什么是同ip网站网页制作培训网站
在之前的文章中,我们了解了应用部署的阶段以及常见的部署模式,包括微服务架构的应用应该如何部署等基本内容。本篇文章将介绍如何安全地部署应用程序。
安全是软件开发生命周期(SDLC)中的关键部分,同时也需要成为 SDLC 中每个环节的一部分,尤其是部署。因此,保障应用部署安全并不是开始于部署阶段,而是从写下第一行代码开始就需要将安全纳入考虑的因素,即安全左移。
本文将会介绍6个保障应用部署安全的最佳实践,帮助您避免安全问题。这些最佳实践还可以保证部署过程的速度不受影响。
1、控制部署的触发方式
开发团队应该慎重管理触发自动部署到生产环境的代码,生产部署不应该从不受信任的代码库、fork或者分支中进行。
2、了解开发环境的安全问题
在启动一个新的软件项目之前,让开发团队熟悉相关系统环境的安全最佳实践是至关重要的。例如,Kubernetes 的安全上下文设置可以帮助开发团队理解 Kubernetes 安全的基本内容。当开发团队了解这些基础知识之后就可以极大程度减少人为错误。
这之所以重要是由于 Kubernetes 是历史上发展最迅速的开源项目之一,它被广泛应用于云原生开发和部署,对 Kubernetes 的安全最佳实践有深刻理解可以帮助团队避免安全失误,其他的容器编排系统也同理。
3、实施密钥策略
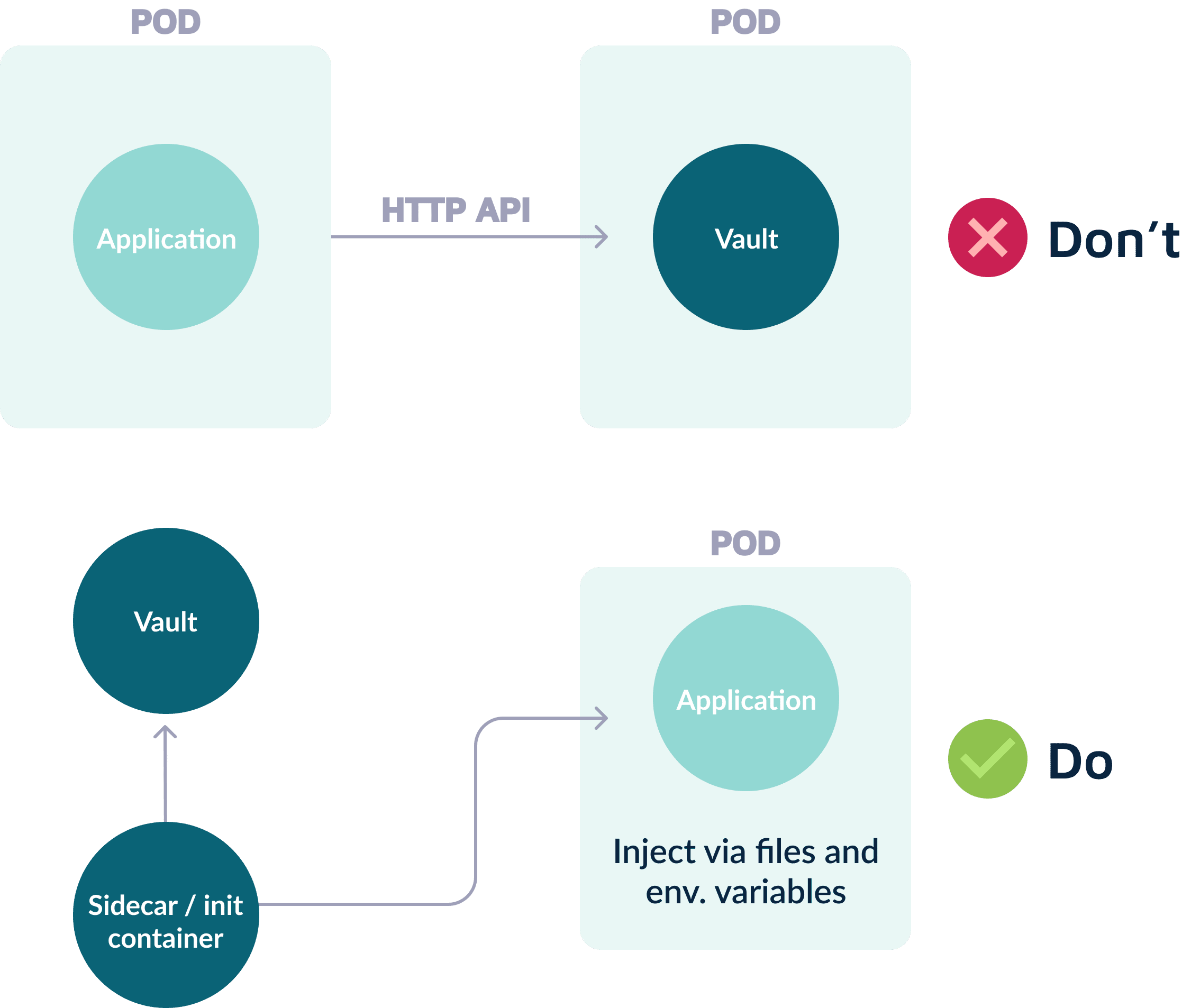
当使用动态服务来处理配置变化时,它们(或类似服务)也应该会处理相关的密钥。它们在运行时将密钥传递给容器,同时使用统一的策略来处理密钥,确保不同类型的密钥(即运行时与构建密钥)不被混淆,并保持测试和开发顺利。
应用程序仅需要在打包时构建密钥(比如,项目repo或文件存储凭证)。运行时密钥只有在部署之后才是必要的(比如,私钥、数据库密码以及 SSL 证书),因此开发者仅需传递必要的密钥到应用程序即可。
具体的策略并不重要,重要的时候坚持采用统一的策略。每个团队都必须在所有环境中使用相同的密钥处理策略,使其更容易跟踪密钥。这个策略应该是灵活的,以便于测试和部署。重点应该是密钥的使用,而不是其来源。
4、采用 GitOps 实践
GitOps 正逐渐成为安全的云原生和以Kubernetes为中心的CI/CD的首选方法。它同时提供了安全和快速部署,这是当前任何软件开发项目中最重要的两个方面。
根据许多优秀的开发人员和工程师的说法,GitOps 是一系列针对 Kubernetes 环境的实践,尤其是当单个集群资源被多个用户或团队共享时。
GitOps可以与 Kubernetes 的功能(如命名空间)协同工作,确保多个租户以安全的方式使用资源。这些做法通过保持租户之间的隔离、减少安全和可读性的风险来实现。当所有用户都在进行修改时,这一点尤其有帮助。
使用像 GitOps 这样的模式,可以确保任何用户所做的任何改变在进入最终构建之前都会被跟踪和批准。这不仅可以管理应用程序的更新,而且如果某个更新并没有像预期那样工作时,你可以轻松回滚到以前的版本。
5、永远别用默认配置
如果你正在使用开源项目,那么千万别用它们的默认配置,这点尤为重要。默认配置不一定与你的安全策略一致,因为它们关注的是商业、运营和功能上的成功,而不是安全。此外,它们是常识,任何人都可以利用它们。在这种情况下,你可以寻求商业平台和供应商的帮助。
这方面的一个典型例子是,在使用 Kubernetes 时,部署及其 pod 没有网络分段策略。这让所有的资产在它们之间进行通信。如果开发者想快速建立一个应用程序,这种默认设置是很方便的,但保留默认设置意味着,如果一个容器被攻击,威胁就会迅速蔓延。
6、作为部署的一部分运行自动测试
经过深思熟虑的测试可以帮助你对代码的安全性获得信心,反之糟糕的测试会妨碍你。如果条件允许的话,将测试自动化,使其支持部署流水线。简单的“测试”可以在每次代码修改时运行,资源密集型的测试可以保存到重要的版本。不要忽视失败的测试,你需要重新评估和重构不起作用的测试。