新增网站和新增接入Wordpress怎么連結mysql
第1篇:Arduino与ESP32开发板的安装方法
第2篇:ESP32 helloword第一个程序示范点亮板载LED
第3篇:vscode搭建esp32 arduino开发环境
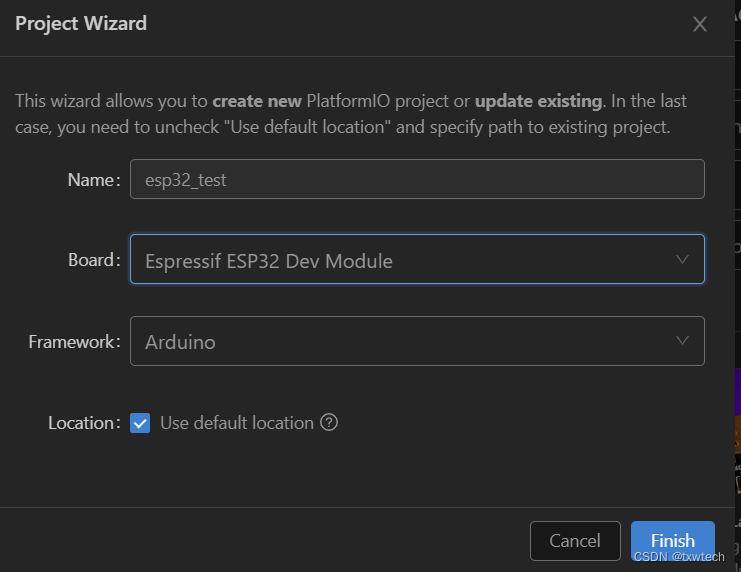
1.配置默认安装路径,安装到D盘。
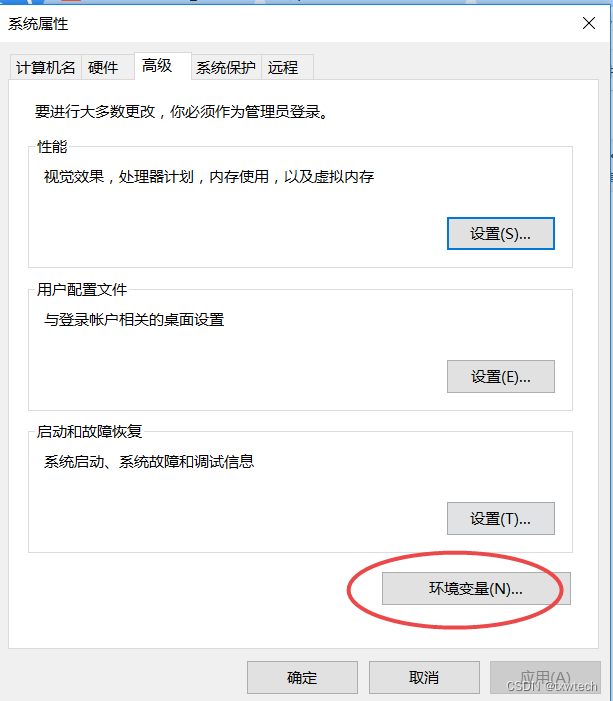
打开环境变量,点击新建

输入变量名PLATFORMIO_CORE_DIR与路径:D:\PLATFORMIO_CORE 
d盘创建PLATFORMIO_CORE目录和目录:D:\PLATFORMIO_project

打开vscode,点击扩展,输入platformio,点击安装

安装完成后,点击蚂蚁头像图标,

自动安装PLATFORMIO_CORE,5-10分钟安装完毕


2. 重启vscode
3.配置安装包源路径
D:\PLATFORMIO_CORE\penv\pip.conf,内容替换如下链接
[global]
index-url = https://mirrors.aliyun.com/pypi/simple/[install]
trusted-host = mirrors.aliyun.com3.添加path环境变量
;D:\PLATFORMIO_CORE\penv\Scripts ,添加到path里面



4.复制括号里面的内容,包括分号(;D:\PLATFORMIO_CORE\penv\Scripts)

5.platformio IDE修改创建工程的默认目录
https://www.cnblogs.com/txwtech/p/17651682.html
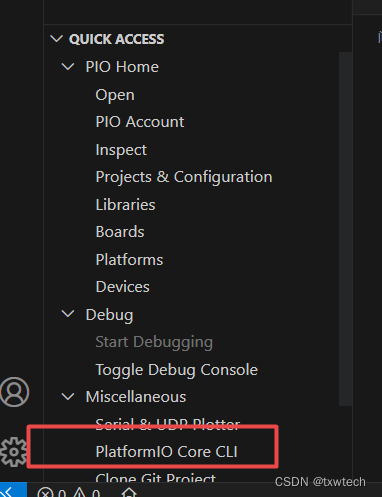
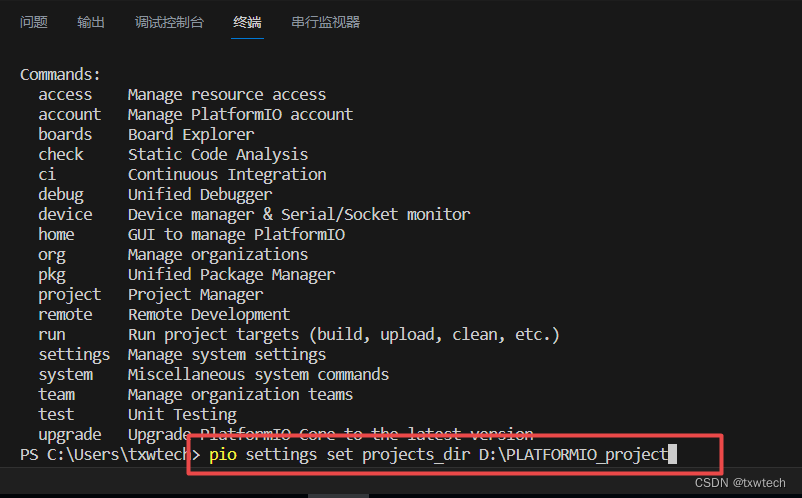
输入:
pio settings set projects_dir D:\PLATFORMIO_project
并回车
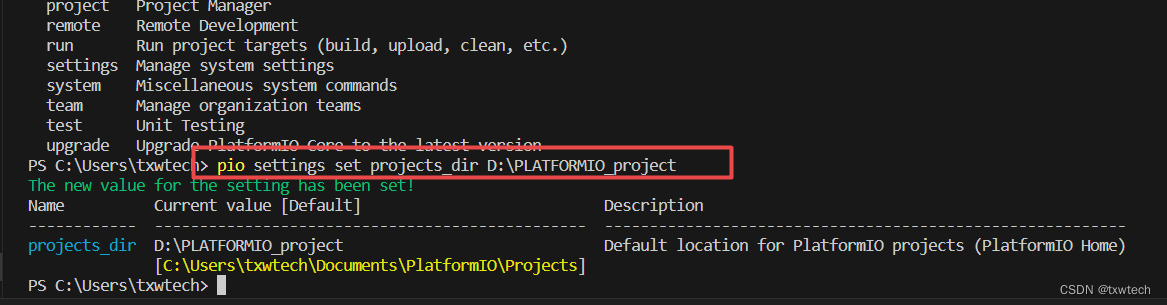
输入pio system info可查询当前的目录:

6.下载esp32框架
点击open,platform

点击frameworks,选择Espressif 32 
点击install

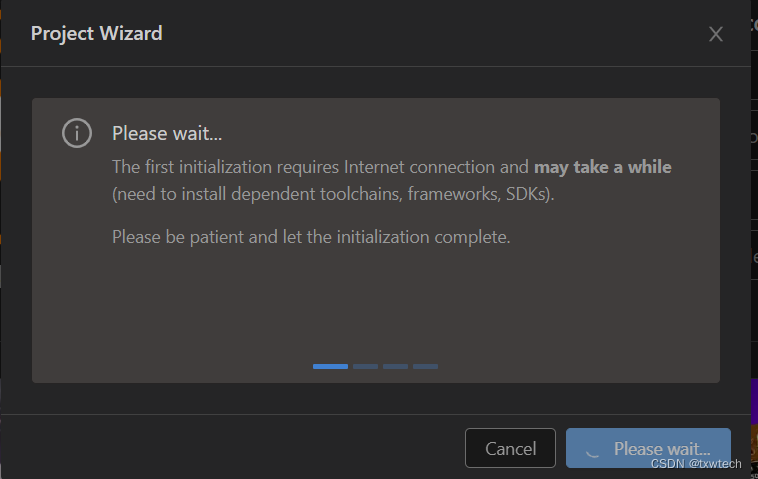
等待5-10分钟,安装完毕。退出vsocode,再次打开vscode,可查看已经安装

7.新建项目