河北手动网站建设商店代理记账公司收费表
每一个 Android App 中都会使用到 Bitmap,它也是程序中内存消耗的大户,当 Bitmap 使用内存超过可用空间,则会报 OOM。
Bitmap 占用内存分析
Bitmap 用来描述一张图片的长、宽、颜色等信息,可用使用 BitmapFactory 来将某一路径下的图片解析为 Bitmap 对象。
当一张图片加载到内存后,具体需要占用多大的内存?
getAllocationByteCount 探索
我们可用通过 bitmap.getAllocationByteCount() 方法获取 Bitmap 占用的字节大小。比如以下代码
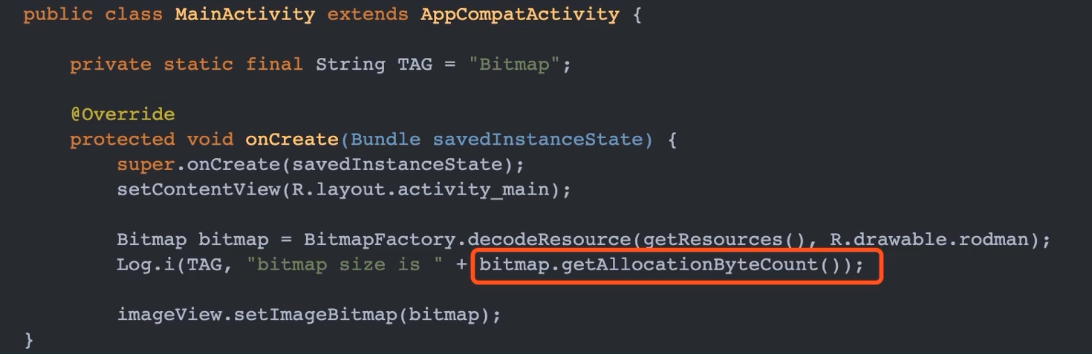
上图中,rodma 是保存在 res.drawable 目录下的一张 600x600 、大小为 65KB 的图片。 打印结果如下

默认情况下,BitmapFactory 使用的 Bitmap.Config.ARGB_8888 的存储方式来加载图片内容。在这种存储模式下,每个像素占用4个字节(ARGB_8888代表A占8bit,R占8bit,G占8bit,B占8bit)。因此,上面图片 rodman 的大小可用使用如下公式计算:
宽 x 高 x 4 = 600 x 600 x 4 = 1440000 Byte
所以,一张图片占用的内存大小的计算公式为:宽 x 高 x 单位像素所占字节数。
屏幕自适应
在保证代码不修改的前提下,将图片 rodman 移动(注意不是拷贝)到 res/drawable-hpdi 目录下。重新运行代码,则打印日志如下:

可用看出,我们只是移动了图片的位置,Bitmap 所占用的内存竟然上涨了,这是为什么呢?
BitmapFactory 在解析图片的过程中,会根据当前设备屏幕密度和图片所在的 drawable 目录来做一个对比,根据这个对比值进行缩放操作。
具体公式为:
缩放比例 scale = 当前设备屏幕密度 / 图片所在 drawable 目录对应的屏幕密度。
Bitmap 实际大小 = (宽 * scale) x (高 * scale) x 单位像素所占字节数
在 Android 中,各个 drawable 目录对应的屏幕密度
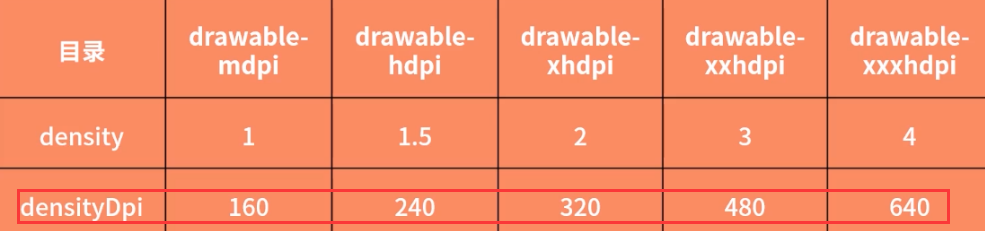
运行的设备是 Nexus4,屏幕密度为320,如果将 rodman 放到 drawable-hdpi 目录下,最终的计算公式如下
Rodman 实际占用内存大小 = [600 * (320 / 240)] * [600 * (320/240)] * 4 = 2560000
assets 中的图片大小
Android 中的图片不仅可以保存在 drawable 目录中,还可以保存在 assets 目录下,然后通过 AssetManager 获取图片的输入流。
这种方式加载生成的 Bitmap 是多大呢?
同样是上面的 rodman.png,这次把它放到 assets 目录中,然后用如下代码加载
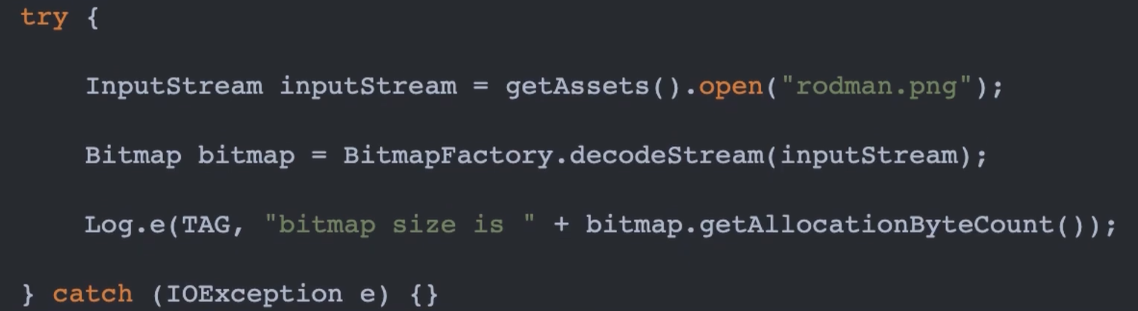
最终打印结果为

可以看出加载 assets 目录中的图片,系统并不会对其进行缩放操作。
Bitmap 加载优化
一张 65Kb 大小的图片被加载到内存后,占用了 2560000 个字节,也就是 2.5M 左右。适当时候,需要对加载的图片进行缩略优化。
修改图片加载的 Config
使用占用存储空间少的占用方式,可以快速有效降低图片占用内存。比如通过 BitmapFactory.Options.inPreferredConfig 选项,将存储方式设置为 Bitmap.Config.RGB_565。在这种存储方式中,一个像素占用2个字节。所以最终占用内存直接减半。
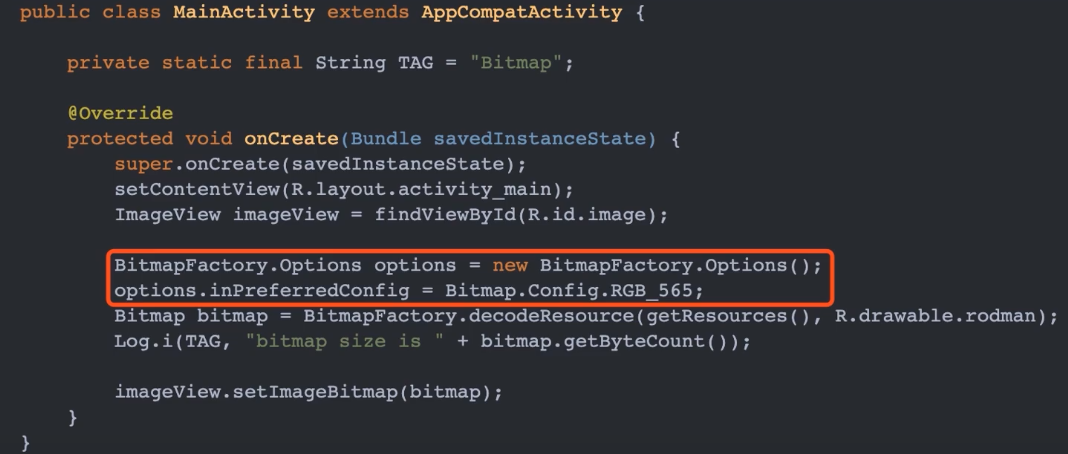
打印结果如下

Bitmap 复用
场景描述:如果在 Android 某个页面创建很多个 Bitmap,比如有两张图片 A 和 B,通过点击某一按钮,需要在 ImageView 上切换显示这两张图片。可以使用以下代码实现上述效果
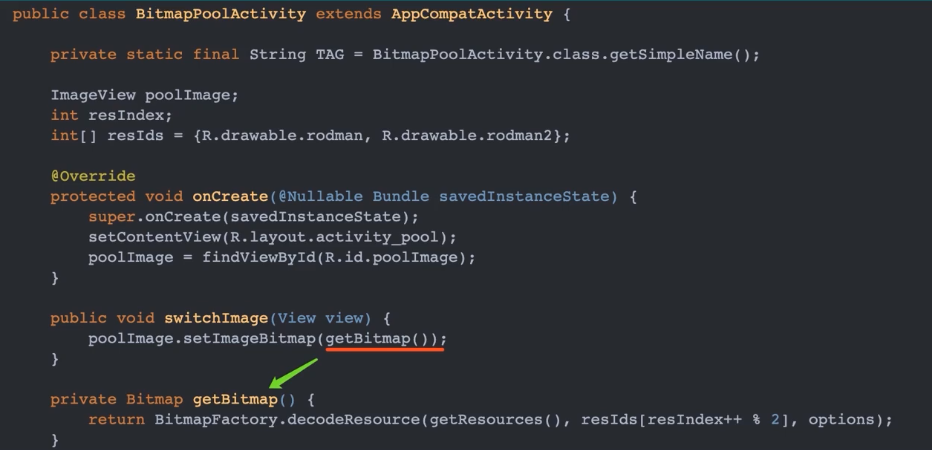
每次调用 switchImage() 切换图片时,都需要通过 BitmapFactory 创建一个新的 Bitmap 对象,当方法执行完之后,这个 Bitmap 对象又会被 GC 回收。这就造成不断创建和销毁比较大的内存对象,从而导致频繁 GC,即内存抖动。
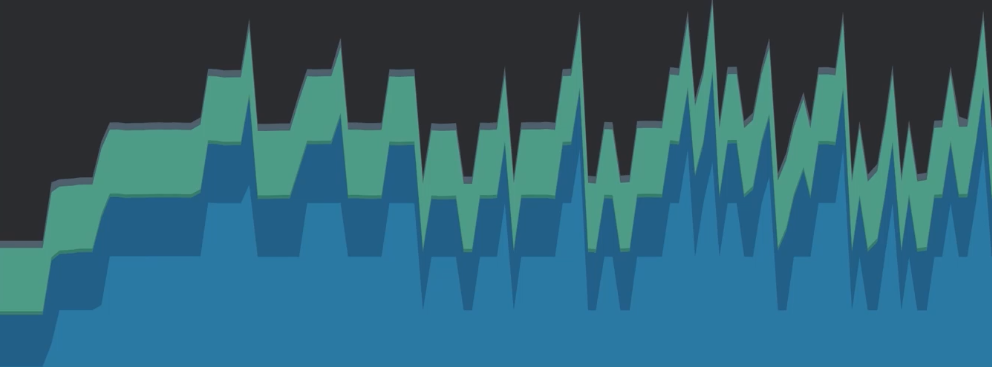
像 Android App 这种最终面向用户的产品,如何因为频繁的 GC,造成 UI 界面卡顿,还是会影响到用户体验的。可以在 Android Studio Profiler 中查看内存情况,多次切换图片后,显示的效果如下:
使用 Options.inBitmap 优化
实际上经过第一次显示之后,内存中已经存在了一个 Bitmap 对象,每次切换图片只是显示的内容不一样。我们可以重复利用已经占用内存空间的 Bitmap,具体做法就是使用 Options.inBitmap 参数,将 getBitmap() 方法修改如下
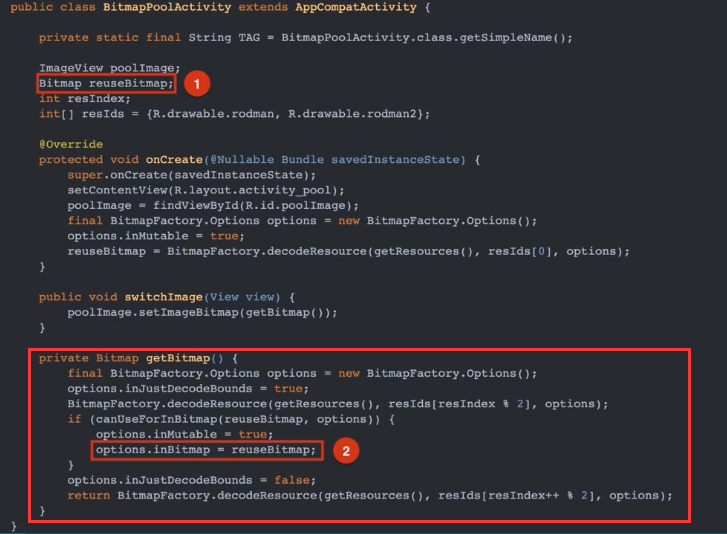
图中1处创建一个可以用来复用的 Biamap 对象;图中2处将 options.inBitmap 复制为之前创建的 reuseBitmap 对象,从而避免重新分配内存。
重新运行代码,并查看 Profiler 中的内存情况。可以发现,不管我们切换图片多少次,内存占用始终处于一个水平线状态。

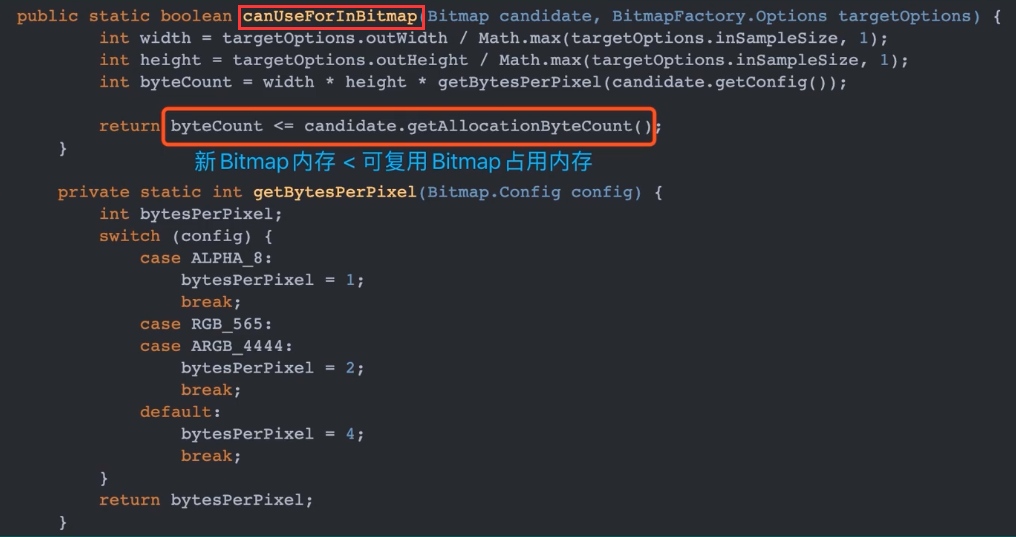
注意:在上述 getBitmap 方法中,复用 inBitmap 之前,需要调用 canUseForInBitmap 方法来判断 reuseBitmap 是否可以被复用。这是因为 Bitmap 的复用有一定的限制
在 Android 4.4 版本之前,只能重用相同大小的 Bitmap 内存区域;
4.4 之后可以重用任何 Bitmap 的内存区域,只要这块内存区域比要分配内存的 bitmap 大就可以
canUseForInBitmap() 方法的具体内容如下
在上面复用 Bitmap 的代码中,除了 inBitmap 参数之外,还将 options.inMutable 置为 true。这里如果不置为 true 的话,BitmapFactory 将不会重复利用 Bitmap 内存,并输出相应 warning 日志,如下所示

BitmapRegionDecoder 图片分片显示
想要加载显示的图片很大或者很长,比如手机滚动截图功能生成的图片。针对这种情况,在不压缩图片的前提下,不建议一次性将整张图片加载到内存。而是采用分片加载的方式来显示图片部分内容,然后依据手势操作,放大缩小或者移动图片显示区域。
图片分片加载显示主要是使用 Android SDK 中的 BitmapRegionDecoder 来实现。
BitmapRegionDecoder 基本使用
首先需要使用 BitmapRegionDecoder 将图片加载到内存。图片可以以绝对路径、文件描述符、输入流等方式传递给 BitmapRegionDecoder。如下代码所示
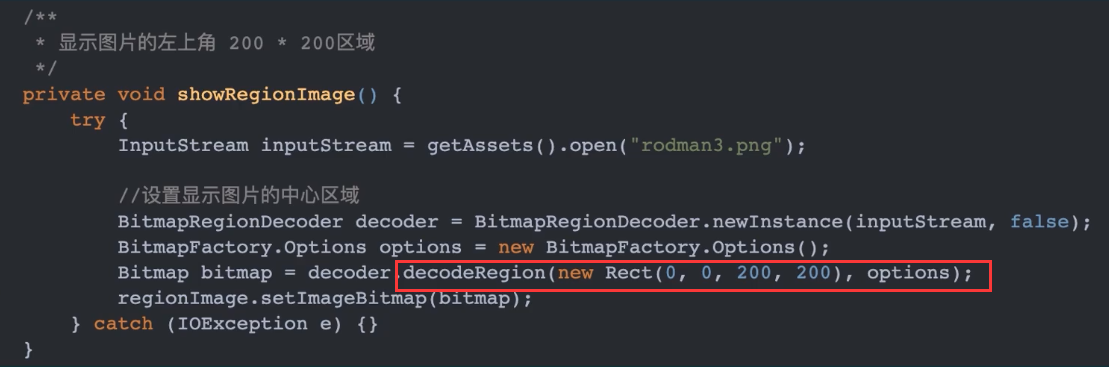
可以通过自定义 View,添加 touch 事件来动态地设置 Bitmap 需要显示的区域 Rect,具体实现网上已经有很多成熟的轮子可以直接使用,比如 LargteImaveView。张鸿洋先生有一篇比较详细文章对此进行介绍:Android 高清加载巨图方案 拒绝压缩图片
Bitmap 缓存
当需要在界面上同时展示一大堆图片的时候,比如 ListView、RecyclerView 等,由于用户不断地上下滑动,某个 Bitmap 可能会被短时间内加载并销毁多次,这种情况通过使用适当的缓存,可以有效地减缓 GC 频率保证图片加载效率,提高界面的响应速度和流程性。
最常用的缓存方式就是 LruCache,基本使用方式如下
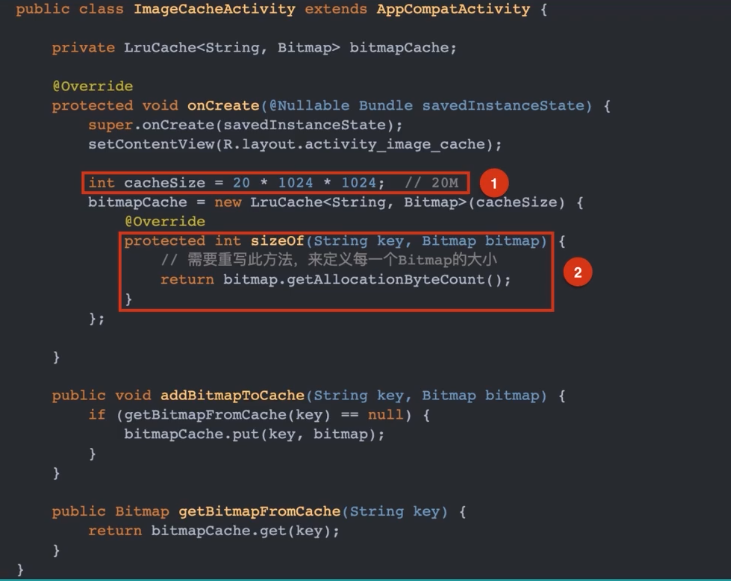
图中1处之处 LruCache 的最大可用空间为 20M。当超过 20M 时,LruCache 会根据内部缓存策略将多余 Bitmap 移除;图中2处指定了插入 Bitmap 时的大小。当我们往 LruCache 中插入数据时,LruCache 并不知道每个 Bitmap 对象占用多大内存,因此需要我们手动指定,并且根据缓存数据类型的不同也会有不同的计算方式。
总结
Bitmap开发中的几个常见问题:
● 一张图片被加载成Bitmap后实际占用内存是多大;
● 通过Options.inBitmap可以实现Bitmap的复用,但是有一定的限制;
● 当界面需要展示多张图片,尤其是在列表视图中,可以考虑使用Bitmap缓存;
● 如果需要展示的图片过大,可以考虑使用分片加载的策略。