网站页面吸引力南宁百度seo网站优化
售后派单管理系统优化售后服务流程,提升响应速度、运营效率和服务质量。ZohoDesk等系统通过自动化派单、实时调度监控等功能,助力企业赢得竞争优势。适用于电子产品、汽车、IT及房地产等行业。

一、什么是售后派单管理系统
售后派单管理系统是一种专门用于管理和优化售后服务流程的信息系统。它通过自动化工具与技术,帮助企业计划、执行和监控售后服务任务的整个过程。系统主要功能包括接收客户服务请求、自动化派单、任务调度、服务追踪、反馈收集以及报告生成等。
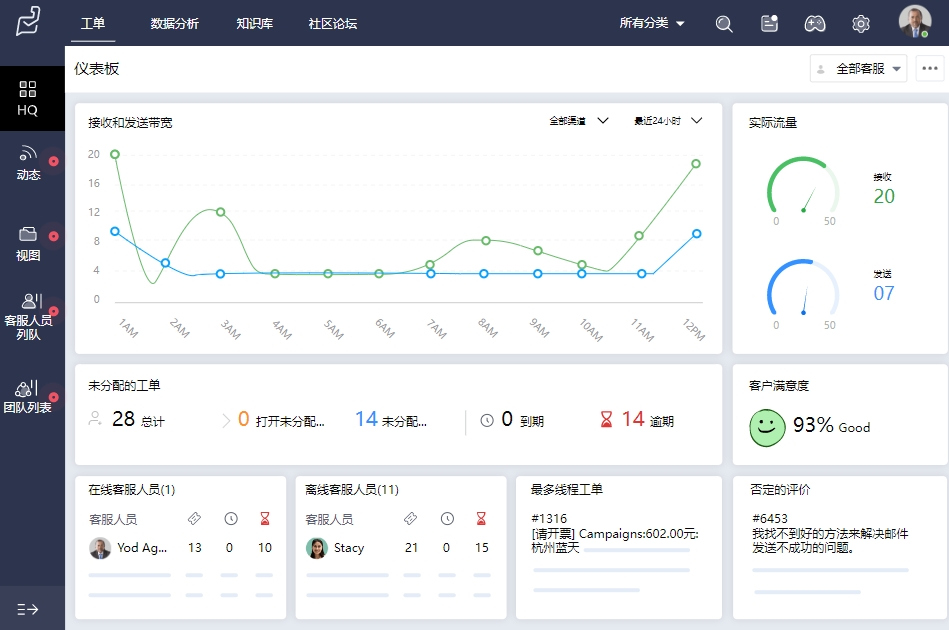
二、售后派单系统有什么功能
1. 自动化派单
系统可以根据预设的规则自动向合适的服务人员派发任务,减少人工介入,提升分配效率。Zoho Desk利用智能算法快速派单,确保派单的精准与高效。
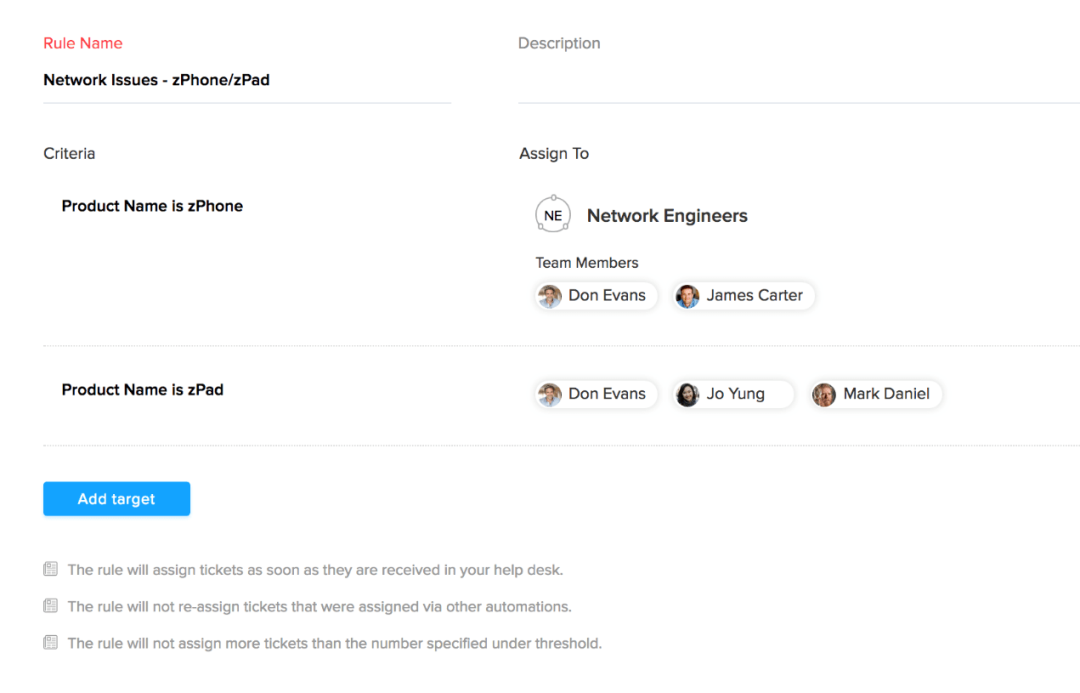
2. 实时调度监控
管理者可以实时监控服务流程和任务进程,及时调整资源和人力,确保服务的高效执行。通过Zoho Desk的实时仪表盘,管理者能够直观掌控每一项任务的进展。
3. 服务追踪与管理
系统提供完整的服务记录追踪功能,包括服务开始、过程和结束的所有详细信息,方便日后查询和管理。Zoho Desk支持详细的服务记录和历史查看,确保每个服务事件有据可查。
4. 客户交互管理
整合客户交互界面,允许客户跟踪服务进度,提交进一步的请求或反馈,增加服务的透明度和互动性。Zoho Desk提供专属的客户门户,客户可以实时查询服务状态并进行互动。
5. 数据分析与报告
生成详细的服务报告和分析,帮助企业理解服务效果,评估员工表现,优化服务流程。Zoho Desk内置强大报告功能,帮助企业在数据驱动下持续优化服务质量。
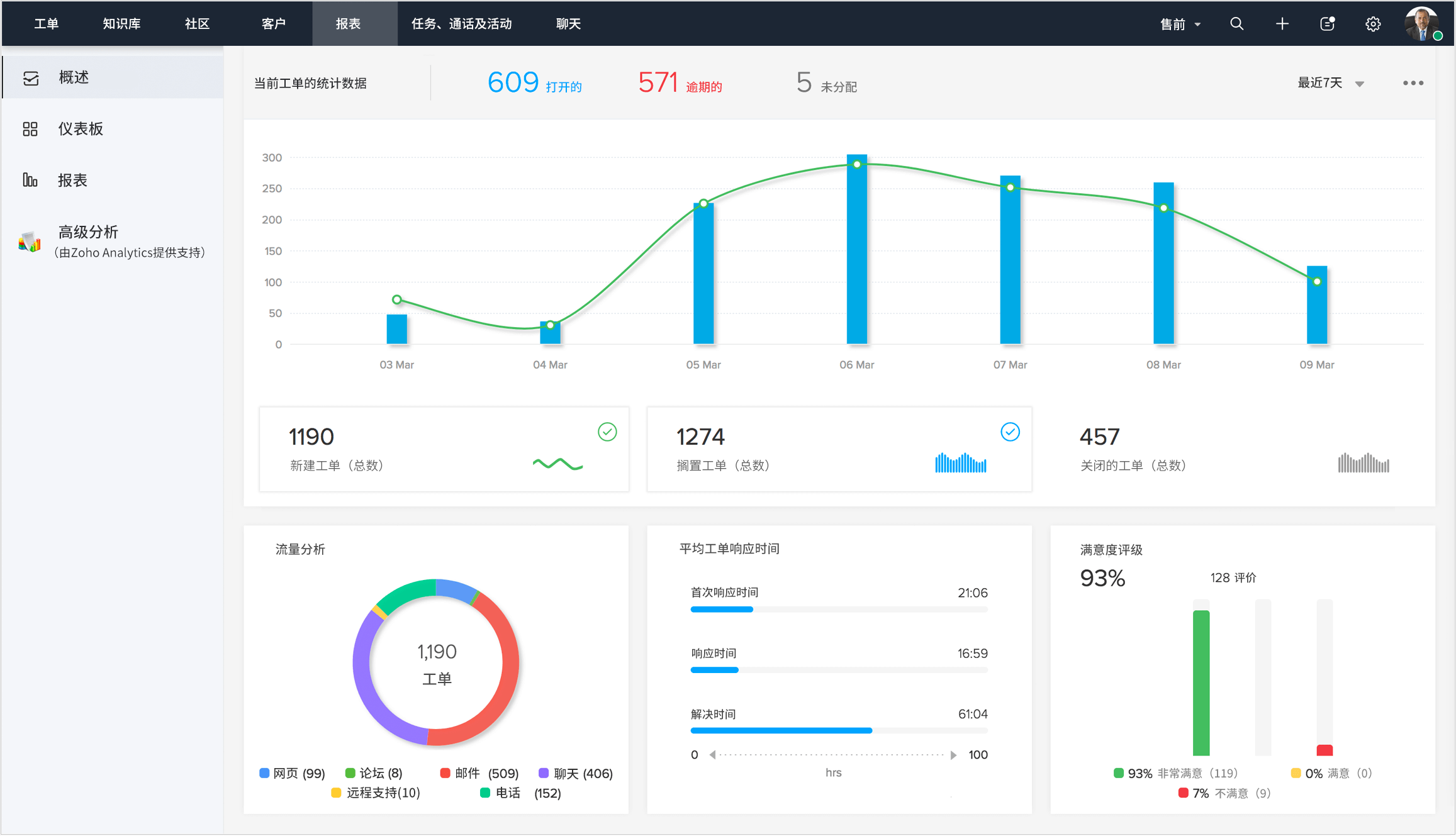
三、企业需要售后派单管理系统吗
1. 提高响应速度
通过自动化的派单系统,可以更快地响应客户请求,缩短客户���待时间,提升客户满意度。Zoho Desk自动化派单显著缩短了响应时间,提升了客户体验。
2. 增加运营效率
自动化和优化的工作流程减少了人力成本,提升了运营效率,使企业能够以更低的成本提供更高质量的服务。Zoho Desk优化的流程设计,提高了整体运营效率。
3. 增强服务质量
系统确保每一个服务请求都得到适当处理,减少错误和遗漏,提高服务质量。凭借Zoho Desk的追踪和管理机制,每个请求都有最佳的处理路径。
4. 促进数据驱动决策
详细的数据报告和分析帮助管理者更好地理解服务流程中的各种动态,促进基于数据的决策。利用Zoho Desk的数据分析,企业管理者可以做出更加准确、可靠的决策。
四、有什么行业需要售后派单系统
1. 电子产品制造业
在电子产品制造业中,售后派单系统能够有效管理维修任务,为复杂的电子产品故障提供迅速的技术支持,维护品牌声誉。Zoho Desk在电子维修中的应用,确保每个维修任务的高效处理。
2. 汽车销售与服务行业
该系统可以协助汽车销售商管理日益增加的维修和保养请求,优化技师的调度,提高服务站的工作效率。通过Zoho Desk,汽车服务中心实现了维修工单的智能调度,极大提高了效率。
3. IT和软件服务
在IT行业,快速响应软件故障和技术支持请求对于保持系统稳定运行至关重要,派单系统可以帮助快速定位问题并派出最合适的技术人员进行处理。Zoho Desk在IT服务中的应用,使得技术支持更加高效、准确。
4. 房地产维修服务
对于物业管理公司而言,及时响应住户报修请求并有效调度维修工作是保证住户满意和物业管理效率的关键。Zoho Desk在物业管理中的应用,显著提高了维修服务的响应速度和住户满意度。
随着技术的不断进步和行业需求的不断变化,售后派单管理系统正逐步向更高效、智能化方向发展。AI(人工智能)技术的整合,例如自然语言处理和机器学习,正在使这些系统更加智能化,能够预测服务需求,自动优化资源分配。