扬州网络推广哪家好济南百度seo
一、逻辑运算
当我们要操作符合某一条件的数据时,需要用到逻辑运算
1、运算符
满足条件返回true,不满足条件返回false
# 重新生成8只股票10个交易日的涨跌幅数据
stock_change = np.random.normal(loc=0, scale=1, size=(8, 10))# 获取前5行前5列的数据
stock_change = stock_change[0:5, 0:5]# 逻辑判断,如果涨跌幅大于0.5,就标记为true,否则标记为false
stock_change > 0.5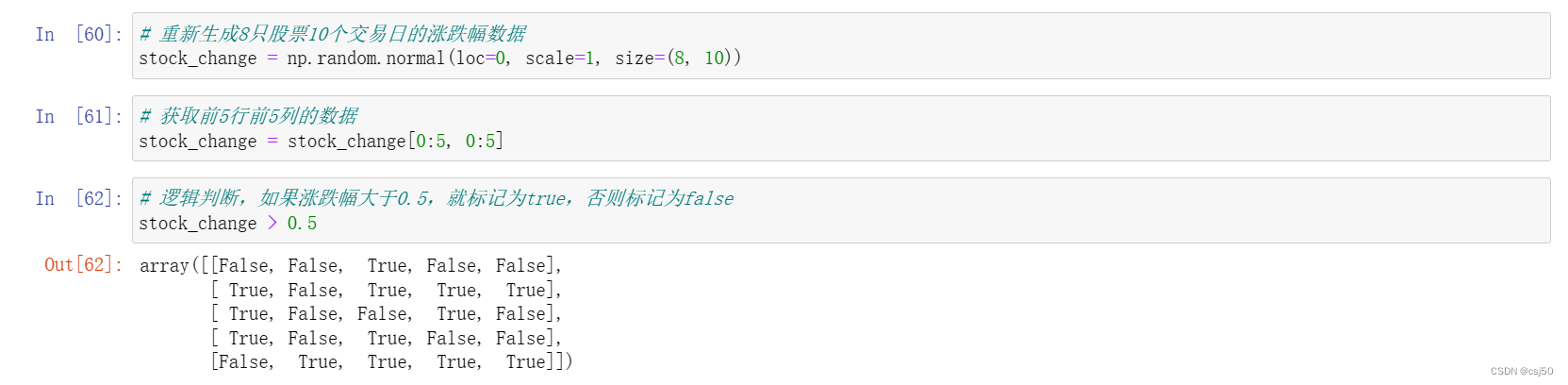
2、布尔索引
想要对布尔数据进行一个统一的操作,相当于是取出数组中为true的所以值,或为false的所有值
# 布尔索引
stock_change[stock_change > 0.5]
二、通用判断函数
1、np.all()
传入一组布尔值,只要有一个false,就返回false,全都是true才返回true
2、np.any()
传入一组布尔值,只要有一个true,就返回true,全都是false才返回false
3、例子
# 判断stock_change是否全是上涨的
np.all(stock_change > 0)stock_change# 判断stock_change是否有上涨的
np.any(stock_change > 0)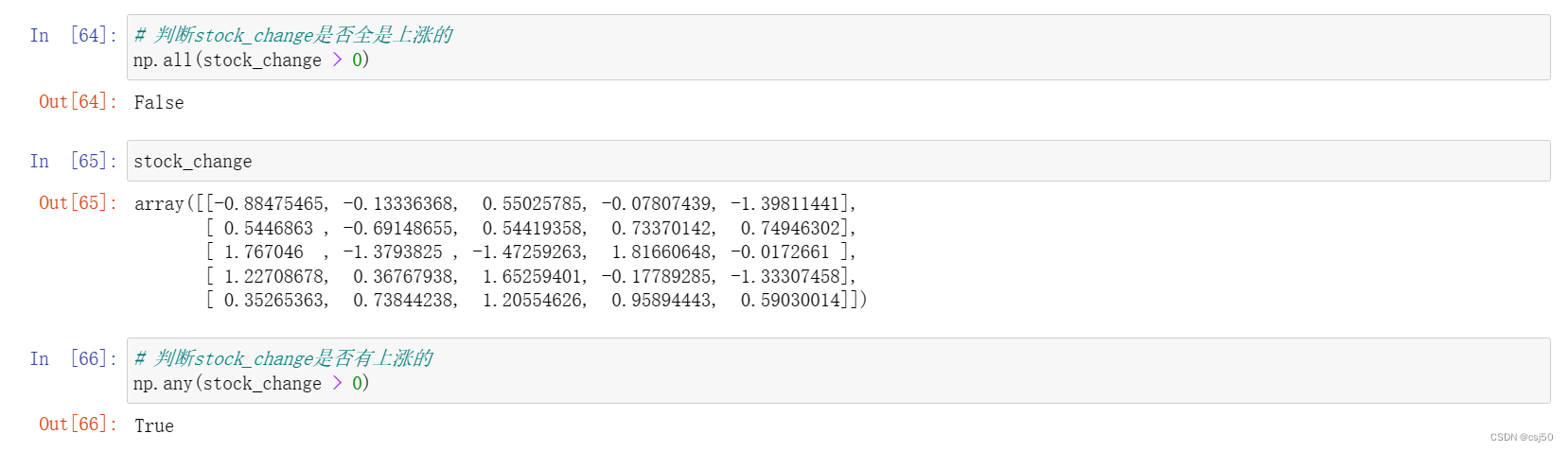
三、np.where(三元运算符)
1、通过使用np.where能够进行更加复杂的运算
np.where(布尔值, true的位置要设置的值, false的位置要设置的值)
2、例子
# 判断前四个股票前四天的涨跌幅,大于0的置为1,否则为0
temp = stock_change[:4, :4]tempnp.where(temp > 0, 1, 0)
3、np.logical_and 逻辑与
4、np.logical_or 逻辑或
5、例子
# 判断前四个股票前四天的涨跌幅,大于0.5并且小于1的,置为1,否则置为0
np.where(np.logical_and(temp > 0.5, temp < 1), 1, 0)# 判断前四个股票前四天的涨跌幅,大于0.5或者小于-0.5的,置为1,否则置为0
np.where(np.logical_or(temp > 0.5, temp < -0.5), 1, 0)
四、统计运算
1、如果想要知道涨幅或者跌幅最大的数据,应该怎么做
2、统计指标函数
np.min(a, axis=None, out=None, keepdims=False):最小值
np.max(a, axis=None, out=None, keepdims=False):最大值
np.mean(a, axis=None, out=None, keepdims=False):平均值
np.median(a, axis=None, out=None, keepdims=False):中位数
np.var(a, axis=None, out=None, keepdims=False):方差
np.std(a, axis=None, out=None, keepdims=False):标准差
3、可以用两种方式调用
np.函数名
ndarray.方法名
4、axis默认为axis=0即列向,如果axis=1即横向
5、例子
# 对于前四个股票前四天数据,进行一些统计运算
print("前四只股票前四天的最大涨幅{}".format(np.max(temp, axis=1)))
print("前四只股票前四天的最大跌幅{}".format(np.min(temp, axis=1)))
print("前四只股票前四天的波动程度{}".format(np.std(temp, axis=1)))
print("前四只骨片前四天的平均涨跌幅{}".format(np.mean(temp, axis=1)))
6、获得最大值最小值的位置(索引)
np.argmax(a, axis)
np.argmin(a, axis)
7、例子
# 获取股票指定哪一天的涨幅最大
print("前四只股票前四天内涨幅最大{}".format(np.argmax(temp, axis=1)))
print("前四天一天内涨幅最大的股票{}".format(np.argmax(temp, axis=0)))
五、数组运算
1、场景
平时成绩占30%,期末成绩占70%,算出最终成绩
2、数组与数的运算
运算符作用到数组中的每一个元素
# 数组与数的运算
arr = np.array([[1,2,3,2,1,4], [5,6,1,2,3,1]])arr + 10
3、数组与数组的运算
# 数组与数组的运算
arr1 = np.array([[1,2,3,2,1,4], [5,6,1,2,3,1]])
arr2 = np.array([[1,2,3,4], [3,4,5,6]])
arr1 + arr2
提示不满足广播机制!
4、广播机制
(1)执行broadcast的前提在于,两个nadarray执行的是element-wise的运算,Broadcast机制的功能是为了方便不同形状的ndarray(numpy库的核心数据结构)进行数学运算
(2)当操作两个数组时,numpy会逐个比较它们的shape(构成的元组tuple),只有在下述情况下,两个数组才能够进行数组与数组的运算
维度相等(单看这一列)
shape(其中相对应的一个地方为1)
(3)可以这样理解,首先把数组形状展开,从右到左按列来看,两个情况中只要满足一个就可以
以下情况不匹配:
(4)运算的结果,每一个维度取最大的
(5)例子
arr1 = np.array([[1,2,3,2,1,4], [5,6,1,2,3,1]])
arr2 = np.array([[1], [3]])arr1 # (2, 6)arr2 # (2, 1)arr1 + arr2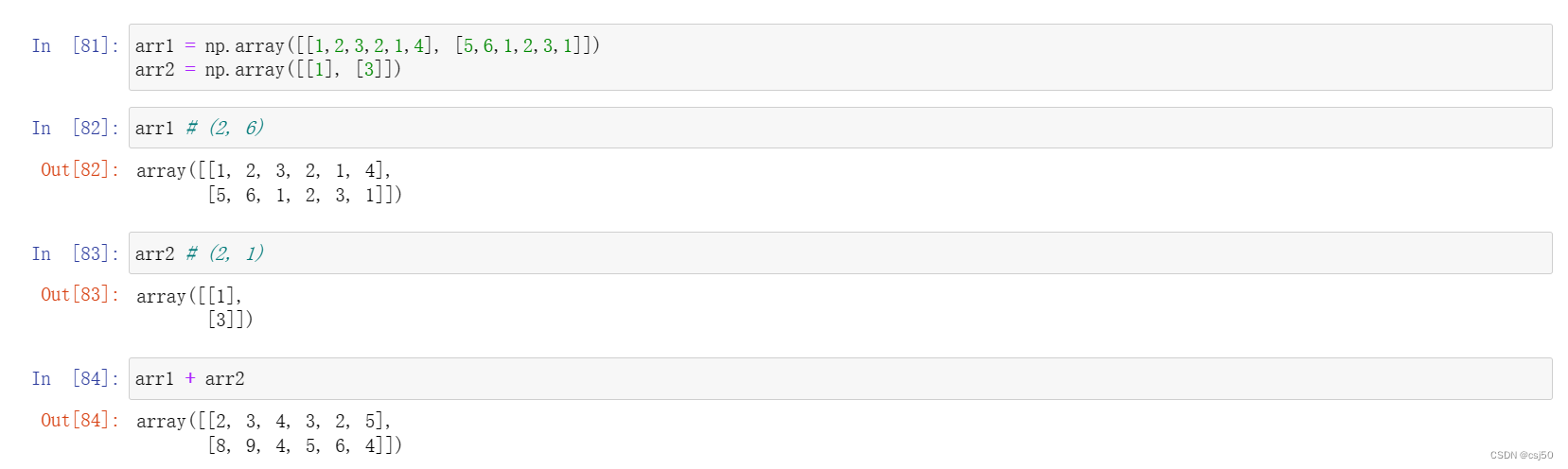
arr1是2行6列,arr2是2行1列
相加的结果,维度相同的,对应的每一行分别运算,维度为1的对所有行运算
六、矩阵运算
1、如何才能进行学生成绩计算呢
2、什么是矩阵
矩阵,英文matrix,和array的区别矩阵必须是2维的,但是array可以是多维的
3、两种方法存储矩阵
(1)ndarray 二维数组
# 矩阵运算
# ndarray存储矩阵
data = np.array([[80,86], [82,80], [85,78], [90,90], [86,82], [82,90], [78,80], [92,94]])datatype(data)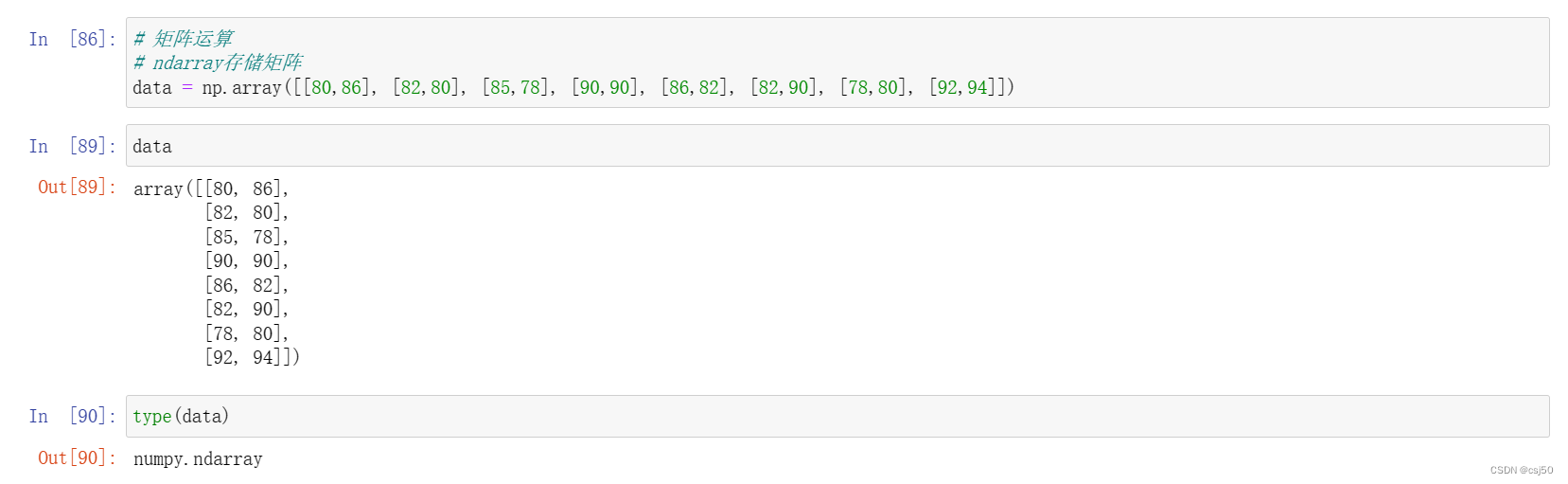
(2)matrix 数据结构
np.mat()
将数组转换成矩阵类型
# matrix存储矩阵
data_mat = np.mat([[80,86], [82,80], [85,78], [90,90], [86,82], [82,90], [78,80], [92,94]])data_mattype(data_mat)
4、矩阵乘法运算
矩阵乘法的两个关键:形状改变和运算规则
(1)形状改变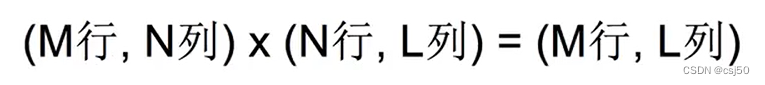
必须符合上面的式子,否则运算出错。第一个矩阵的列数和第二个矩阵的行数要一致
(2)运算规则
5、ndarray矩阵乘法api
np.matmul:矩阵相乘
np.dot:点乘
6、计算成绩
ndarray存储方式
# 计算成绩
dataweights = np.array([[0.3], [0.7]])weightsnp.matmul(data, weights)np.dot(data, weights)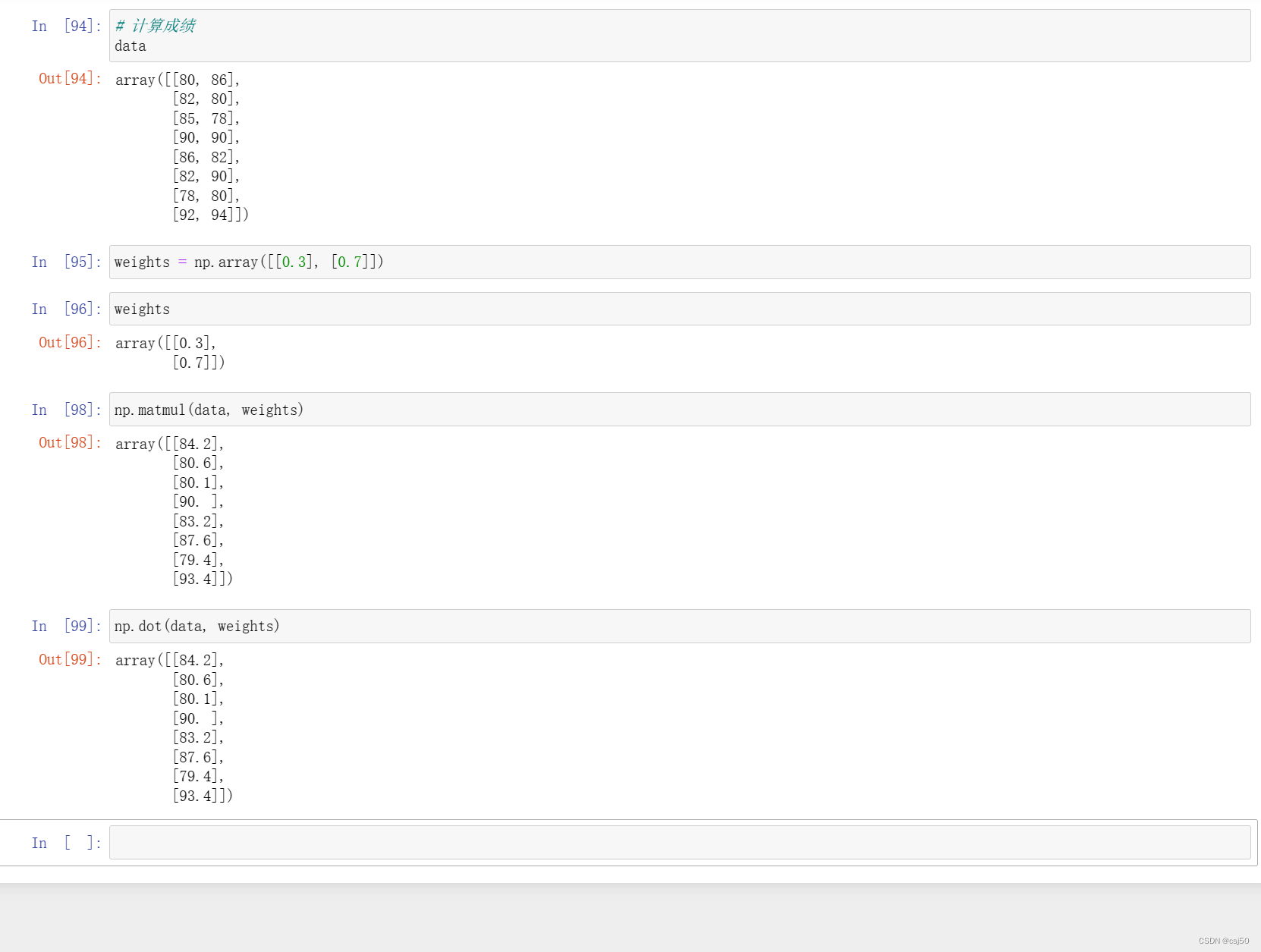
matrix存储方式
weights_mat = np.mat(weights)weights_matdata_mat * weights_mat