阿里云做电脑网站用asp做网站需要的软件
AD/DA介绍
AD(Analog to Digital):模拟-数字转换,将模拟信号转换为计算机可操作的数字信号
DA(Digital to Analog):数字-模拟转换,将计算机输出的数字信号转换为模拟信号
AD/DA转换打开了计算机与模拟信号的大门,极大的提高了计算机系统的应用范围,也为模拟信号数字化处理提供了可能。

硬件电路模型
AD转换通常有多个输入通道,用多路选择开关连接至AD转换器,以实现AD多路复用的目的,提高硬件利用率。
AD/DA与单片机数据传送可使用并口(速度快、原理简单),也可使用串口(接线少、使用方便)
可将AD/DA模块直接集成在单片机内,这样直接写入/读出寄存器就可进行AD/DA转换,单片机的IO口可直接复用为AD/DA的通道。

硬件电路

• 单独供电
• PCF8591 的操作电压范围2.5V-6V
• 低待机电流
• 通过I²C 总线串行输入/输出
• PCF8591 通过3 个硬件地址引脚寻址
• PCF8591 的采样率由I²C 总线速率决定
• 4 个模拟输入可编程为单端型或差分输入
• 自动增量频道选择
• PCF8591 的模拟电压范围从VSS 到VDD
• PCF8591 内置跟踪保持电路
• 8-bit 逐次逼近A/D 转换器
DA原理


AD原理

AD / DA一般性能指标

XPT2046


XPT2046.c

#include <REGX52.H>
#include <INTRINS.H>//引脚定义
sbit XPY2046_DIN=P3^4;
sbit XPY2046_CS=P3^5;
sbit XPY2046_DCLK=P3^6;
sbit XPY2046_DOUT=P3^7;/*** @brief ZPT2046读取AD值* @param Command 命令字,范围:头文件内定义的宏,结尾的数字表示转换的位数* @retval AD转换后的数字量,范围:8位为0~255,12位为0~4095*/
unsigned int XPT2046_ReadAD(unsigned char Command)
{unsigned char i;unsigned int Data=0;XPY2046_DCLK=0; //初始化XPY2046_CS=0; //初始化for(i=0;i<8;i++) //循环依次把8位发出去{XPY2046_DIN=Command&(0x80>>i); //最高位XPY2046_DCLK=1;XPY2046_DCLK=0;}for(i=0;i<16;i++){XPY2046_DCLK=1;XPY2046_DCLK=0;if(XPY2046_DOUT){Data|=(0x8000>>i);}}XPY2046_CS=1;return Data>>8;
}
主函数
#include <REGX52.H>
#include "Delay.h"
#include "LCD1602.h"
#include "XPT2046.h"unsigned int ADValue;void main(void)
{LCD_Init();LCD_ShowString(1,1,"ADJ NTC GR");while(1){ADValue=XPT2046_ReadAD(XPT2046_XP); //读取AIN0,可调电阻LCD_ShowNum(2,1,ADValue,3); //显示AIN0ADValue=XPT2046_ReadAD(XPT2046_YP); //读取AIN1,热敏电阻LCD_ShowNum(2,6,ADValue,3); //显示AIN1ADValue=XPT2046_ReadAD(XPT2046_VBAT); //读取AIN2,光敏电阻LCD_ShowNum(2,11,ADValue,3); //显示AIN2Delay(100);}
}
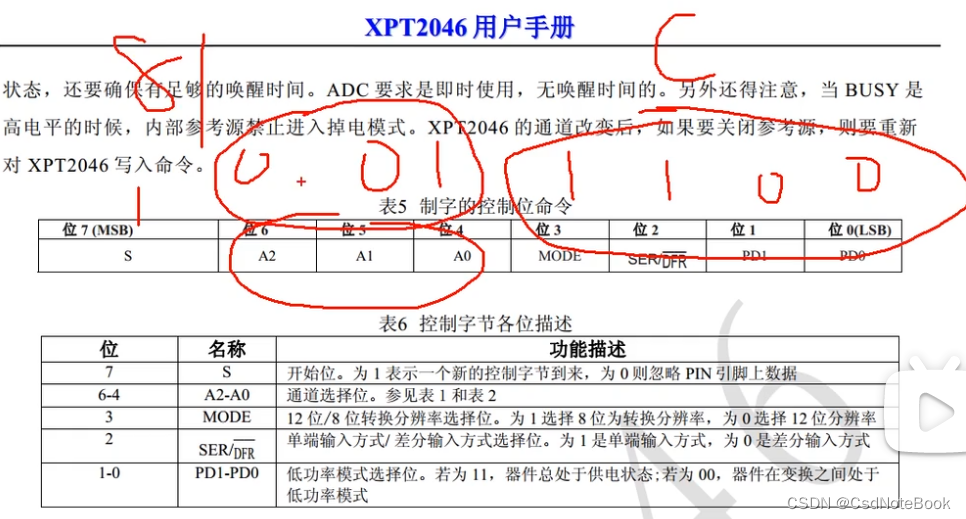
#ifndef __XPT2046_H__
#define __XPT2046_H__
//AIN0-AIN3
#define XPT2046_VBAT 0xAC
#define XPT2046_AUX 0xEC
#define XPT2046_XP 0x9C //0xBC
#define XPT2046_YP 0xDCunsigned int XPT2046_ReadAD(unsigned char Command);#endif