门户网站免费奖励自己建网站需要什么条件
近年来,随着5G网络和云计算技术的不断发展,交互式3D实时云看车正在成为一种新的看车方式。
与传统的到4S店实地考察不同,消费者可以足不出户,通过网络与终端设备即可实现全方位展示、自选汽车配色、模拟效果、快捷选车并进行个性化定制。3DCAT实时云渲染作为一家专注于为汽车行业提供3D交互式看车解决方案的公司,正在助力交互式3D实时云看车的发展。
基于以上的趋势和技术变化,3DCAT实时渲染云与著名汽车品牌一汽奥迪达成了深度合作,为一汽奥迪官网线上个性化订车提供实时云渲染展示解决方案。
消费者可以根据“云看车”交互式展示,在线观看在售车型的全方位展示、自选汽车配色,模拟效果、快捷选车并进行个性化定制。这项合作使得消费者足不出户便可亲临4S店现场,享受到更加便捷和高效的购车体验。

打开后点击右下角3D图标体验
01 3DCAT超强算力+超高安全性=一汽奥迪官网个性化订车流畅稳定运行
3DCAT实时渲染云将基于游戏开发引擎制作的超高清可交互三维可视化汽车内容进行云端计算渲染,并通过网络及串流技术,实时推送到终端,满足广大购车群体随时随地跨终端、可交互、超高清、沉浸式的访问需求。这项技术将极大地助力交互式3D实时云看车达到超清、流畅、沉浸式的用户体验。
数万台分布式服务器从任务发布到队列处理均由自研集群调度系统-MUNU完成,支持多平台混合使用,历经自身多年生产检验,贴合云端应用复杂多变的需求,实现灵活构建,轻松运维。3DCAT能够为用户提供更加流畅、更加真实的渲染效果,从而更好地展示出汽车的美感和品质。

3DCAT四大优势和特点
3DCAT的超高安全性为一汽奥迪官网汽车云渲染服务保驾护航,3DCAT将内容存储在云端,用户与应用数据隔离,能够在保证高效的同时,确保客户数据的保密性和隐私性。此外,3DCAT还获得TPN权威认证并使用了多层次的安全防护机制,包括防火墙、访问控制、数据加密等技术,为汽车行业的数字化转型保驾护航。
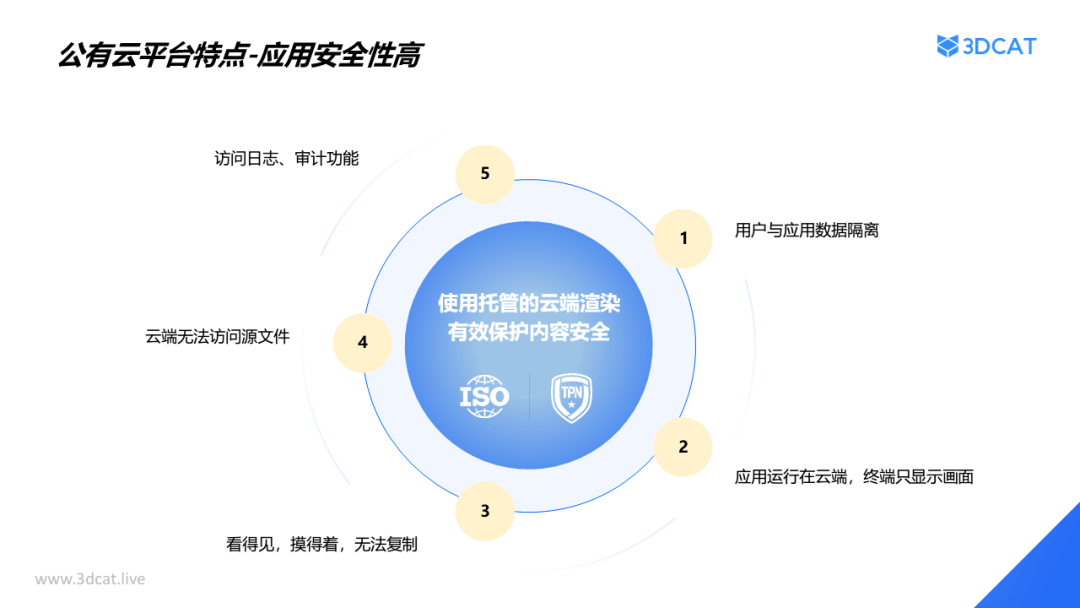
3DCAT应用安全性高
02 3DCAT引领汽车数字化创新与变革
随着科技的不断进步,汽车行业也在不断地发展和变革。从传统的售车方式到现在的数字化展示和个性化定制,汽车行业正在通过技术创新和数字化转型,实现更加高效、便捷、智能的服务和产品。而3DCAT实时云渲染技术,则是这种数字化转型的重要组成部分,它通过高品质的云计算和串流技术,为汽车行业的3D交互式看车提供了全新的解决方案,实现了跨终端、可交互、超高清、沉浸式的访问需求。
在未来,随着5G网络、云计算技术的不断发展和普及,3DCAT实时渲染云将在汽车行业发挥越来越重要的作用。同时,随着人们对数字化生活的需求不断增长,数字化展示和个性化定制也将成为汽车行业的重要趋势,而3DCAT实时云渲染技术则将为汽车企业提供更加高效、智能、个性化的解决方案,帮助汽车行业实现可持续发展和进步。