优化网站排名的方法上海自贸区注册公司的条件
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn]
如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~
1、修改配置文件:
sudo vim /etc/lighttpd/lighttpd.conf
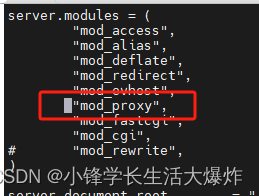
2、先添加mod_proxy:
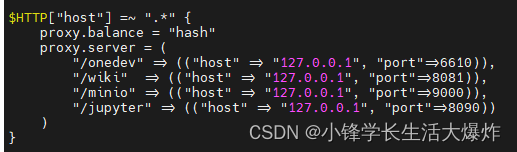
3、然后添加端口映射:
4、保存,并检查配置是否正确(没输出就是正确):
sudo lighttpd -tt -f /etc/lighttpd/lighttpd.conf5、重启lighttpd服务:
sudo systemctl restart lighttpd6、查看效果,格式:http://<ip>/<名称>
如果没有服务,可以启动一个http服务端:
python -m http.server 6610