做网站怎么维护昌吉住房和城乡建设局网站
文章目录
- 前言
- Java NIO 工作原理
- Selector 的创建
- ServerSocketChannel 的创建
- ServerSocketChannel 注册 Selector
- 对事件的处理
- 总结
前言
上篇文章《Netty 入门指南》主要涵盖了 Netty 的入门知识,包括 Netty 的发展历程、核心功能与组件,并且通过实例演示了如何使用 Netty 构建一个 HTTP 服务器。由于 Netty 的抽象程度较高,因此理解起来可能会更加复杂和具有挑战性,所以本文将通过 Java NIO 的处理流程与 Netty 的总体流程比较,并结合 Netty 的源码更加清晰地理解Netty。
Java NIO 工作原理
首先我们知道Netty是基于Java NIO的一个网络应用框架,是在其基础上进行封装和扩展(所以在深入了解Netty之前,建议先对Java NIO有一定的了解),所以二者对网络的连接、读取和写入的操作方式是相似的。
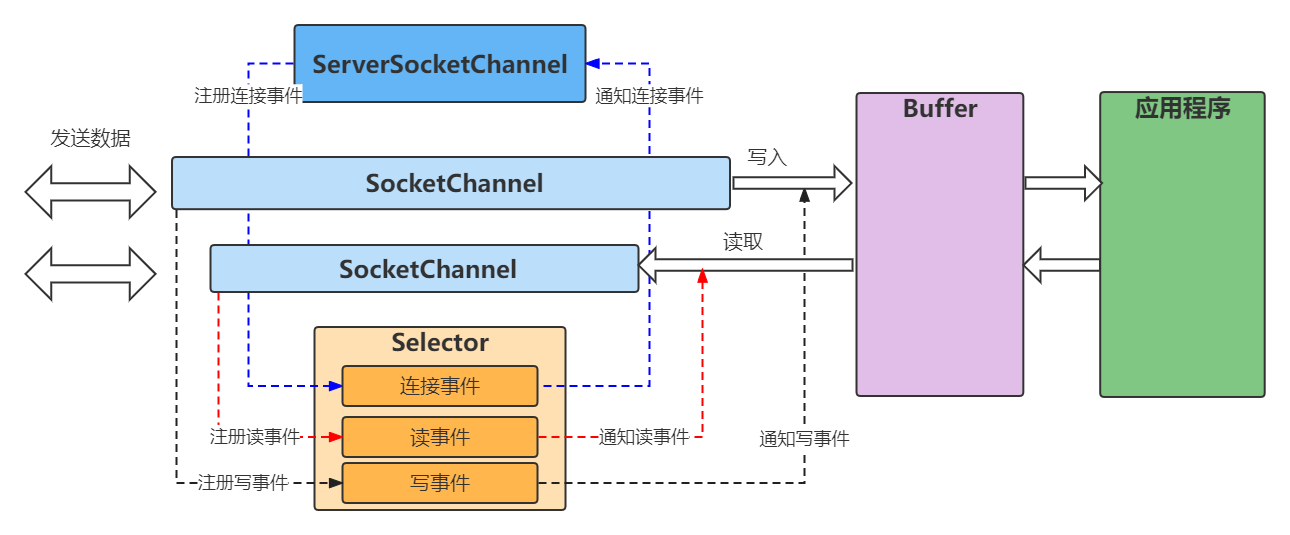
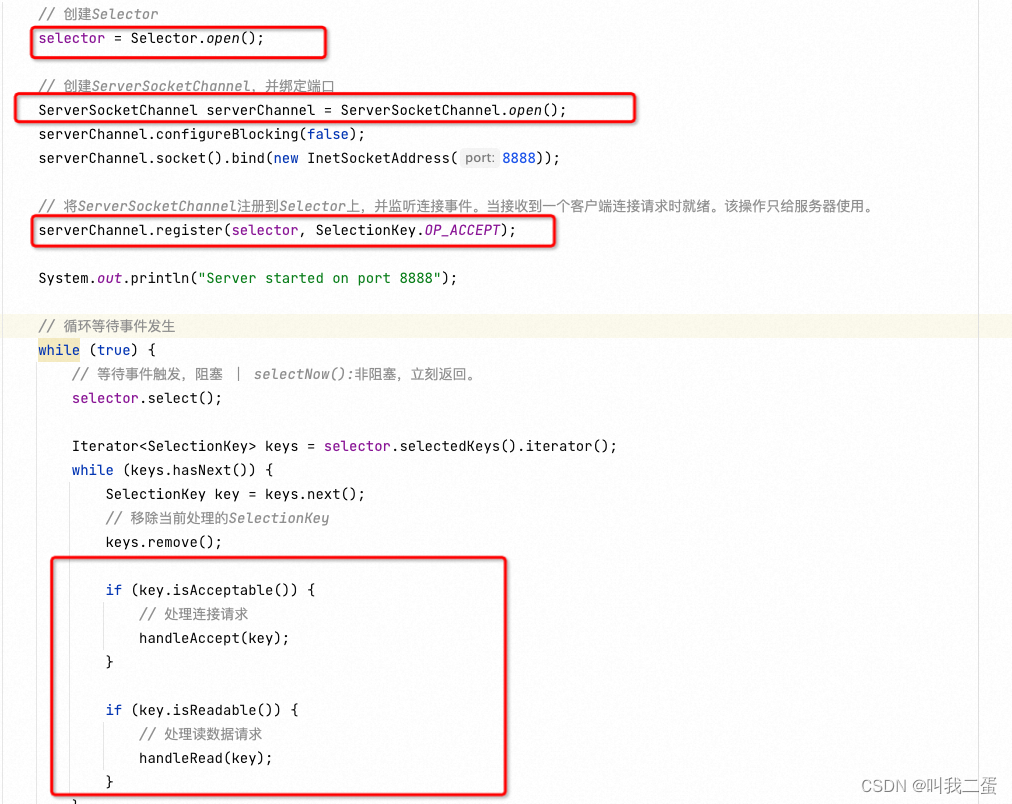
如上图的Java NIO的处理流程,与Java NIO代码示例结合,可以看到,将 ServerSocketChannel 注册到 Selector 并监听各个事件后,Selector 在接受到事件请求后我们业务代码对其进行判断并对应处理,在使用Netty时我们似乎不需要写这些代码,甚至都没有看见Selector、ServerSocketChannel这些字眼,那这些代码在Netty中怎么体现的,我们扒开裤子看个究竟:
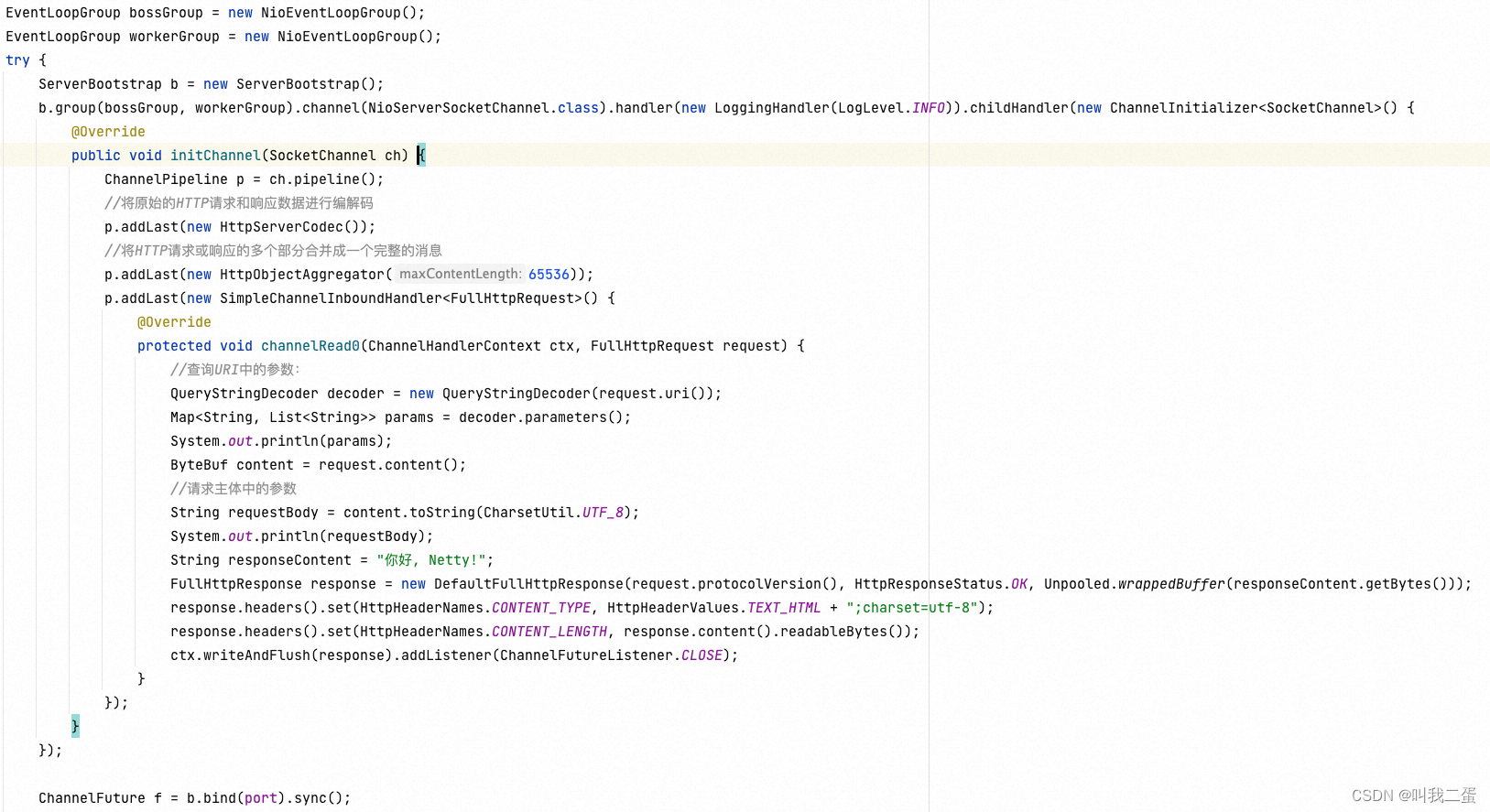
以上文Netty构建的HTTP服务器示例为例,直接关注 ServerSocketChannel 、Selector 是什么时候创建的,事件是什么时候注册以及处理的。
Selector 的创建
其实看了上篇的Netty入门,可以知道 EventLoop 负责处理各种事件,所以可以盲猜一下,Selector 应该是在 NioEventLoopGroup 中创建的,look
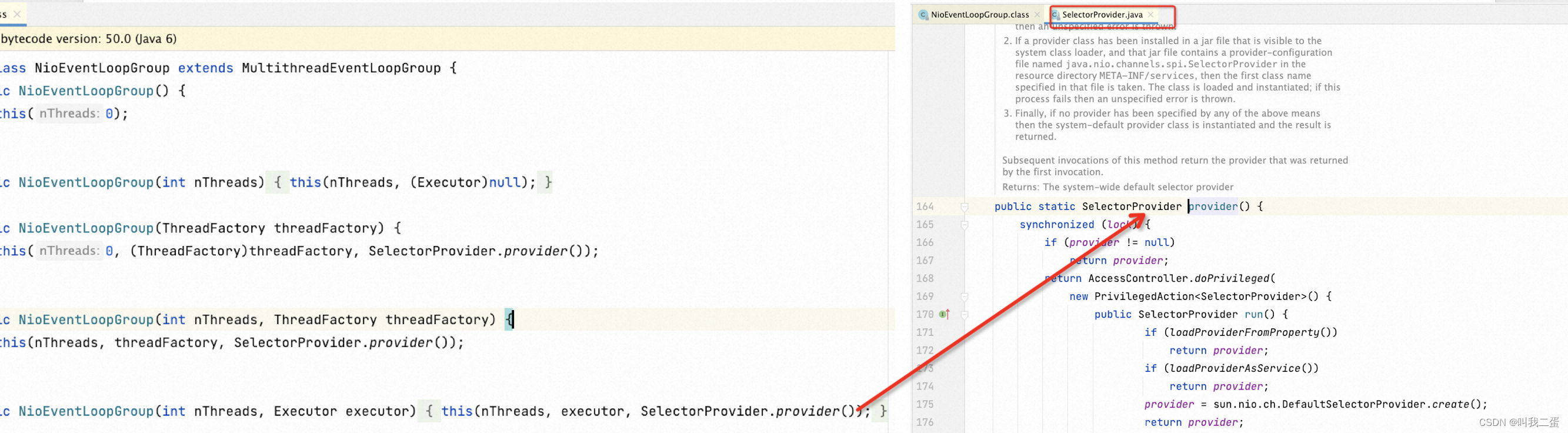
在 NioEventLoopGroup 的构造方法中调用 JDK 的 SelectorProvider 创建了Selector,也就是 Java NIO 的代码。
ServerSocketChannel 的创建
关于 ServerSocketChannel 的创建,直接找绑定端口的方法,如下图
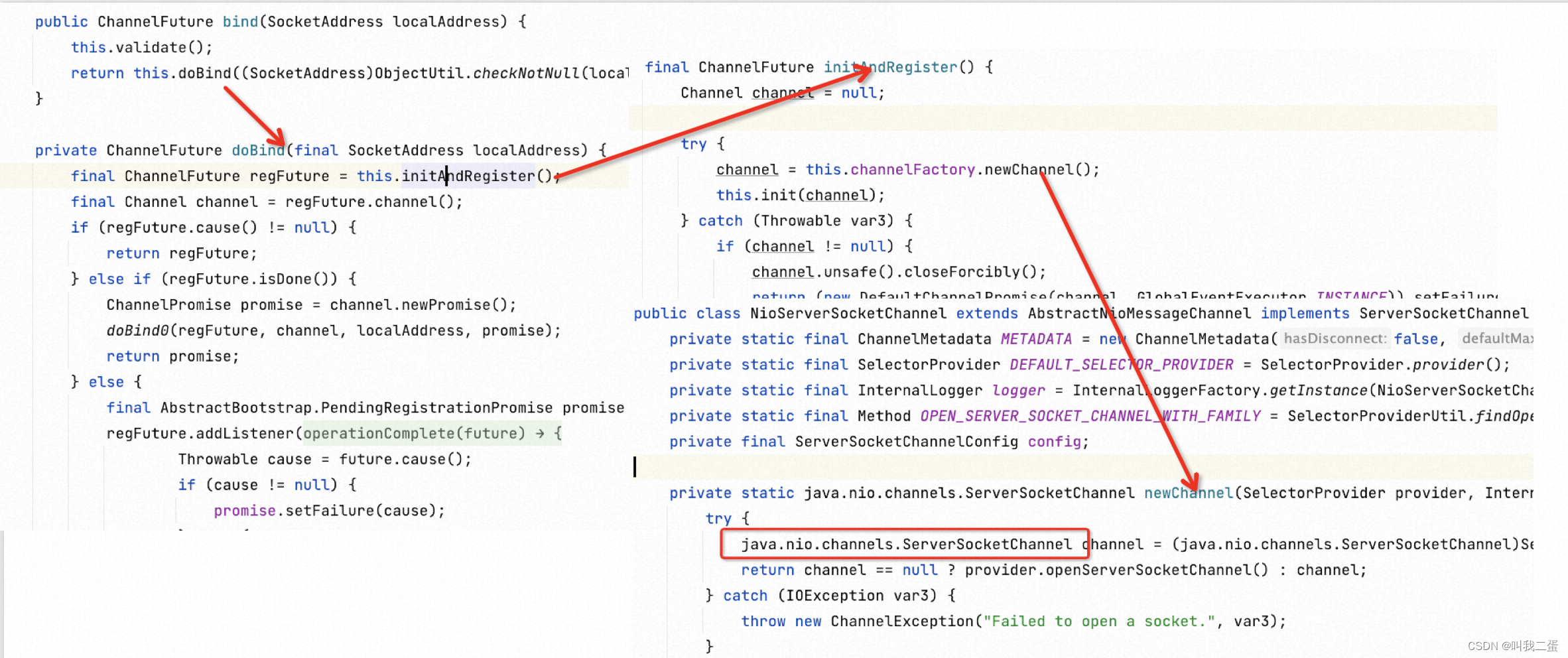
同样,在 Netty 的代码 NioServerSocketChannel 的newChannel() 中也看到 Java NIO 的代码。
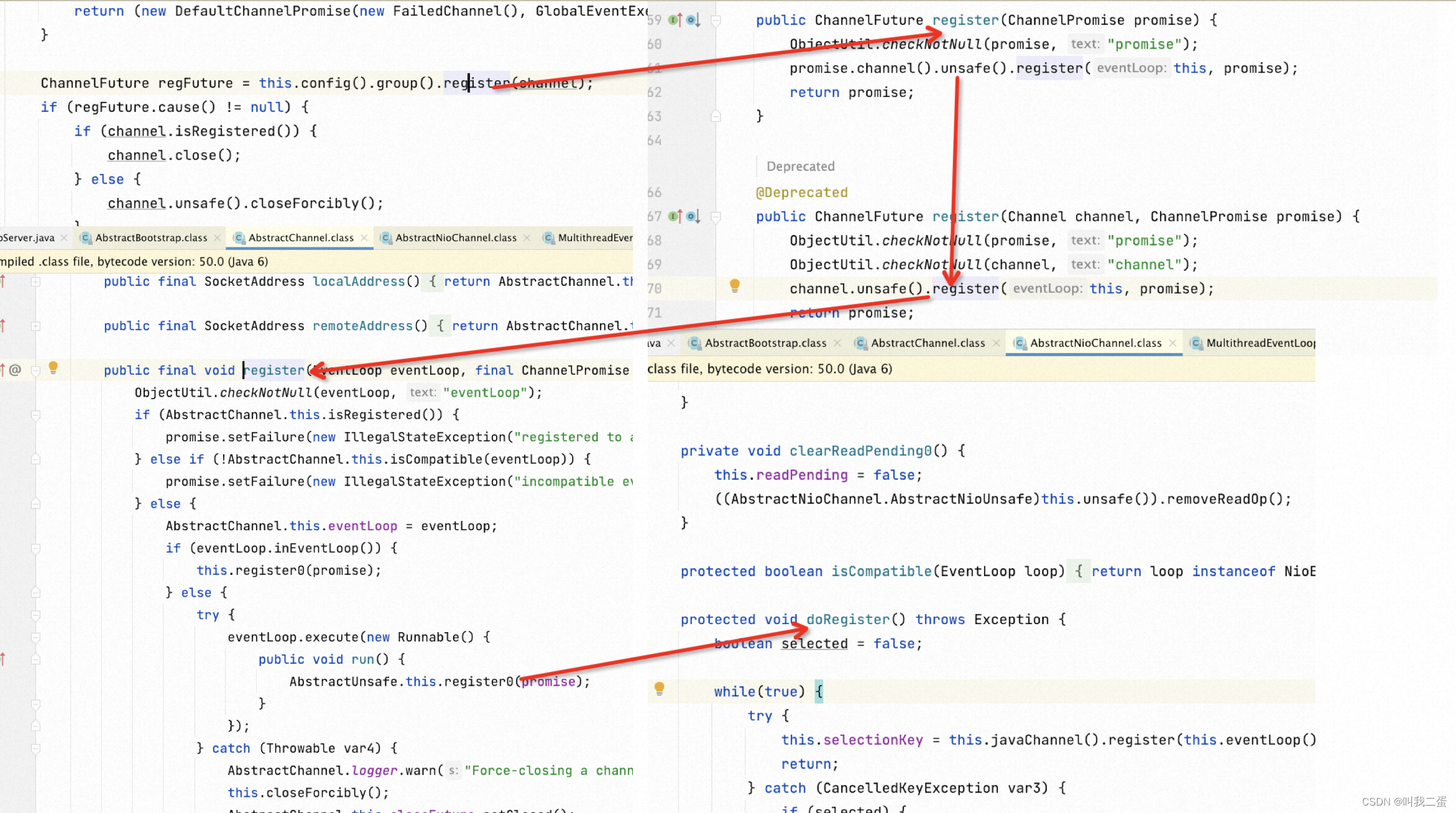
ServerSocketChannel 注册 Selector
下图中 ServerSocketChannel 在创建后为其分配了一个 EventLoop 并开启新的线程(这也是Netty 多线程异步的体现),最终在 doRegister() 调用了JDK 的接口注册了Selector 并监听了事件,看见 selectionKey 应该什么都清楚了吧。
对事件的处理
既然 ServerSocketChannel 注册了Selector 并监听了事件,那接下来就是当有事件来时 EventLoop 对其进行处理,直接看 NioEventLoop 中的代码,因为他是通过新的线程启动的,所以直接看 run()

processSelectedKeysPlain() 中的代码熟悉吧,是监听到了某个事件可以进行处理了,下面是对读事件的处理
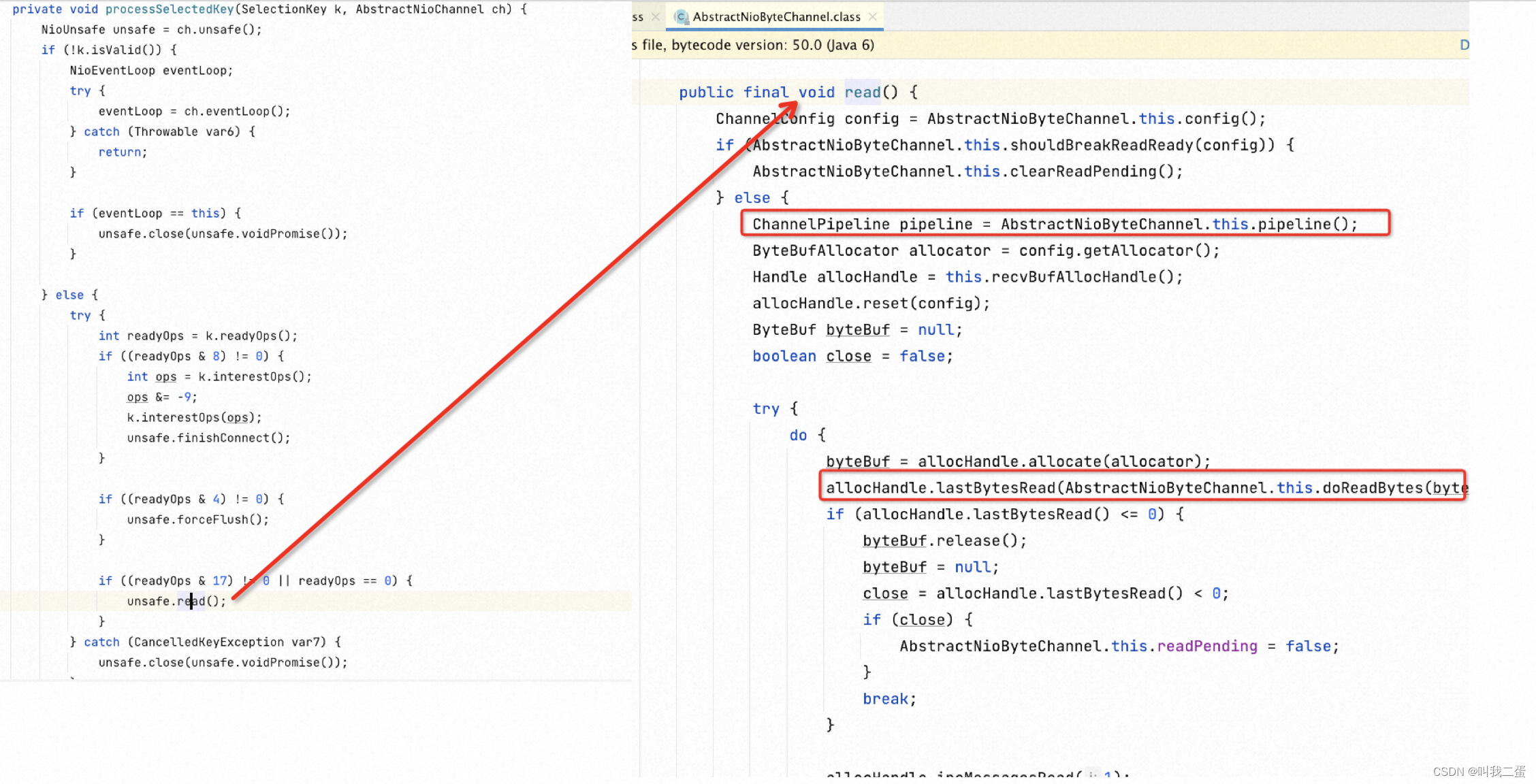
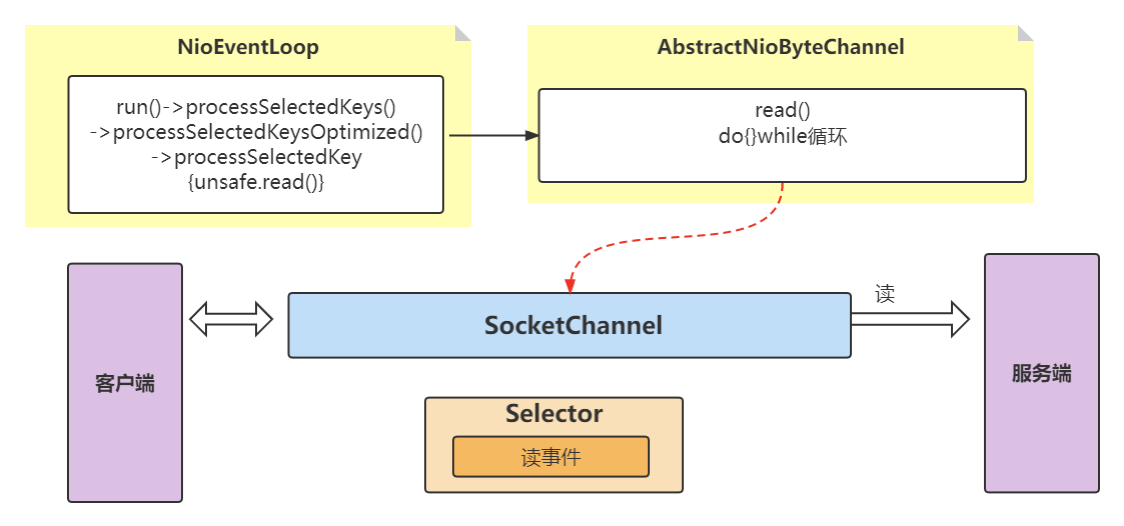
图中 ChannelPipeline 采用了责任链模式是对事件的处理通道,方便扩展。所以 Netty 中的读取事件与 Java NIO 的关系如下图。
总结
所以在接触 Netty 的之前一定要先掌握 Java NIO,本文只是介绍了 Java NIO 在 Netty 中的体现、Netty 对 Java NIO 的封装,让大家更方便的理解 Netty,并不涉及 Netty 的高效、强大的设计之处,下文将会对此进行介绍。