广州南沙建设网站厦门网络推广推荐
1 引言
IPTV业务是伴随着宽带互联网的飞速发展而兴起的一项新兴的互联网增值业务,它利用宽带互联网的基础设施,以家用电视机和电脑作为主要终端 ,利用网络机顶盒(STB,Set -TopBox) ,通过互联网协议来传送电视信号.提供包括 电视节 目在 内的多种数字媒体服务 。IPrv简单来说就是交互式网络电视,它能为用户提供电信级的服务和使用简便的电视式体验。
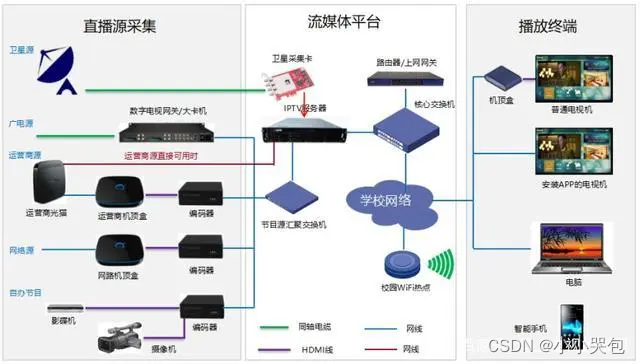
2 IPTV系统概述
到目前为止,IPTV虽然还没有一个十分明确的定义,但 IPTV实现电视的网络化却是不容置疑的,它的具体表现形式一定是基于IP网 的流媒体服务。整个IPTV系统的中心任务是如何为用户提供流媒体服务。围绕这个问题,必须充分考虑电信级系统所必要的一些保证体系。如运营支撑系统、网络管理系统等。一般认为IPTV系统在逻辑上可以划分成五个部分:媒体处理子系统、媒体管理 子系统 、电子节目单服务子系统、运营支撑子系统、流服务子系统。另外,为 了更加直观地展现 系统的协同工作情况,还可以根据设备的功能。将系统的相关组件按照功能划分为以下四个部分:媒体平台层服务支持层、运营支撑层、终端层。实际上,完整的IPTV系统还应该包括IP承载层。虽然IPTV系统的运作和IP承载层息息相关,但IP承载层并非IPTV系统独有的,只是IPTV系统对其有一些相对特殊的要求,例如对组播的支持、高带宽的需 求等.所以本文中将不对其做详细介绍。
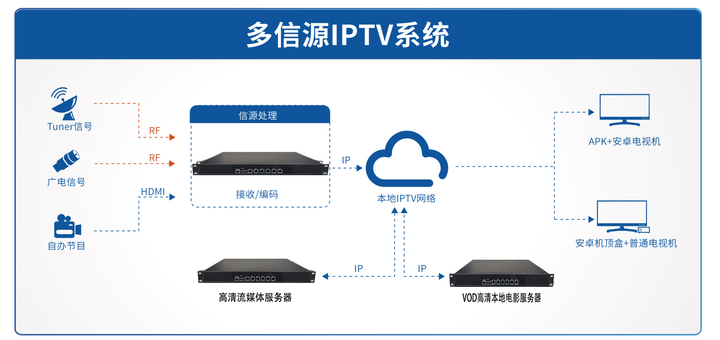
3 IPTV系统逻辑结构
(1)流服务子系统流服务子系统是为用户直接提供流服务的子系统。是系统 的核心。无论是视频点播,还是直播电视,或者其他的增值业务,IPTV系统最终都将通过流服务子系统来提供服务。终端总是和流服务子系统进行流媒体的交互。其他的子系统都是直接或间接地为流服务子系统提供服务的。流服务子系统对整个流媒体的服务提供保障,它是系统的关键逻辑组件,其他的相关子系统都是为其服务的,并围绕其设计的。
(2)媒体处理子系统媒体处理子系统的主要任务是将原始的节目源转化成符合规定编码格式的流媒体节目源。原始的节目源可能是电影的拷贝,也可能是DVD片。还可能是数字或者模拟的视音频信号源(数字电视或者模拟电视信号源),媒体处理子系统的任务是将它转化成适合在互联网上传输的视音频格式的文件,用的编码格式必须是压缩编码方式.例如MEPG一4、WMV或者H.264等,今后的趋势是采用统一的H.264编码格式。当然系统对于其他格式的媒体文件也都是可以兼容的,关键是终端要支持相应的解码程序。媒体处理子系统本质上就是媒体进入到IPTV系统的入口。无论是TV节目。还是电影节目,都需要通过这一子系统处理后方可进入系统。之后才有可能为IPTV的用户提供相关的流媒体服务的资源。
(3) 媒体管理子系统
媒体管理子系统的主要任务是对媒体资源进行管理。包括媒体的内容管理、计划的编排、EPG信息的采集与生成、报表信息的采集与生成。媒体的内容管理,包括媒体内容通过什么策略来进行存储和分发,比如在系统中如何保存、存储多少份拷贝、位置信息如何索引等,是关系到媒体存储和分发效率的关键因素,也是设备厂家重点考虑的问题之一。计划的编排,一般和TV节目相关,如果系统要提供时移电视的功能,必然要对电视节目进行录制,那么计划的编排目的就是为将来要进入存储区域的这些内容按时间段进行分割,时间段的划分一般基于电视台的节目表,这样可以保证这些文件在时移电视点播的时候,可 以按时段和节目名称进行点播,按时间收看电视节目。EPG信息的采集和生成.一般是通过媒体内容来定制EPG画面,这样可以控制哪些媒体节目出现在EPG界面,可以为用户所使用,同时,它们可以根据一些编排计划。在界面中生成相关的节目单,这个就有点类似与传统电视的电视节目预告,它是EPG画面的资源。根据点播情况它可以生成热门影片列表,根据节目导入系统的时间可以生成最新影片列表。报表的信息采集与生成,可以理解成通过对媒 体资源的状态、使用情况等数据库进行统计的一些情况,它的主要目的是通过查询数据库生成指定格式的报表文件,以供运营者进行相关的分析。比如,它可以提供影片的点击频率从 而可以制定策略,使点击多的影片在系统中增加拷贝的数量。以保证为用户提供 更优质的服务,而点播次数少的。则可以减少系统的拷贝数量,提高磁盘空间的利用率。
(4)电子节目单服务子系统电子节目单服务子系统的主要任务是为用户提供业务的入口服务,是直接呈现给用户的界面,是供用户选择的系统服务索引,它同时要协助完成用户的接入请求。电子节目单子系统呈现给用户的是在某些权级下,可以享受到的服务。比如,如果是包月用户,那么电子节目单服务子系统将把所有的提供给包月用户的媒体资源以页面的方式呈现给该用户,用户也可以通过各种关键字进行查询。当然,用户也可以通过增加付费的方式,选择超出服务范围的媒体或服务资源。或者,在用户的服务范围内,用户还可以自行控制。对一些不适合儿童观看的影片进行密码保护,阻止儿童观看。
(5)运营支撑子系统运营支撑子系统是为运营商的运营管理服务的系统,包括用户管理、计费管理、定价策略管理、网络设备管理以及运营相关的一些管理工作。这部分无论是对增值业务运营商还是电信运营商都非常重要,一方面它管理着为用户提供服务的这些服务器和网络资源,另一方面它需要对相关服务的资费策略进行定制。资费管理功能的强弱。通常对于运营商的业务竞争力有很大影响,支持的策略越多样化,越能吸引更多的需要,同时适应市场竞争策略的变化,比如临时打折、业务捆绑。与此同时,一般它还会管理用户的资料,比如用户的开户、资料管理、状态变更,能够设定一些阀值来使系统自动开关用户的业务,避免用户的恶意欠费。在运营支撑系统中,运营商还希望能够对第三方的~些网络设备进行管理(一般来说.现在的系统是综合的系统,多厂家设备的融合是非常普遍的现象),还有可能要求和原有的一些前台应用系统和后台营账系统进行一些自动数据传递的接口功能,从而实现平台的统一运营支撑系统与客户的一些使用习惯相关,与相关业务相关,正是因为个性化的原因,一般运营商会根据要求进行一些定制,采用一些开放式的架构,可以方便地进行相关模块的定制,满足各种个性化的要求。
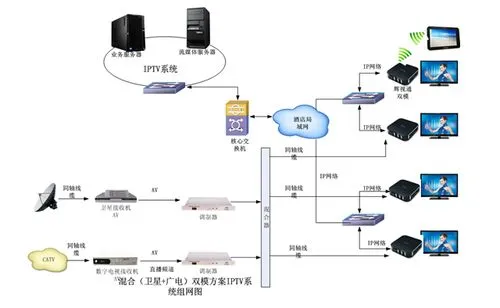
4IPTV系统功能结构
前面介绍过。IPYV系统按照功能结构可以分为媒体平台层、服务支撑层、运营支撑层和终端层。但实际上,系统的分层结构根据对业务模型的构建的不同和实现方式的不同,会有所不同,平台之间的功能只有模糊的差异,并没有清晰的界限,比如说,内容编码服务器到底属于媒体平台层还是服务支持层,就存在分歧:而网络管理系统属于运营支撑层还是属于服务支持层,也会有不同的声音。明确地界定这些层所包含的设备,依赖于系统架构工程师,并和系统的相关业务流程息息相关,在这里只做了一些共性的探讨。
( 1 )媒体平台层
媒体平台层一般主要由一些和媒体相关的服务器组成。就目前提供的相关服务,主要包括媒体存储和分发的媒体工作站(有些厂家也称之为流媒体服务器),媒体编码加密和导人的内容工作站。考虑到今后的业务扩展,还会增加更多的内容,比如说如果增加网络可视电话业务,必然还要增加相关的服务器来负责可视电话业务的媒体流处理;如果增加网络游戏服务,还需要相关的游戏服务器来处理相关事务。
(2) 服务支持层
服务支持层。也称作在线业务支持层,一般可以采用分布式结构位于中心机房和城域网机房。其主要的任务是对IPTV相关服务进行控制:一方面是保证合法用户可以通过正常的渠道得到相关的服务,对用户进行认证和授权;另一方面,通过认证和授权措施来防止非法用户接人系统。一般来说,服务支持层包括所有的和媒体服务相关的一些服务器,主要包括DRM系统(包括许可服务器和其他的对密钥进行引用和控制的组件)、客户自服务服务器、网络管理服务器、媒体引人系统的一些 内容编码服务器、认证服务器、EPG服务器等。DRM系统主要用于流媒体的数字版权管理,许可服务器主要用于License的分发,认证服务器主要用于用户 的业务接人认证。其他的服务器都是为用户的媒体服务提供在线的支持。
(3)运营支撑层
运营支撑层,也称作后台服务支持层,一般位于用户的数据中心和网络管理中心。它是为业务运营和网络管理服务的,是运营商的业务管理和控制的核心平台,要适应不同的运营模式和管理风格,通常情况下要考虑更多的业务模型、管理模型等方面, 运营商一般还会提出很多定制性的要求。一般主要包括客户管理、计费账务管理和媒体资产管理这几个相对独立的模块。一般来说,这三部分都是OSS的功能模块。OSS是一个为运营商进行节目管理、工作流管理、用户管理、计费及账务、用户自助服务的可伸缩、可扩展的业务支撑平台。同时,它提供各种后台解决方案,如用户管理、业务管理、资费政策管理、销账处理、营收管理、结算分摊、数据分析等功能。
(4)终端层
EPG的客户端软件、解码设备(支持MPEG一1/2/4、WMV、REAL、H.264等格式)、媒体播放器与系统中的服务器进行交互从而控制媒体服务的进程,并且通过STB将媒体流数据转换为Tv终端支持的视频信号。未来还将包括手机等终端。终端层是整个系统用于和用户交互的平台,也是呈现在用户侧的惟一设备,其设计除了考虑技术层面,还要考虑很多因素,比如经济性、 美观性等。终端层的主要设备一般是机顶盒。当然,如果是 PC用户,只需要一套支持解码和播放技术的软件就可以了,可以认为它是一个软件机顶盒。
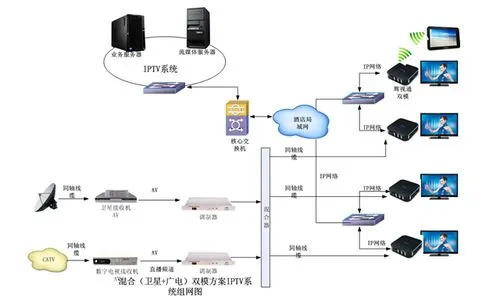
5 结语
IPTV系统是构建在现有互联网上的业务系统,它必须适应现有的IP网络构建,这样才能保证系统的可靠性和稳定性。一般来说,IPTV的网络是一个分层的网络结构,分为骨干网层、城域网层和接人网层,IPTV系统的部署一般也和这种分层结构相吻合。
(1)数据中心位于骨干层,部署相应的OSS和网管系统,同时些内容编码服务器、中心媒体服务器以及相应的服务支持层功能实体可以集中部署在这里。如果网络规模大,也可以将部分组件分布式部署延伸到城域网。
(2)分布式的媒体工作站可以位于城域网层或者接人网层,取决于网络的规模,初期可以位于城域网,后期可以在城域网和接人网分层部署。
(3)终端设备位于接人网中。这样的结构可以有效利用现有的各种网络资源,加快部署的速度,保证低成本地部署系统的同时还可以确保系统的可扩展性。
IPTV系统是一种基于宽带网络的新型增值业务平台,伴随着互联网技术的发展,必然会不断发展,虽然其逻辑结构不会发生大的改变,除非互联网的架构发生大的改变,但逻辑架构下的功能模块必然会随着业务的发展而改变,适应用户需求的功能会不断被开发出来,IPTV业务也将在不断的业务创新中不断发展,在个性化的家庭娱乐中占据一席之地.为用户打造一个全新的娱乐甚至商务平台。