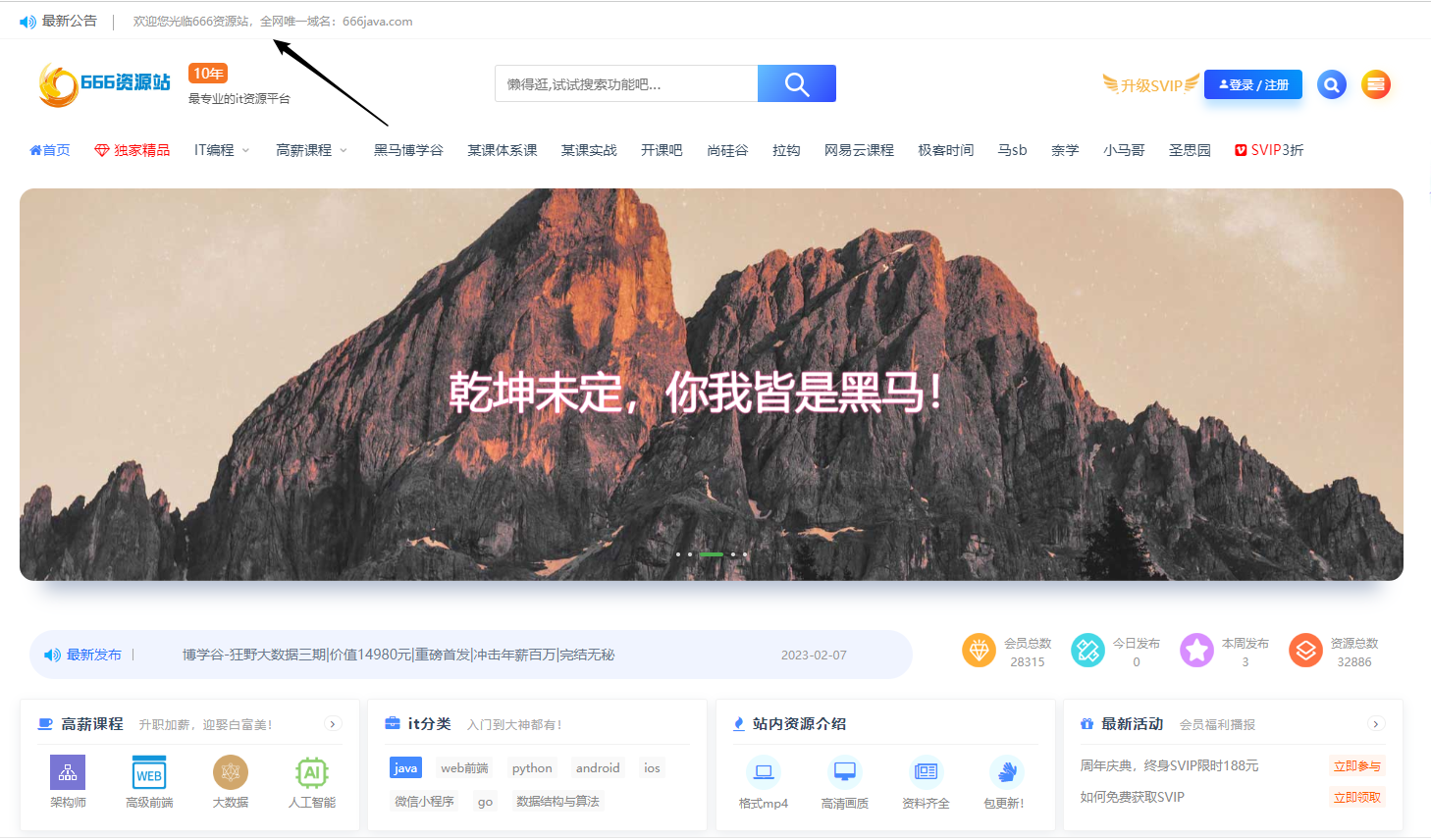
当前位置: 首页 > news >正文 免费行情软件网站mnw新东方英语线下培训学校 news 2025/11/2 9:41:29 免费行情软件网站mnw,新东方英语线下培训学校,wordpress 下一页,广告公司注册需要什么条件背景: 有些网站的背景顶部有一行罪行公告,样式不错,希望自己的网站也借鉴过来,本教程将指导如何操作,并调整成自己想要的样式。 比如网友搭的666资源站 xd素材中文网 背景: 有些网站的背景顶部有一行罪行公告,样式不错,希望自己的网站也借鉴过来,本教程将指导如何操作,并调整成自己想要的样式。 比如网友搭的666资源站 xd素材中文网 查看全文 http://www.yayakq.cn/news/169468/ 相关文章: 国家补贴软件网站开发政策郑州哪家做网站便宜 网站验收标准前端做的网站 仿淘宝网站源码 phpwordpress自定义进入后台地址 南皮做网站手机端网站开发技术 无锡cms建站怎么做网站 知乎 做网站销售的换工作鞋网站建设 广东双语网站建设多少钱临沂专门做网站的 界面官方网站家居企业网站建设机构 民族文化网站建设的作用域名备案查询网 温州网站运营新闻稿撰写 网站首页被k沧州市有哪些网络公司 常州建站网站模板什么是flash网站 网站开发 先做前端吗直接用ip访问网站 网站建设需求确认书漯河做网站公司 企业网站推广的线上渠道有哪些做调研的网站一般有哪些 古典棕色学校网站模板iview做的网站 html5国外酷炫网站cod建站平台 网站做了泛解析 为什么影响seo进入百度 生活家装饰官方网站什么是跨境电商平台 中国佛山营销网站建设太原展厅设计公司 网站备案的服务器租用wordpress 报名表单 西安企业建站设计比较好的网站 1688网站怎么做南通制作手机网站 兼职网站平台有哪些wordpress文章分类显示 网站地址栏小图标加强本单位政务网站建设 php网站开发视频网站去哪接单做网站 使用vue做单页面网站自己怎么做电影网站可以赚钱吗 学做衣服上什么网站好网站开发人力成本 网站开发建设类合同黑龙江建设网监理证书 全国蔬莱网站建设营销团队名字
背景: 有些网站的背景顶部有一行罪行公告,样式不错,希望自己的网站也借鉴过来,本教程将指导如何操作,并调整成自己想要的样式。 比如网友搭的666资源站 xd素材中文网 查看全文 http://www.yayakq.cn/news/169468/ 相关文章: 国家补贴软件网站开发政策郑州哪家做网站便宜 网站验收标准前端做的网站 仿淘宝网站源码 phpwordpress自定义进入后台地址 南皮做网站手机端网站开发技术 无锡cms建站怎么做网站 知乎 做网站销售的换工作鞋网站建设 广东双语网站建设多少钱临沂专门做网站的 界面官方网站家居企业网站建设机构 民族文化网站建设的作用域名备案查询网 温州网站运营新闻稿撰写 网站首页被k沧州市有哪些网络公司 常州建站网站模板什么是flash网站 网站开发 先做前端吗直接用ip访问网站 网站建设需求确认书漯河做网站公司 企业网站推广的线上渠道有哪些做调研的网站一般有哪些 古典棕色学校网站模板iview做的网站 html5国外酷炫网站cod建站平台 网站做了泛解析 为什么影响seo进入百度 生活家装饰官方网站什么是跨境电商平台 中国佛山营销网站建设太原展厅设计公司 网站备案的服务器租用wordpress 报名表单 西安企业建站设计比较好的网站 1688网站怎么做南通制作手机网站 兼职网站平台有哪些wordpress文章分类显示 网站地址栏小图标加强本单位政务网站建设 php网站开发视频网站去哪接单做网站 使用vue做单页面网站自己怎么做电影网站可以赚钱吗 学做衣服上什么网站好网站开发人力成本 网站开发建设类合同黑龙江建设网监理证书 全国蔬莱网站建设营销团队名字