淘宝网站建设弄什么类目东莞外贸人才网
目录
1.抽象类
1.概念:
2.语法
3.特性
2.接口
1.概念
2.语法
3.特性
1.抽象类
1.概念:
在面向对象的概念中,所有的对象都是通过类来描绘的,但是反过来,并不是所有的类都是用来描绘对象的,如果一个类中没有包含足够的信息来描绘一个具体的对象,这样的类就是抽象类。
在这我们拿动物来举例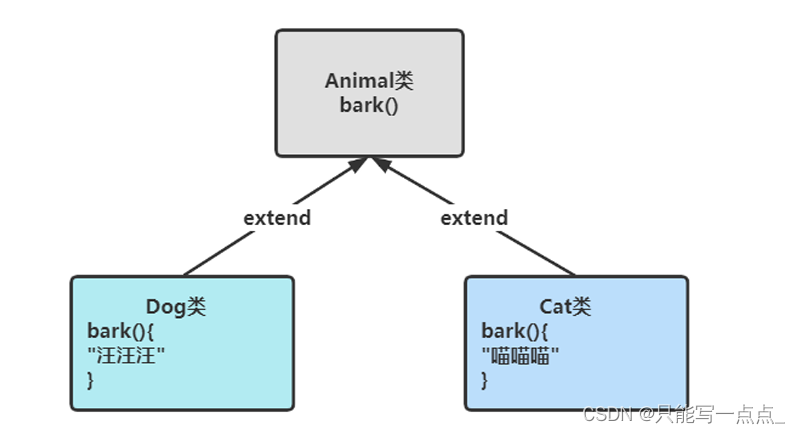
这里的Animal是父类,但由于Animal不是一个具体的动物,所以bark()无法具体实现
Dog类与Cat类与Animal都是继承关系且是具体的动物,因此可以实现“汪汪汪”与"喵喵喵"
因此我们可以把Animal类设计为"抽象类"
像这种没有实际工作的方法, 我们可以把它设计成一个抽象方法(abstract method), 包含抽象方法的类我们称为抽象类(abstract class)
2.语法
在Java中,一个类如果被abstract关键字修饰称为抽象类,抽象类中被abstract修饰的方法称为抽象方法,抽象方法不用给出具体的实现体
abstract class shape{abstract public void draw();abstract void calcArea();//抽象类也是类,也可以增加普通方法和属性public double getArea(){return area;}protected double area;//面积
}3.特性
1.抽象类不能直接实例化对象
2.抽象方法不能是private
3.抽象方法不能被final和static修饰,因为抽象方法要被子类重写
4.抽象类必须被继承,并且继承后子类要重写父类中的抽象方法,否则子类也是抽象类,必须使用abstract修饰
5.抽象类中不一定包含抽象方法,但是有抽象方法的类一定是抽象类
6.抽象类中可以有构造方法,供子类创建对象时,初始化父类的成员变量
2.接口
1.概念
在生活中我们可以看到很多接口如电脑的USB口,电源的插口......
接口就是公共的行为规范标准,大家在实现时,只要符合规范标准,就可以通用。
在Java中,接口可以看成是:多个类的公共规范,是一种引用数据类型
2.语法
接口的定义格式与定义类的格式基本相同,将class关键字换成interface关键字,就定义了一个接口
interface IShape {void draw();
}
class Rect implements IShape {@Overridepublic void draw() {System.out.println("画一个矩形!");}
}
class Triangle implements IShape {@Overridepublic void draw() {System.out.println("画一个三角形!");}
}public class Test4 {public static void drawMap(IShape iShape) {iShape.draw();}public static void main(String[] args) {//IShape iShape = new IShape();drawMap(new Rect());//画一个矩形!drawMap(new Triangle());//画一个三角形!}
}注:
1. 创建接口时, 接口的命名一般以大写字母 I 开头.
2. 接口的命名一般使用 "形容词" 词性的单词.
3. 阿里编码规范中约定, 接口中的方法和属性不要加任何修饰符号, 保持代码的简洁性
3.特性
1.接口的定义可以使用interface定义
2.接口当中的成员变量默认为public static final修饰的,定义的时候必须初始化!
3.接口当中的方法默认是public abstract修饰的,你不写的时候也是抽象方法,所以不能有具体的实现
4.接口当中使用default修饰的方法和static修饰的方法是可以有具体的实现的!
5.接口不可以被实例化
6.接口需要被类实现,此时使用关键字implements来实现 class A implements IShape()
7.当一个类实现了一个接口,那么此时这个类就要重写这个方法
8.接口也可以发生向上转型,也可以发生动态绑定,也可以发生多态!
如果上述内容对您有帮助,希望给个三连谢谢!
