网站推广seo设置网站建设总体流程
原文地址:librdns一个开源DNS解析库 – 无敌牛
欢迎参观我的个人博客:无敌牛 – 技术/著作/典籍/分享等
介绍
librdns是一个开源的异步多功能插件式的解析器,用于DNS解析。
源代码地址:GitHub - vstakhov/librdns: Asynchronous DNS resolver
librdns使用libev和libevent的方式集成,来实现异步操作。
关于DNS相关知识参看往期文章:DNS记录这件小事 – 无敌牛
关于libev的介绍参看往期文章:libev监听IO事件 – 无敌牛
编译安装
下载源文件,指令:git clone https://github.com/vstakhov/librdns.git
编译,先进入拉取的源代码目录,然后执行:mkdir build && cd build && cmake .. && make -j 5

安装,主要是把编译后的so库和需要引用的头文件拿到系统目录。执行指令:cp lib* ../include/* /usr/local/include/。然后重新加载系统动态库 ldconfig

测试示例
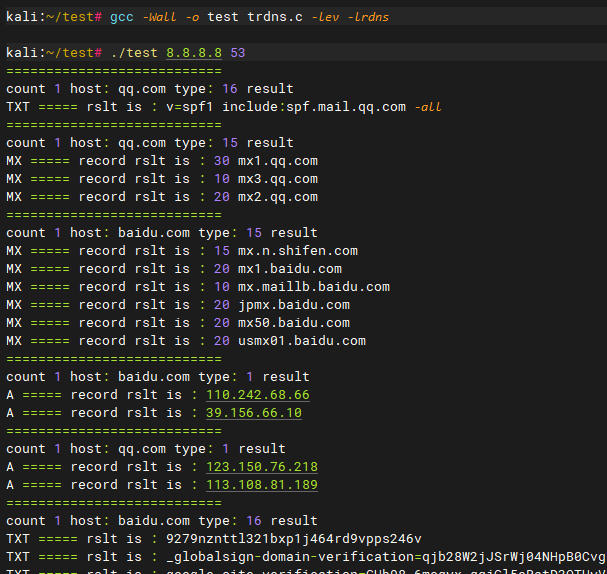
在 librdns 源代码里已经有两个测试文件,我这里做了一些修改,把获取到的数据打印了出来。代码如下:
trdns.c
// gcc -Wall -o test trdns.c -lev -lrdns#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>#include "rdns.h"
#include "rdns_curve.h"
#include "rdns_ev.h"#define LL_FOREACH_SAFE(head,el,tmp) \LL_FOREACH_SAFE2(head,el,tmp,next)#define LL_FOREACH_SAFE2(head,el,tmp,next) \for((el)=(head);(el) && (tmp = (el)->next, 1); (el) = tmp)static int remain_tests = 0;static void
rdns_regress_callback (struct rdns_reply *reply, void *arg)
{// 获取有多少个查询项unsigned int count ;const struct rdns_request_name* names = rdns_request_get_name (reply->request, &count);for( int i=0 ; i < count ; ++i ) {printf ("===========================\ncount %d host: %s type: %d result\n", count, names[i].name, names[i].type ) ;}// 判断是否获取DNS成功if(reply->code != RDNS_RC_NOERROR) {printf("failed code : %d\n", reply->code) ;if (--remain_tests == 0) {rdns_resolver_release (reply->resolver);}return ;}// 遍历返回的结果实体struct rdns_reply_entry *entry, *tmp ;LL_FOREACH_SAFE (reply->entries, entry, tmp) {switch (entry->type) {case RDNS_REQUEST_MX : // MX 结果printf("MX ===== record rslt is : %u %s\n", entry->content.mx.priority , entry->content.mx.name ) ;break ;case RDNS_REQUEST_A : // A 结果char ip_str[16] ;inet_ntop(AF_INET, &entry->content.a.addr, ip_str, sizeof(ip_str) ) ;printf("A ===== record rslt is : %s\n", ip_str) ;break ;case RDNS_REQUEST_TXT : // TXT 结果printf("TXT ===== rslt is : %s\n", entry->content.txt.data) ;break ;default :printf("wrong type : %u\n", entry->type) ;}}if (--remain_tests == 0) {// 减少 DNS解析服务器的引用,如果 为 0 则释放空间 // 同时会停止 libev 的 loop 循环rdns_resolver_release (reply->resolver);}
}static void
rdns_test_a (struct rdns_resolver *resolver)
{char *names[] = {"baidu.com","163.com","qq.com",NULL};char **cur;for (cur = names; *cur != NULL; cur ++) {// 增加检测结果回调函数// 参数: DNS解析句柄、解析结果回调函数、回调函数参数、DNS查询超时时间(单位:秒)、失败重复查询次数、总共要做多少个查询、请求值、类型、请求值、类型...// 坑:当添加多个查询的时候,会超时,所以这里一个一个添加rdns_make_request_full (resolver, rdns_regress_callback, NULL, 5.0, 2, 1, *cur, RDNS_REQUEST_A );remain_tests++ ;rdns_make_request_full (resolver, rdns_regress_callback, NULL, 5.0, 2, 1, *cur, RDNS_REQUEST_MX);remain_tests++ ;rdns_make_request_full (resolver, rdns_regress_callback, NULL, 5.0, 2, 1, *cur, RDNS_REQUEST_TXT);remain_tests++ ;}
}int
main(int argc, char **argv)
{struct rdns_resolver *resolver_ev;struct ev_loop *loop;// 创建 libev 监听轮询 loop 句柄loop = ev_default_loop (0);// 创建 DNS 解析器结构resolver_ev = rdns_resolver_new ();// 绑定 libev 的 loop 和 resolver_evrdns_bind_libev (resolver_ev, loop);// 增加 DNS服务器信息 : argv[1] IP地址 argv[2] 端口号rdns_resolver_add_server (resolver_ev, argv[1], strtoul (argv[2], NULL, 10), 0, 8);// 初始化 DNS 解析器rdns_resolver_init (resolver_ev);// 添加测试rdns_test_a (resolver_ev);ev_loop (loop, 0);return 0;
}编译测试
指令:gcc -Wall -o test trdns.c -lev -lrdns