网站进度表国外有在线做设计方案的网站吗
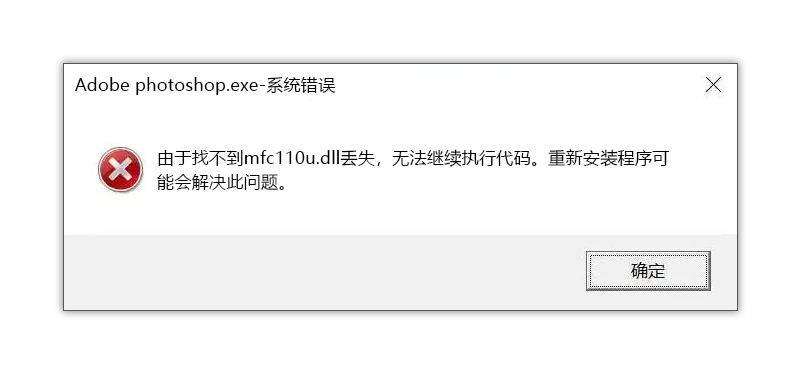
当你打开某个软件或者运行游戏,系统提示mfc100u.dll丢失,此时这个软件或者游戏根本无法运行。其实,mfc100u.dll是动态库文件,它是VS2010编译的软件所产生的,如果电脑运行程序时提示缺少mfc100u.dll文件,程序或者游戏自然就无法打开了。
mfc100u.dll缺失是什么意思:
当系统提示mfc100u.dll缺失时,意味着计算机上缺少了该动态链接库文件。动态链接库文件(DLL)是一种包含可被多个程序共享的代码和资源的文件。mfc100u.dll是Microsoft Foundation Class (MFC)库的一个组件,用于开发Windows应用程序。因此,当某个应用程序依赖于mfc100u.dll文件但无法找到该文件时,会导致相关的应用程序无法正常启动或运行。
出现mfc100u.dll缺失的原因可能有:
-
该文件被误删除或移动到其他位置。
-
该文件被某个安全软件或系统工具误报并删除。
-
该文件被病毒或恶意软件感染并删除。
修复方法分享:
方法一:重新安装相关应用程序
在控制面板中,找到并卸载与mfc100u.dll文件相关的应用程序。然后,重新下载并安装最新版本的该应用程序。
方法二:安装mfc100u.dll修复文件
mfc100u.dll修复文件是打包的c++运行库文件,可以自动检测安装mfc100u.dll文件到系统对应的目录中。使用百度等搜索引擎从Internet互联网或者到微软官网下载一个mfc100u.dll修复文件或
在电脑浏览器顶部输入:dll修复工具.site【按下键盘上的Enter回车键打开】点击dll修复工具下载。(亲测可以修复)
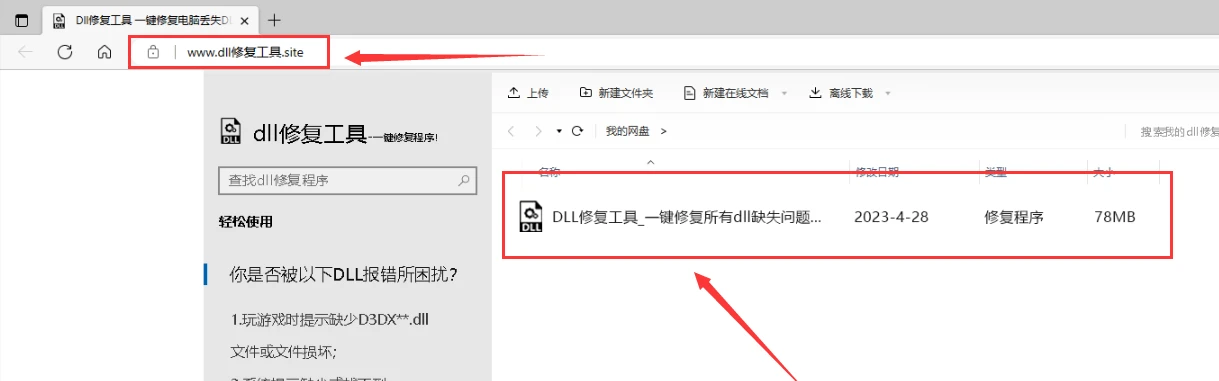
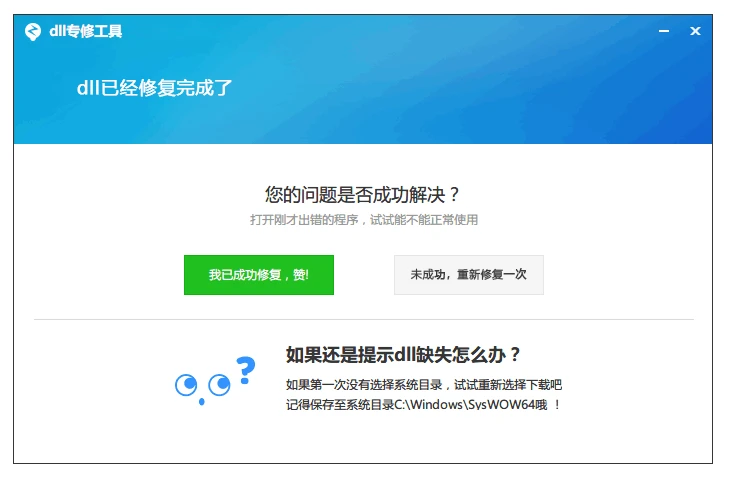
下载到电脑上的文件一般是压缩包的形式,需要先把文件解压,然后安装后点击修复【立即修复】,修复的文件都是在系统目录中。
如果您的计算机是32位系统,则将文件到C:\Windows\System32,如果是64位系统,则将文件到C:\Windows\SysWOW64。完成后,你可以尝试再次运行有问题的程序以测试问题。
方法三:你可以下载一个mfc100u.dll文件复制到相应的系统目录中。
下载后打开文件夹,里面有32和4两个文件格式,文件夹中有mfc100u.dll文件,注意:这两个文件夹中的mfc100u.dll文件是不一样的,不要混淆了。
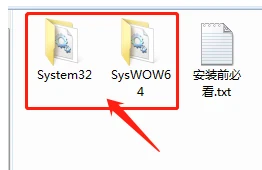
接下来,你只要将相应的文件复制到相应的目录里面就行了。
-
如果你是32位系统,只需要将System32里面的文件复制到C:\WINNT\System32路径下就行。
-
如果你是64位系统,你需要将mfc100u.dll复制到C:\Windows\SysWOW64文件夹中。
mfc100u.dll是Microsoft Foundation Class (MFC)库的动态链接库文件之一。MFC是Microsoft Visual C++开发工具包中的一个组件,用于开发Windows应用程序。mfc100u.dll包含了MFC库的一些函数和资源,它提供了一系列用于创建图形用户界面(GUI)和处理Windows操作系统的功能。这个文件通常与通过MFC库编写的应用程序一起分发,以确保应用程序能够正确地加载和运行所需的MFC功能。
如果在运行使用MFC库编写的应用程序时,系统提示缺少mfc100u.dll文件,则可能会导致应用程序无法正常启动或运行。在这种情况下,可以尝试以上解决方法进行修复。