西安营销网站建设公司无屏蔽搜索引擎
前言:
扫雷是一款经典的单人益智游戏,它的目标是在一个方格矩阵中找出所有的地雷,而不触碰到任何一颗地雷。在计算机编程领域,扫雷也是一个非常受欢迎的项目,因为它涉及到许多重要的编程概念,如数组、循环、条件语句和函数等。
C语言是一种广泛使用的编程语言,它具有高效、灵活和可移植等特点,非常适合编写各种类型的应用程序。因此,使用C语言编写一个扫雷游戏是一个很好的学习编程的项目。
在这篇博客中,我们将介绍如何使用C语言编写一个简单的扫雷游戏。我们将从基本的编程概念开始讲解,逐步深入到更复杂的程序设计技术。我们还将提供完整的代码示例和详细的注释,以帮助读者更好地理解和掌握这个项目。
无论您是初学者还是有一定编程经验的开发者,相信通过阅读本篇博客,您都能够学到一些有用的知识和技巧。让我们一起来探索如何使用C语言编写一个令人兴奋的扫雷游戏吧!
前期准备:
先开一个test.c文件用来游戏的逻辑测试,在分别开一个game.c文件和game.h头文件用来实现游戏的逻辑

1. 主要步骤:
1.1 游戏规则:
输入1(0)开始(结束)游戏,输入一个坐标,如果该坐标不是雷则会显示该坐标周围有几个雷
1.2 打印菜单:
void menu()
{printf("----------------扫雷----------------\n");printf("| |\n");printf("| 1.play |\n");printf("| 0.exit |\n");printf("| |\n");printf("------------------------------------\n");
}
int main()
{int input = 0;srand((unsigned int )time(NULL));do{menu();printf("请选择:>");scanf("%d", &input);switch (input){case 1:game();break;case 0:printf("游戏结束,退出游戏\n");break;default :printf("输入错误请重新输入\n");}} while (input);return 0;
}1.3 打印棋盘:

写两个数组一个是用来打印给玩家看的棋盘,一个是用来放置炸弹的隐藏棋盘,等到游戏结束我们才会打印这个棋盘。然后我们给数组初始化,用*来初始化我们给玩家看的棋盘,用字符‘0’初始化隐藏棋盘。
char mine[ROWS][COLS] = { 0 };char show[ROWS][COLS] = { 0 };//初始化棋盘InitBoard(show, ROWS, COLS, '*');InitBoard(mine, ROWS, COLS, '0');//打印棋盘DisPalyBoard(show, ROW, COL);//DisPalyBoard(mine, ROW, COL);
1.4 打印行列:
因为我们是用坐标来选择排雷的,所以我们需要在棋盘的周围打印出行列才可以让玩家更好的去选择。
首先在打印棋盘for循环上方加上一个打印0~9的for循环就可以打印出棋盘的行了,然后用打印列的for循环套在打印棋盘的for循环上就可以打印出棋盘的列了。
void DisPalyBoard(char arr[ROWS][COLS], int row, int col)
{printf("------扫雷游戏------\n");int i = 0;//打印行的for循环for (i = 0; i <= col; i++){printf("%d ", i);}printf("\n");//打印列的for循环for ( i = 1; i <= row; i++) {printf("%d ", i);//打印棋盘的for循环for (int j = 1; j <= col; j++){printf("%c ", arr[i][j]);}printf("\n");}
}1.5 放置炸弹:
要想棋盘上随机分布十个炸弹(炸弹我们用字符‘1’定义),我们就需要生成随机数使数组的随机十个元素等于字符‘1’,而生成随机数就需要调用到前面我写猜数字游戏时讲过的rand函数、srand函数、time函数了。
void SetMine(char arr[ROWS][COLS], int row, int col)
{int count = EsayCount;while (count){int x = rand() % row + 1;int y = rand() % col + 1;if (arr[x][y] == '0')//防止生成相同随机数时,使多个炸弹放置在同一位置{arr[x][y] = '1';count--;}}
}1.6 排查炸弹:
当我们输入一个坐标后如果时炸弹结束游戏,如果不是炸弹则需要显示炸弹的数量。
判断是否是炸弹只需写一个if语句判断该坐标中数组所对应的元素是否等于‘1’就行了。
显示周围有几个雷,我们就需要将所选坐标的周围的数加起来就可以了,这些加起来的数的和替换所选坐标的元素就可以了。
int GetMineCount(char mine[ROWS][COLS],int x,int y)
{return (mine[x - 1][y] + mine[x - 1][y - 1] + mine[x][y - 1] + mine[x + 1][y - 1]+ mine[x + 1][y + 1] + mine[x - 1][y + 1] + mine[x - 1][y + 1] + mine[x][y + 1] - 8 * '0');
}也可以用for循环统计
int GetMineCount(char mine[ROWS][COLS], int x, int y)
{int a = 0;for (int i = x - 1; i <= x + 1; i++){for (int j = y - 1; j <= y + 1; j++){a += mine[i][j];}}return a - '0' * 9;
}
void FindMine(char mine[ROWS][COLS], char show[ROWS][COLS], int row, int col)
{int x = 0, y = 0;int win = 0;while (win < row*col - EsayCount){printf("请输入要排查的坐标:>");scanf("%d %d", &x, &y);if (x >= 1 && x <= row && y >= 1 && y <= col){if (mine[x][y] == '1'){printf("很遗憾,你被炸死了\n");DisPalyBoard(mine, ROW, COL);break;}else{//该坐标不是雷,就得统计该坐标的周围有几个雷int count = GetMineCount(mine, x, y);show[x][y] = count + '0';DisPalyBoard(show, ROW, COL);win++;}}else{printf("坐标非法,请重新输入\n");}}if (win == row * col - EsayCount){printf("恭喜你,排雷成功\n");DisPalyBoard(mine, ROW, COL);}
}
1.7 周围没有雷就展开一片
首先需要判断所选坐标的周围是否有雷,即判断count是否等于0,如果所选坐标周围没有雷的话,就将此坐标的周围的坐标都调用显示雷的数量的函数。当然还需要判断一下坐标是否为‘*’,如果没有这个判断它就会重复的调用函数,从而进入了死循环。
void arr(char mine[ROWS][COLS], char show[ROWS][COLS], int x,int y)
{if (show[x][y] == '*'){int count = GetMineCount(mine, x, y);show[x][y] = count + '0';if (x >= 1 && x <= ROW && y >= 1 && y <= ROW){if (count == 0){arr(mine, show, x - 1, y);arr(mine, show, x - 1, y - 1);arr(mine, show, x - 1, y + 1);arr(mine, show, x, y - 1);arr(mine, show, x, y + 1);arr(mine, show, x + 1, y - 1);arr(mine, show, x + 1, y + 1);arr(mine, show, x + 1, y);}}}
}1.8 计算游戏时间
time函数可以返回一个时间戳,我们可以利用这个函数计算游戏的时间。
int y = time(NULL);
while (1)
{system("cls");int x = time(NULL) - y;printf("%d", x);Sleep(1000);
}1.9 游戏可改性
因为在写这个程序时需要输入很多的数字,如果我们想修改这些数时就要一个一个改,这样非常的麻烦。为了避免这些麻烦我们只需要在头文件定义某字符等于某个数字就可以了,这样我们想改游戏参数的时候在头文件game.h改就行了。
#define ROW 9
#define COL 9#define ROWS ROW+2
#define COLS COL+2
#define EsayCount 10比如当我们想改行和列改为16炸弹数量改为40的时候,我们只需要在头文件将ROW 与 COL定义为16就可以了。
#define ROW 16
#define COL 16#define ROWS ROW+2
#define COLS COL+2
#define EsayCount 40 
1.10 控制台颜色的修改
使用system("color attr");函数可以修改控制台颜色,这个函数需要使用#include<windonws.h>调用。颜色可以参考下面这张图:

例:

2. 完整代码
2.1 game.h头文件
#pragma once
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<stdlib.h>
#include<time.h>
#include<windows.h>
#define ROW 9
#define COL 9#define ROWS ROW+2
#define COLS COL+2
#define EsayCount 10//声明函数
void InitBoard(char arr[ROWS][COLS], int rows, int cols, char test);
//
void DisPalyBoard(char arr[ROW][COL], int row, int col, int o);
//布置雷的信息
void SetMine(char arr[ROWS][COLS], int row, int col, int o);
//排查雷
void FindMine(char mine[ROWS][COLS], char show[ROWS][COLS], int row, int col, int o);2.2 game.c文件
#include"game.h"
void InitBoard(char arr[ROWS][COLS], int rows, int cols, char set)
{int i = 0;for (i = 0; i < rows; i++){for (int j = 0; j < cols; j++){arr[i][j] = set;}}
}
void DisPalyBoard(char arr[ROWS][COLS], int row, int col,int o)
{//清屏system("cls");printf("-----------扫雷游戏----------\n");//计算时间printf("已用时间:%ds\n", time(NULL) - o);int i = 0;for (i = 0; i <= col; i++){printf("%2d ", i);}printf("\n");for (i = 1; i <= row; i++){printf("%2d ", i);for (int j = 1; j <= col; j++){printf("%2c ", arr[i][j]);}printf("\n");}
}void SetMine(char arr[ROWS][COLS], int row, int col)
{int count = EsayCount;while (count){int x = rand() % row + 1;int y = rand() % col + 1;if (arr[x][y] == '0'){arr[x][y] = '1';count--;}}
}int GetMineCount(char mine[ROWS][COLS], int x, int y)
{//return (mine[x - 1][y] + mine[x - 1][y - 1] + mine[x][y - 1] + mine[x + 1][y - 1] // + mine[x + 1][y + 1] + mine[x - 1][y + 1] + mine[x + 1][y] + mine[x][y + 1] - 8 * '0');int a = 0;for (int i = x - 1; i <= x + 1; i++){for (int j = y - 1; j <= y + 1; j++){a += mine[i][j];}}return a - '0' * 9;
}int win = 0;
void arr(char mine[ROWS][COLS], char show[ROWS][COLS], int x,int y)
{if (show[x][y] == '*'&& x >= 1 && x <= ROW && y >= 1 && y <= ROW){int count = GetMineCount(mine, x, y);show[x][y] = count + '0';win++;if (count == 0){arr(mine, show, x - 1, y);arr(mine, show, x - 1, y - 1);arr(mine, show, x - 1, y + 1);arr(mine, show, x, y - 1);arr(mine, show, x, y + 1);arr(mine, show, x + 1, y - 1);arr(mine, show, x + 1, y + 1);arr(mine, show, x + 1, y);}}
}void FindMine(char mine[ROWS][COLS], char show[ROWS][COLS], int row, int col, int o)
{int x = 0, y = 0;while (win < row * col - EsayCount){printf("请输入要排查的坐标(0 0重开):>");scanf("%d %d", &y, &x);if (x >= 1 && x <= row && y >= 1 && y <= col){if (mine[x][y] == '1'){DisPalyBoard(mine, ROW, COL, o);printf("你被炸死了!!!\n");break;}else{//该坐标不是雷,就得统计该坐标的周围有几个雷arr(mine, show, x, y);DisPalyBoard(show, ROW, COL, o);}}else if (x == 0 && y == 0){printf("重新开始游戏。\n");break;}else{printf("坐标非法,请重新输入\a\n");}}if (win == row * col - EsayCount){DisPalyBoard(mine, ROW, COL, o);printf("恭喜你,排雷成功\n");}
}2.3 test.c文件
#include"game.h"void menu()
{printf("----------------扫雷----------------\n");printf("| |\n");printf("| 1.play |\n");printf("| 0.exit |\n");printf("| |\n");printf("------------------------------------\n");
}void game()
{int o = time(NULL);//存放布置好雷的信息char mine[ROWS][COLS] = { 0 };char show[ROWS][COLS] = { 0 };InitBoard(show, ROWS, COLS, '*');InitBoard(mine, ROWS, COLS, '0');//随机布置10个雷SetMine(mine, ROW, COL, o);//打印棋盘/*DisPalyBoard(mine, ROW, COL,o);*/DisPalyBoard(show, ROW, COL, o);//排查雷FindMine(mine, show, ROW, COL, o);
}
int main()
{int input = 0;srand((unsigned int)time(NULL));do{menu();printf("请选择:>");scanf("%d", &input);switch (input){case 1:game();break;case 0:printf("游戏结束,退出游戏\n");break;default:printf("输入错误请重新输入\a\n");}} while (input);return 0;
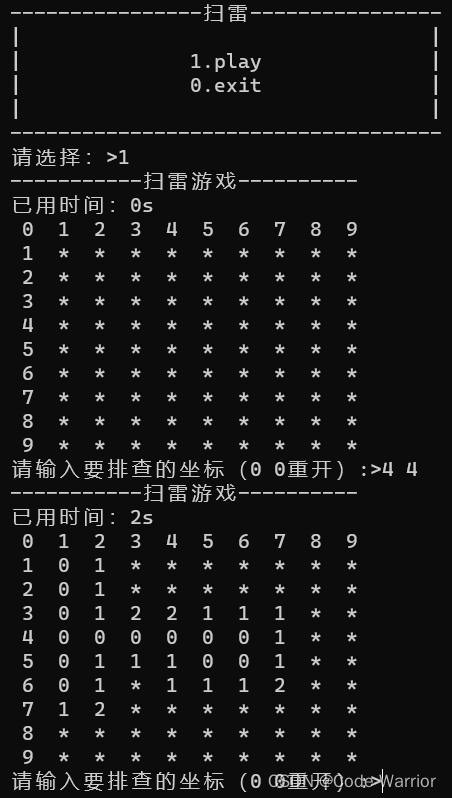
}2.4 效果图: