信誉比较好的网上做任务的网站wordpress站内301

本来即将于下个月生效的「废除竞业协议」的政策,在倒计时 14 天时,遭到了叫停。
整理 | 屠敏
出品 | CSDN(ID:CSDNnews)
今年 4 月,美国联邦贸易委员会(FTC)宣布,将全面禁止所有用人单位与雇员(包括高级管理人员)签订新的“竞业协议”等类似条款。其中,高级管理人员(处于“政策制定职位”的人,且年薪超过 151164 美元,约人民币 109 万元)的现有竞业协议依旧有效,其他员工的现有竞业协议则在规定生效日期后不再强制执行。
按照当时 FTC 的说法,这项政策的规定生效日期是在下个月即 9 月 4 日。彼时此举被外界普遍视为美国拟全面禁止“竞业协议”,是利好无数“打工人”的做法,也引得大家奔走相告,希望自己所在的地区、公司能够效仿。
然而,随着生效日期的临近,不出意外的话,就要出意外了。就在今天,据路透社报道,美国联邦法官推翻了 FTC 废除竞业禁止协议的规定。这意味着这项规定将会被暂时搁置,并且不会于 9 月 4 日生效,一切兜兜转转似乎又回到了原点。

联邦法官:FTC 无权制定这项规定
在一份长达 27 页的意见书中,得克萨斯州的联邦法官艾达·布朗 (Ada Brown) 给出了两个结论:
其一,FTC 缺乏颁布关于「废除竞业协议」规定的法定权力。

https://assets.bwbx.io/documents/users/iqjWHBFdfxIU/rj8_52.B4gYs/v0
其二,废除竞业禁止协议的规则是武断和反复无常的,因为它波及范围太过宽泛,而且没有合理的解释,最终会造成无法弥补的损害。
之所以如此评价,布朗进一步表示,即使 FTC 有权采用这项规则,也没有理由去禁止几乎所有的竞业禁止协议。“美国联邦贸易委员会缺乏证据证明他们为何选择实施如此全面的禁令......而不是针对具体的、有害的竞业禁止条款,这使得该规则显得武断和反复无常。”
因此,“(该规则)特此撤销,不得在 2024 年 9 月 4 日或之后执行或以其他方式生效。”
事实上,就在今年 7 月,艾达·布朗就曾出面阻止过这项规定,同时她考虑了美国商会(美国最大的商业游说团体)和税务服务公司 Ryan 提出的彻底废除该规定的提案。

FTC:将上诉,继续努力阻止竞业协议
殊不知,推翻这一规定的背后是 FTC 多年的努力。
2023 年,FTC 首次提出了这项规定,该规定将使公司更难通过法律要求前员工在一定时间内不能为竞争对手公司工作,从而阻止他们分享从前一家公司获得的知识和商业机密。当时,该机构表示,员工应该享有换工作的自由,企业应该享有接触更广泛人才库的机会。
2024 年,FTC 表示,已认定竞业禁止条款是“不公平的竞争手段,因此违反了《联邦贸易委员会法》第 5 条”。该规则具有追溯效力,这意味着目前持有的竞业禁止协议可能会被废除,但某些涉及高收入公司高管的情况除外。
正如文章伊始所述,负责执行反垄断法和监管竞争的 FTC 于今年 4 月以 3 比 2 的投票通过了这项规定。该规定将于 9 月生效,将使禁止员工在特定时间段或特定地区为其雇主的竞争对手工作或开展竞争业务的条款失效,影响从医疗保健、工程到金融等行业。
据 FTC 此前称,约有 3000 万人(占美国工人的 20%)签署了竞业禁止协议。联邦贸易委员会主席 Lina Khan 当时在规则变更的声明中表示,“竞业禁止条款压低了工资,压制了新创意,剥夺了美国经济的活力。一旦竞业禁止条款被废除,每年将有超过 8,500 家新创业公司诞生,普通员工的年收入将增加 524 美元,未来 10 年专利数量也将从平均每年 1.7 万项增至 2.9 万项。联邦贸易委员会废除竞业禁止协议的最终规则将确保美国人有自由寻找新工作、创办新企业或将新创意推向市场。”
现如今,随着联邦法官推翻这一规定,一切化为泡影。FTC 发言人维多利亚·格雷厄姆( Victoria Graham)在一份声明中表示,该机构对这一决定感到“失望”,但发誓要“继续努力阻止竞业禁止”。
格雷厄姆表示:“我们正在认真考虑上诉,今天的裁决并不妨碍联邦贸易委员会通过逐案执法行动解决竞业禁止问题。”
据悉,FTC 可上诉至美国第五巡回上诉法院,但目前其已经无法在全国范围内针对任何雇主强制执行该规则。

竞业禁止协议究竟是好还是坏?
该结果的发布,几家欢喜几家愁。
站在企业的角度来看,竞业协议本身能够有效保护企业的商业机密、专有技术和客户信息,防止这些重要资产被前员工带到竞争对手那里,从而保护企业的竞争优势。此外通过限制员工在离职后立即加入竞争对手公司或自行创业,保护企业在市场上的合法利益。
正因此,彼时 FTC 拟定的禁令消息传出后不久,就有不少商业公司提出反对意见,称如果没有竞业禁止协议,他们就无法保护商业机密。他们还认为,FTC 会颁布如此广泛的规定,可能会使数百万份合同无效,这远远超出了其法定权限。
不过,站在员工角度来看,竞业协议宛如一道枷锁,有了竞业协议似乎就不太敢轻易的离职,因为离职之后极可能面临一定时间内失业的风险,亦或者面临前东家高额的索赔要求。
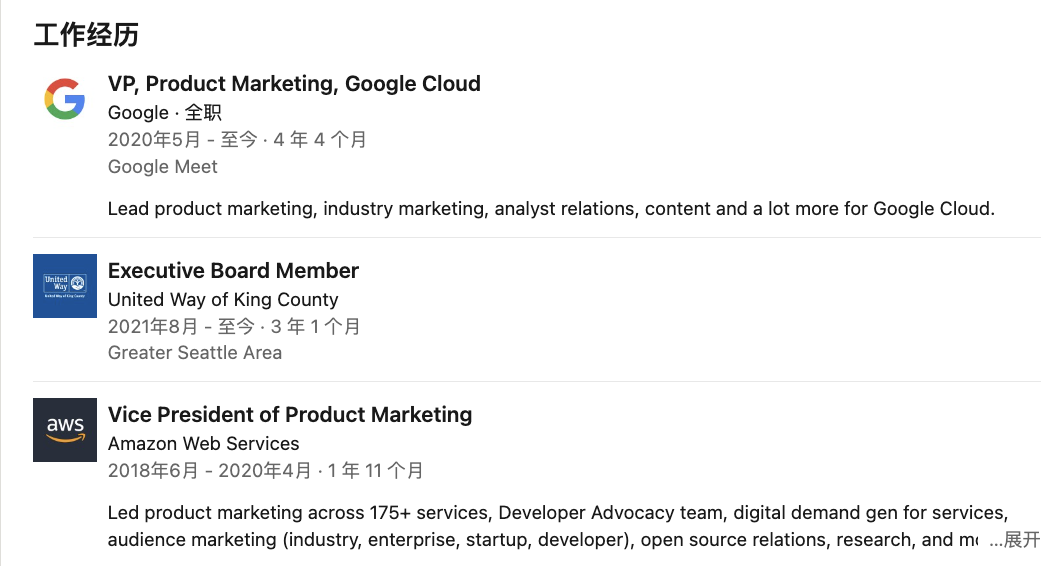
此前,亚马逊的一名员工就因竞业禁止协议而陷入困境。
2020 年,亚马逊的云服务部门 AWS 在华盛顿州的法庭上起诉了前员工 Brian Hall,指责他跳槽到谷歌云部门,违反了之前签订的竞业禁止协议,可能会泄露 AWS 的商业机密,借此要求法院禁止 Hall 在未来 18 个月内为谷歌工作。
Brian Hall 原来是 AWS 的产品营销副总裁,他在离职后,接受了谷歌云的同一职位。针对 AWS 的起诉,Hall 的律师表示,当初 Hall 加入 AWS 时,他的上司明确告诉他不会用竞业禁止条款来限制他的就业自由,但当他真正要离开时,AWS 却拿出了这个条款来阻止他跳槽。
这次诉讼引起了不少争议,原因是竞业禁止协议通常只针对技术人员,但是针对 Hall 这样负责市场营销的人却很少见。但亚马逊认为,Hall 每天都在跟公司的核心高管一起工作,了解 AWS 的很多机密信息,包括 2020-2021 年的产品计划,所以不希望他把这些信息带到竞争对手那里。
虽然最终 Brian Hall 成功入职 Google 并工作至今,但因为这一事件,不少人还是对竞业协议心有余悸。
甚至有人发文表示,“三年前,我因为竞业禁止协议而拒绝了 AWS 的一份诱人工作邀请。坦白说,随着亚马逊的不断扩张,我对这个决定并不后悔。”

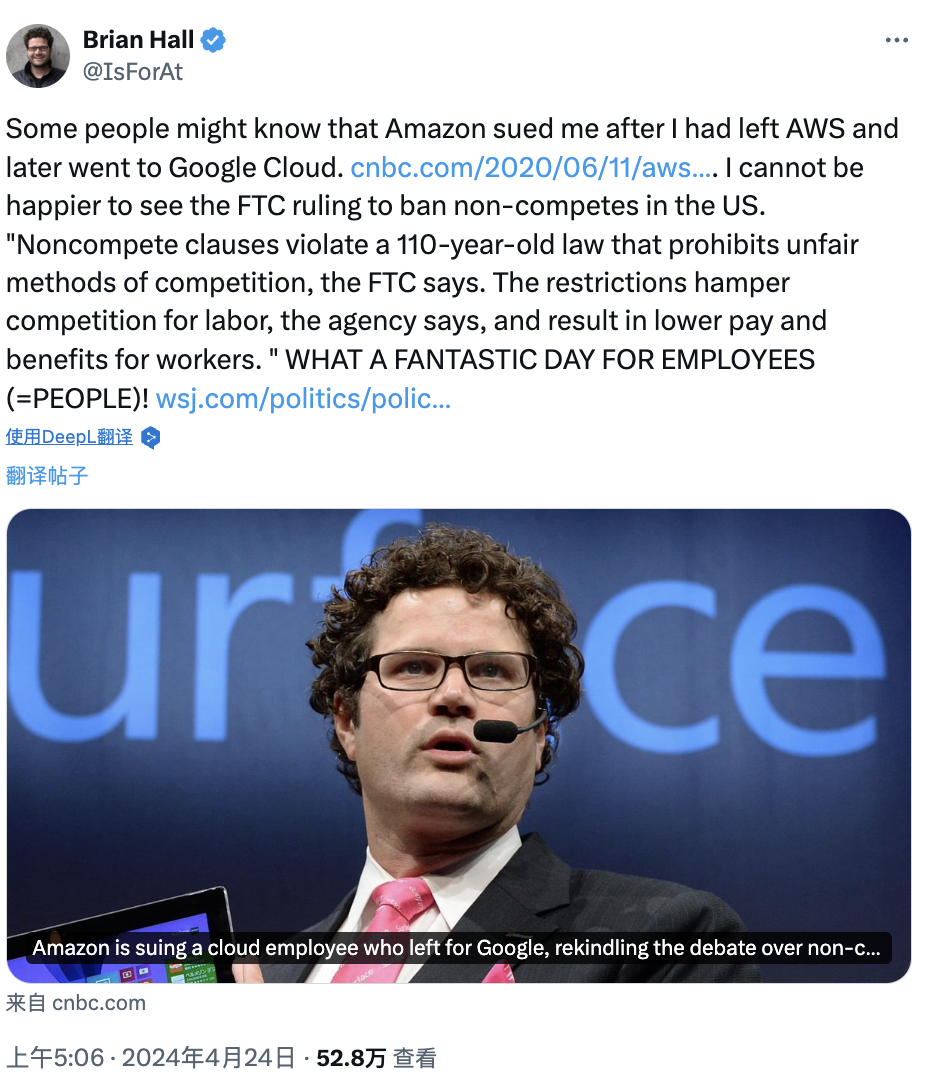
后来,在得知 FTC 出手之后,Brian Hall 也现身评论道,「看到联邦贸易委员会裁定禁止美国境内的竞业禁止条款,我感到无比高兴。“联邦贸易委员会表示,竞业禁止条款违反了一项已有 110 年历史的禁止不正当竞争手段的法律。该机构表示,这些限制阻碍了劳动力竞争,导致工人的工资和福利降低。”员工们(=大众)今天真是美好的一天!」
归根结底,竞业限制协议如同一把双刃剑。对于员工而言,很多人并不是反感“竞业协议”,而是反对“竞业协议”被滥用。
正如网友评价的,「我倾向于支持补偿丰厚的竞业禁止协议,比如 “你在一年内不能在这个行业工作,但我们会支付你这一年 100%的工资”。这样一来,在对公司非常重要的情况下(比如他们愿意投入大量资金),就可以允许员工签订竞业禁止协议,但在其他情况下则禁止签订竞业禁止协议。虽然此举仍然是有害的,但你至少可以得到损害赔偿。」
参考:
https://www.reuters.com/legal/us-judge-strikes-down-biden-administration-ban-worker-noncompete-agreements-2024-08-20/
https://www.ft.com/content/56770a82-3c3f-4739-9895-e2f97b6202b4
https://news.ycombinator.com/item?id=41304695
推荐阅读:
▶24小时不回邮件=被裁?马斯克曾经的一封邮件被判违法,前Twitter员工获赔432万元
▶白鸦、梁宁等大咖云集,40+知名产品实操案例,2024全球产品经理大会共探AGI创新之旅!
▶“鸽”了一年,稚晖君连发五款机器人:打麻将、拆快递、纽扣穿针都不在话下,还有“0元”惊喜!
能学习到新知识、产生共鸣,解答久困于心的困惑,这是《新程序员》的核心价值。欢迎扫描下方二维码订阅纸书和电子书。
