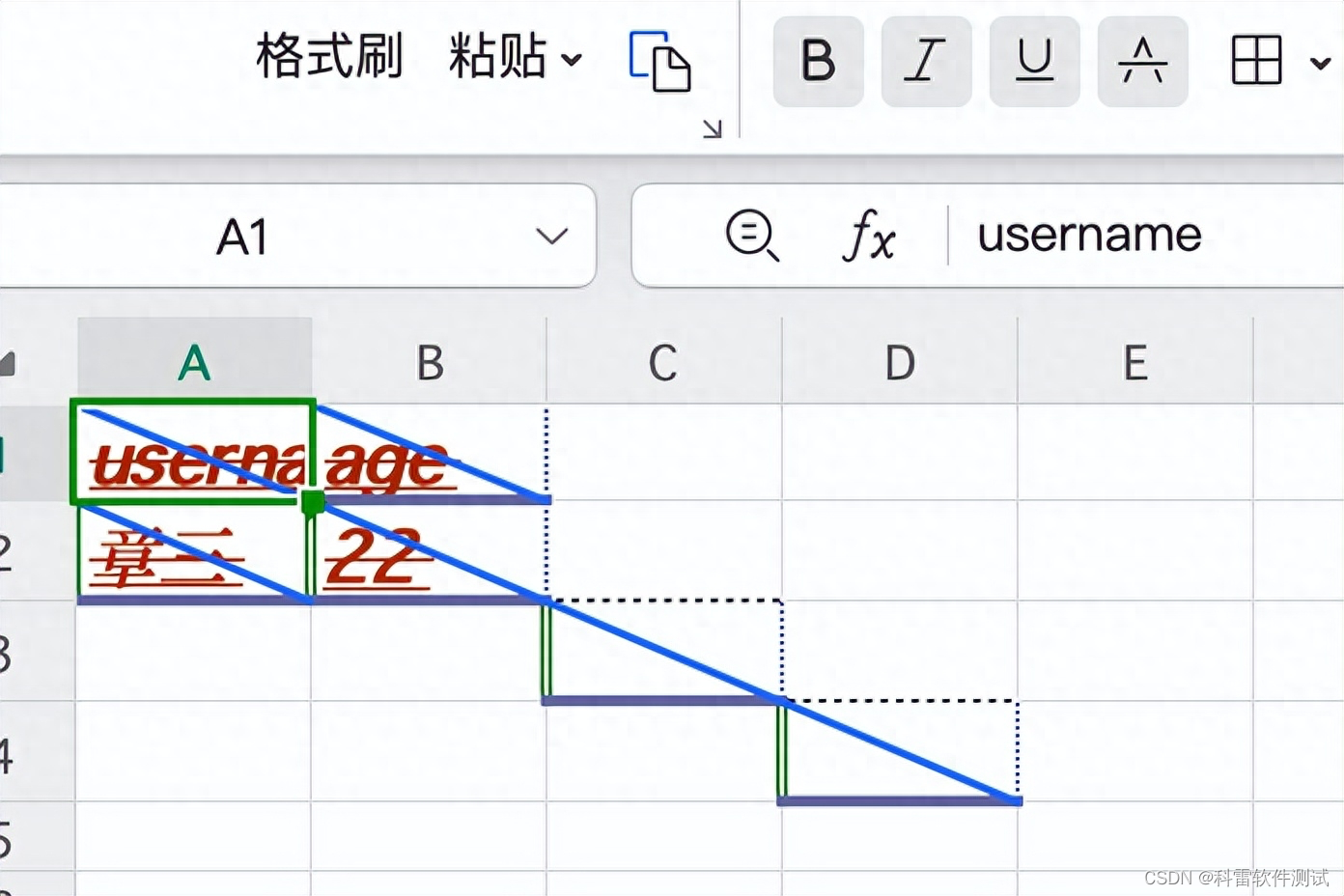
4 设置对齐方式
跟设置字体一样,我们直接通过xlwt.Alignment()定义对齐样式。
Alignment类初始化参数: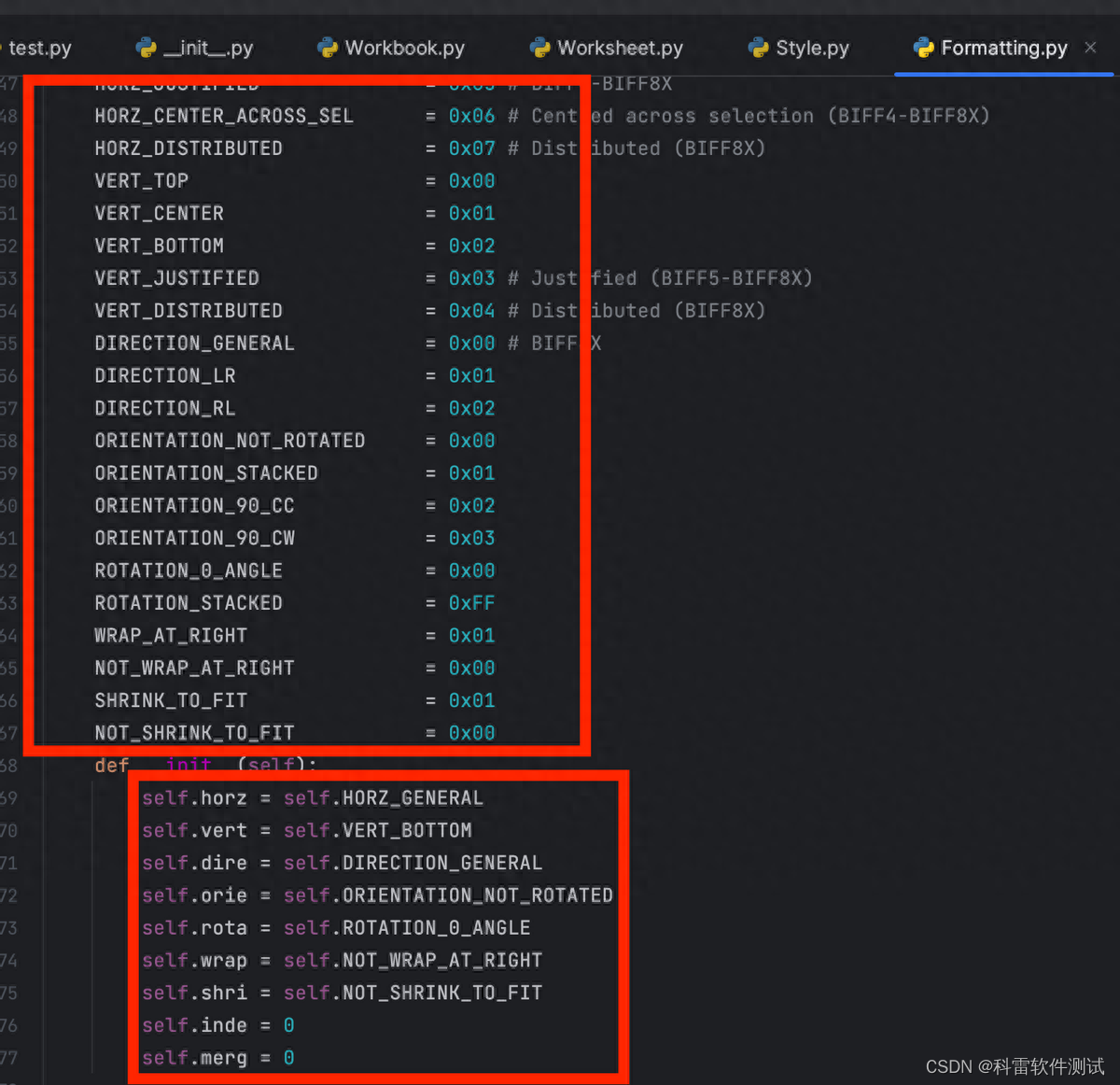
主要属性具体解释如下:
| horz | 设置水平对齐方式: 常规,左对,居中,右对齐,填充,两端对齐,跨列居中,分散对齐 |
| vert | 设置垂直对齐方式: 顶端对齐,垂直居中,底端对齐,两端对齐,分散对齐 |
| dire | 设置文字方向: 根据内容,总是从左到右,总是从右到左 |
| rota | 设置旋转方向 |
| wrap | 是否设置自动换行 |
每个属性可以填的值在上面图中已经用红框标出。比如设置文字垂直方向为靠上,对应VERT_TOP= 0x00
我们设置对齐如下:
#设置对齐方式
#对齐类初始化
alignment = xlwt.Alignment()
#定义属性值
alignment.horz = 0x02 # 设置水平对齐方式为居中
alignment.vert = 0x00 # 设置垂直对齐方式为靠上
alignment.wrap = 0x01 # 设置自动换行style.alignment = alignment增加3行write函数如下,重新执行,检查表格如下,对齐方式设置已经生效
# 第5行第5列写入数据
sheet_data.write(4,4,'1',style=style)
# 第6行第6列写入数据
sheet_data.write(5,5,'2',style=style)
# 第7行第7列写入数据
sheet_data.write(6,6,'ssssssssssssssss',style=style)

5 设置单元格
我们直接通过如下定义单元格格式
#设置单元格格式
style.num_format_str = '0.00' #数字保留2位小数单元格的格式在style.py文件中定义如下:
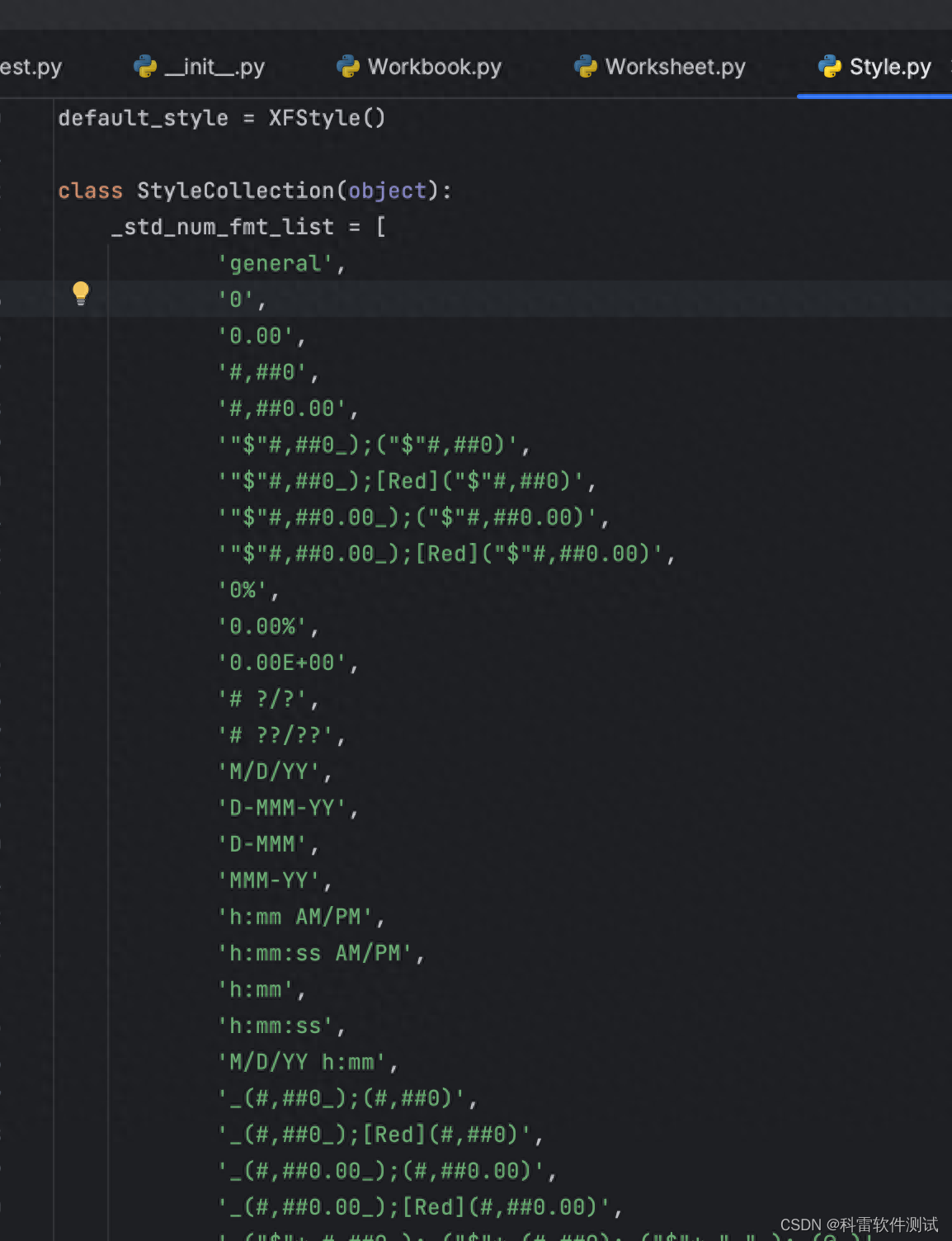
跟excel表中我们定义单元格格式中的自定义格式是一样的

增加1行write函数如下,重新执行,检查表格如下,数字已保留2位小数
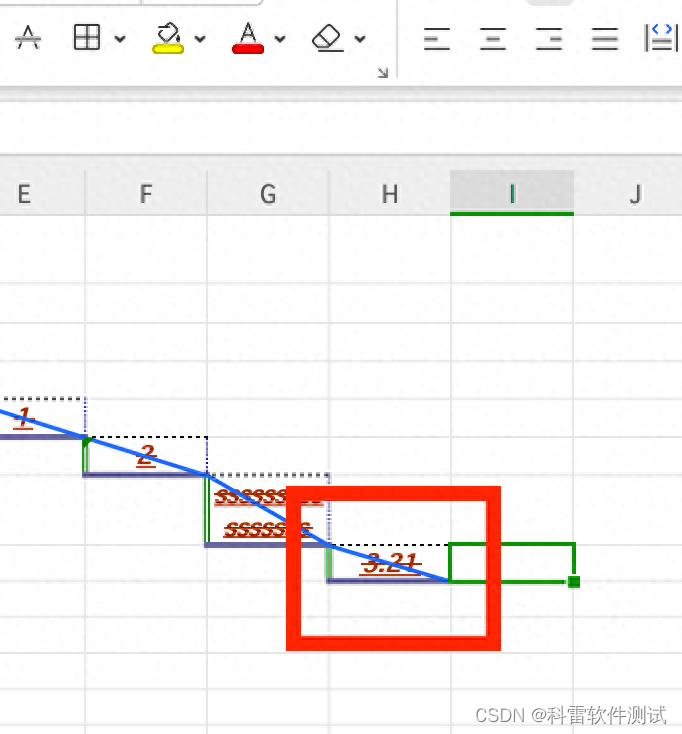
6 设置行高和列宽
work_book = xlwt.Workbook(encoding='utf-8')
# 创建一个sheet对象,相当于创建一个sheet页 填入sheet页的名称
sheet_data = work_book.add_sheet('sheet1')
#以上是上面提到的代码,在sheet对象中配置行高和列宽#在sheet对象中配置行高和列宽
#设置每一列的列宽 函数的参数为列号,从0开始
sheet_data.col(0).width = 256*20
#256为衡量单位,20表示20个字符宽度#设置行高
height_set = xlwt.easyxf(f'font:height {20*40}') #20是单位,40表示40px
sheet_data.row(0).set_style(height_set) #参数0代表第一行执行写入后,第1行第1列的行高和列宽已经设置成功
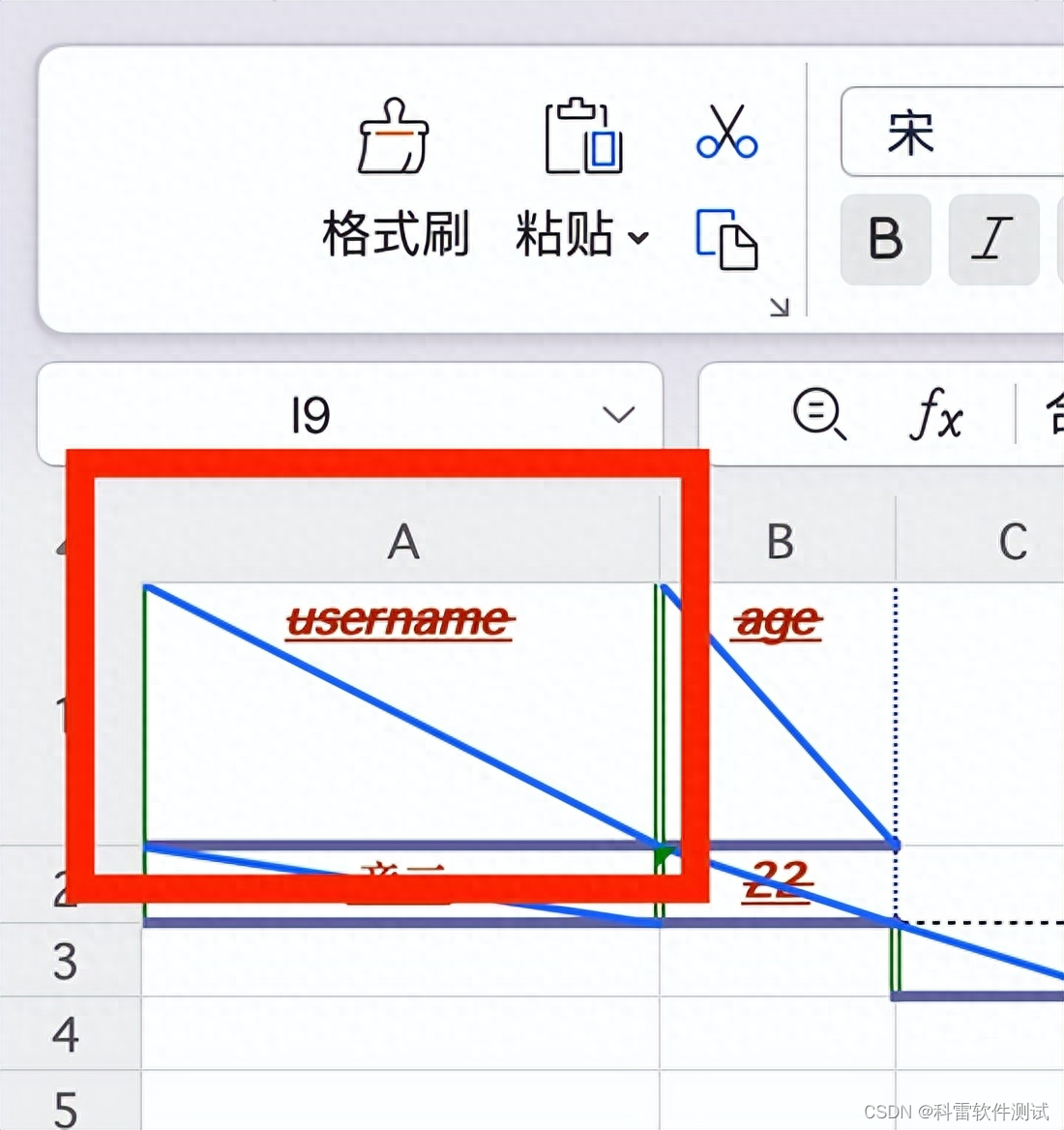
7 合并单元格
使用write_merge函数合并多个单元格,并写入内容
# 第8行到9行,第8列到第9列合并为一个单元格,写入数据
sheet_data.write_merge(8, 9, 8, 9, '合并数据')
执行写入后如下: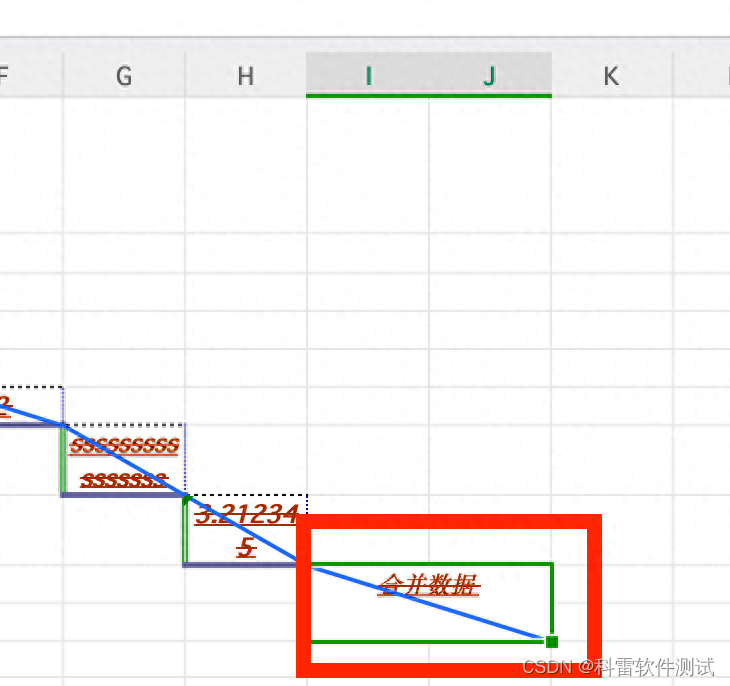
总结
在以上代码中,所有的wtite操作只用了一个样式,实际使用过程中,大家需要根据实际情况自己定义各类不同的样式。

----感谢读者的阅读和学习,谢谢大家。
共勉: 东汉·班固《汉书·枚乘传》:“泰山之管穿石,单极之绠断干。水非石之钻,索非木之锯,渐靡使之然也。”
-----指水滴不断地滴,可以滴穿石头;
-----比喻坚持不懈,集细微的力量也能成就难能的功劳。