怎么自己做投票网站网站建设商虎小程序
一、 数理逻辑
[复习知识点]
1、命题与联结词(否定¬、析取∨、合取∧、蕴涵→、等价↔),命题(非真既假的陈述句),复合命题(由简单命题通过联结词联结而成的命题)
2、命题公式与赋值(成真、成假),真值表,公式类型(重言、矛盾、可满足),公式的基本等值式

3、范式:析取范式、合取范式,极大(小)项,主析取范式、主合取范式
4、公式类型的判别方法:真值表法、等值演算法、主析取/合取范式法
5、命题逻辑的推理理论


6、谓词、量词、个体词(公式一阶逻辑3要素)、个体域、变元(约束出现与自由出现)
7、命题符号化、谓词赋值与解释,谓词公式的类型(永真、永假、可满足)
8、谓词公式的等值式(代换实例、消去量词、量词否定和量词辖域收与扩、量词分配)和置换规则(置换规则、换名规则)
9、一阶逻辑前束范式(定义、求法)
本章重点内容:命题与联结词、公式与解释、(主)析取范式与(主)合取范式、公式类型的判定、命题逻辑的推理、谓词与量词、命题符号化、谓词公式赋值与解释、求前束范式。
[复习要求]
1、理解命题的概念;了解命题联结词的概念;理解用联结词产生复合命题的方法。
2、理解公式与赋值的概念;掌握求给定公式真值表的方法,用基本等值式化简其它公式,公式在解释下的真值。
3、了解析取(合取)范式的概念;理解极大(小)项的概念和主析取(合取)范式的概念;掌握用基本等值式或真值表将公式化为主析取(合取)范式的方法。
4、掌握利用真值表、等值演算法和主析取/合取范式的唯一性判别公式类型和公式等价方法。
5、掌握命题逻辑的推理理论。
6、理解谓词、量词、个体词、个体域、变元的概念;理解用谓词、量词、逻辑联结词描述一个简单命题;掌握命题的符号化。
7、理解公式与解释的概念;掌握在有限个体域下消去公式量词,求公式在给定解释下真值的方法;了解谓词公式的类型。
8、掌握求一阶逻辑前束范式的方法。
二、 集 合
[复习知识点]
1、集合、元素、集合的表示方法(列元素法、谓词表示法)、子集、空集、全集、集合的包含、相等、幂集
2、集合的交、并、差、补以及对称差等运算及有穷集的计数(文氏(Venn)图、包含排斥原理)
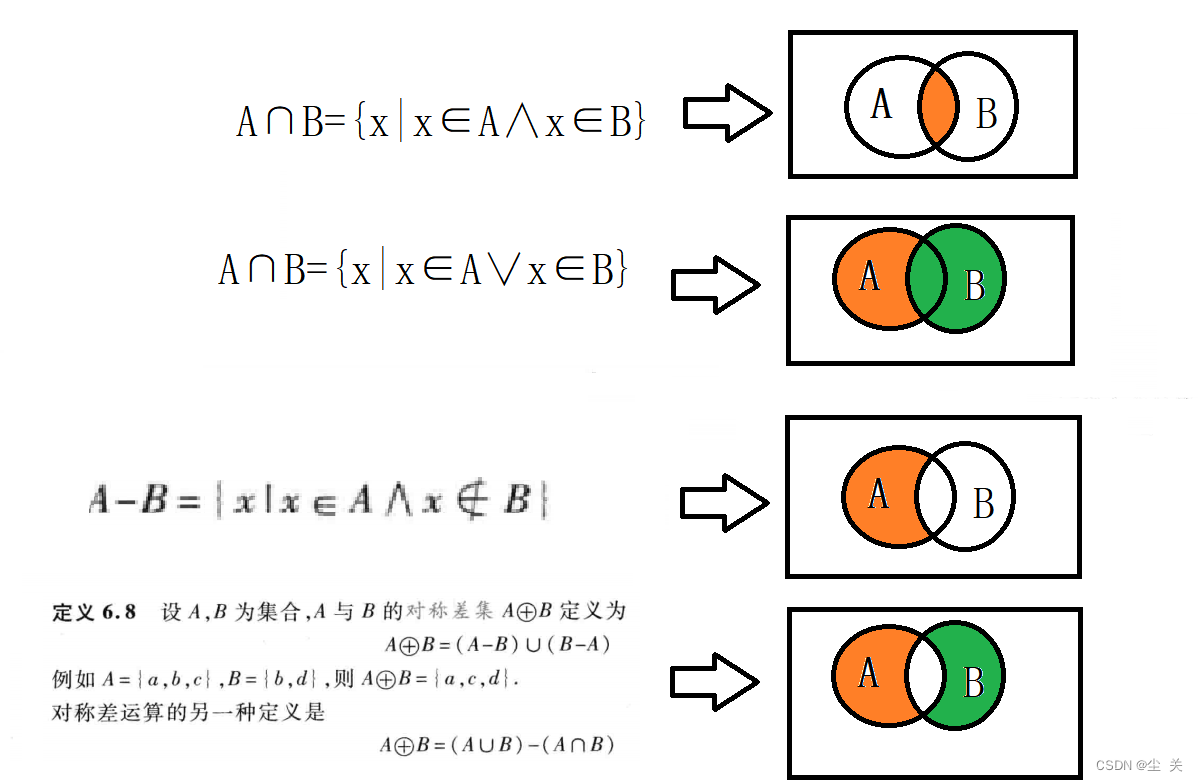
3、集合恒等式(幂等律、交换律、结合律、分配律、吸收律、矛盾律、德摩根律等)及应用

本章重点内容:集合的概念、集合的运算性质、集合恒等式的证明。
[复习要求]
三、 二元关系
[复习要求]
1、了解序偶与笛卡尔积的概念,掌握笛卡尔积的运算。
2、理解关系的概念:二元关系、空关系、全域关系、恒等关系;掌握关系的集合表示、关系矩阵和关系图、关系的运算。】



3、掌握求复合关系与逆关系的方法。
4、理解关系的性质(自反性、反自反性、对称性、反对称性、传递性),掌握其判别方法(定义、图)。
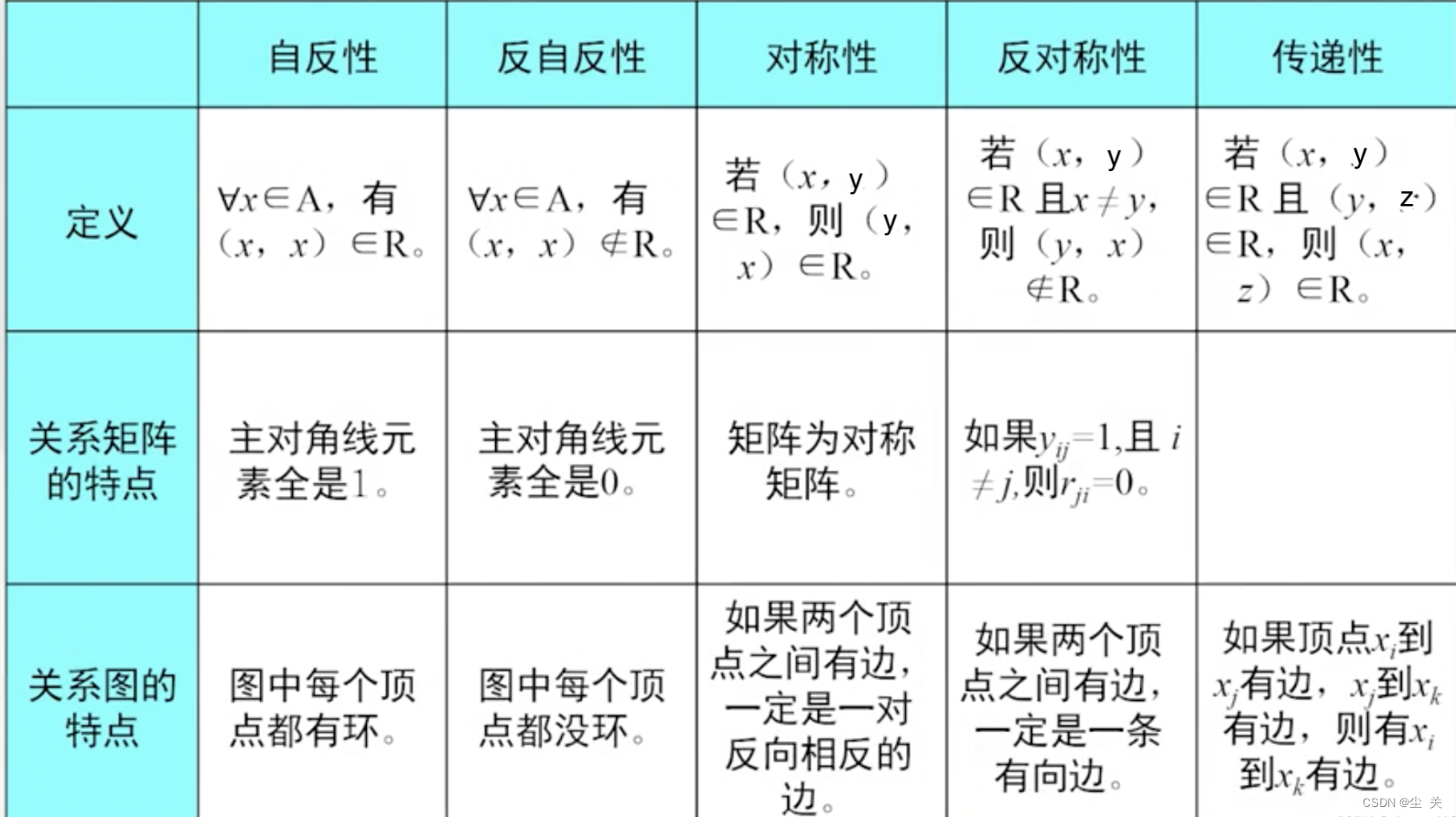
自反性:全部顶点均有环;反自反性:全部顶点均无环;对称性:有边均双边(无单边,顶点有无环不影响) ;反对称性:有边均单边(顶点有无环不影响)(无平行边)
传递性:a到b有边,b到c有边,则a到c也有边,否则不然。
5、掌握求关系的闭包 (自反闭包、对称闭包、传递闭包)的方法。

换言之:r=加自环 s=单边变双边 t:努力变传递
6.理解等价关系和划分、掌握等价类和划分的求法
7、理解偏序关系的概念,掌握画哈斯图的方法,极大/小元、最大/小元的求法。
相关概念:



哈斯图的方法:

如图7.7:5,9,6,8,7均是极大元,1是极小元,无最大元,最小元为1;右边: {a,b,c}是极大元,∅是极小元,最大元是 {a,b,c},最小元为∅
四、函数
[复习知识点]
- 理解函数概念:函数、函数相等、A到B的函数。

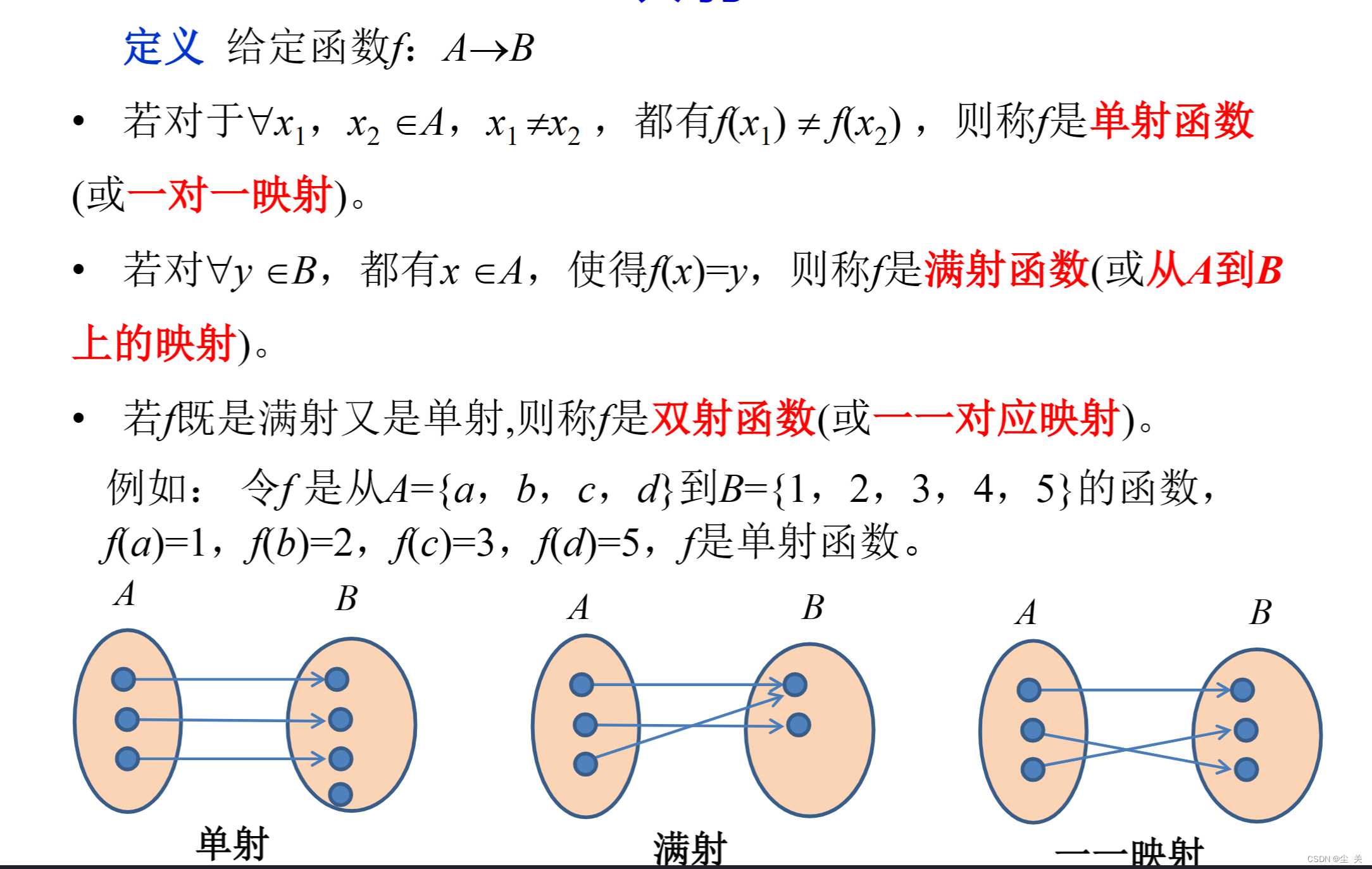
2、理解单射、满射、双射等概念,掌握其判别方法。
单射:不同的x所对应的y不同。
满射:y的值域全用到了。
双射:单+满
3、函数的复合与反函数
函数复合及相关联习

 反函数:
反函数:
本章重点内容:函数的定义及判别方法、函数的三大性质、函数的复合与反函数。
[复习要求]
- 掌握函数及从A到B的函数的判别方法。
函数:
从A到B的函数:

2、理解函数的像与原像。
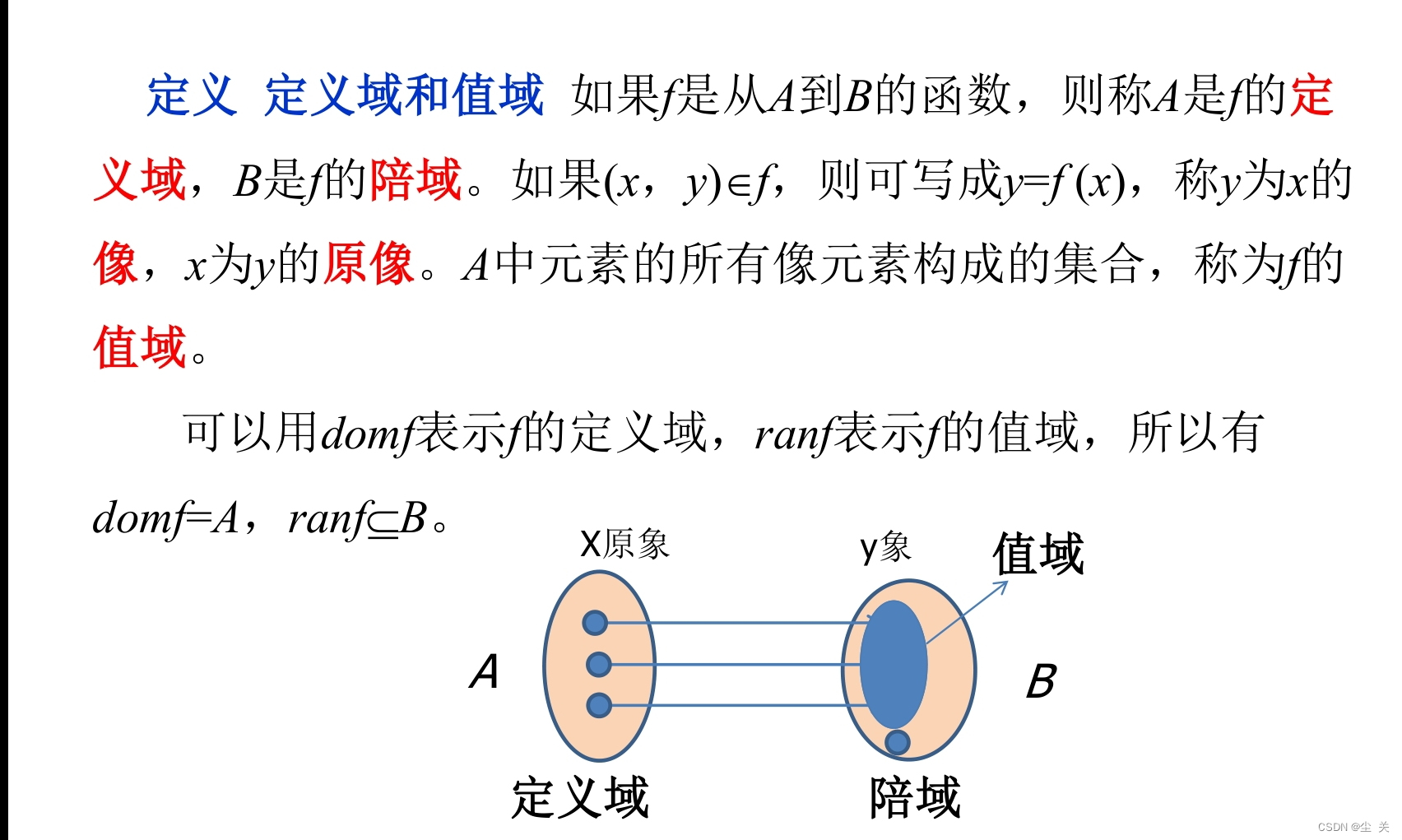
3.掌握函数的单射、满射、双射的判别方法。
4、掌握求函数的复合与反函数的方法。

五、 图论
[复习知识点]
1、 图的基本概念:无向图与有向图(根据联结的边是否有方向)、顶点与边的关联关系、顶点(边)与顶点(边)之间邻接关系、简单图与多重图、顶点度数(度)与握手定理、图的同构、完全图、子(补)图。
度:
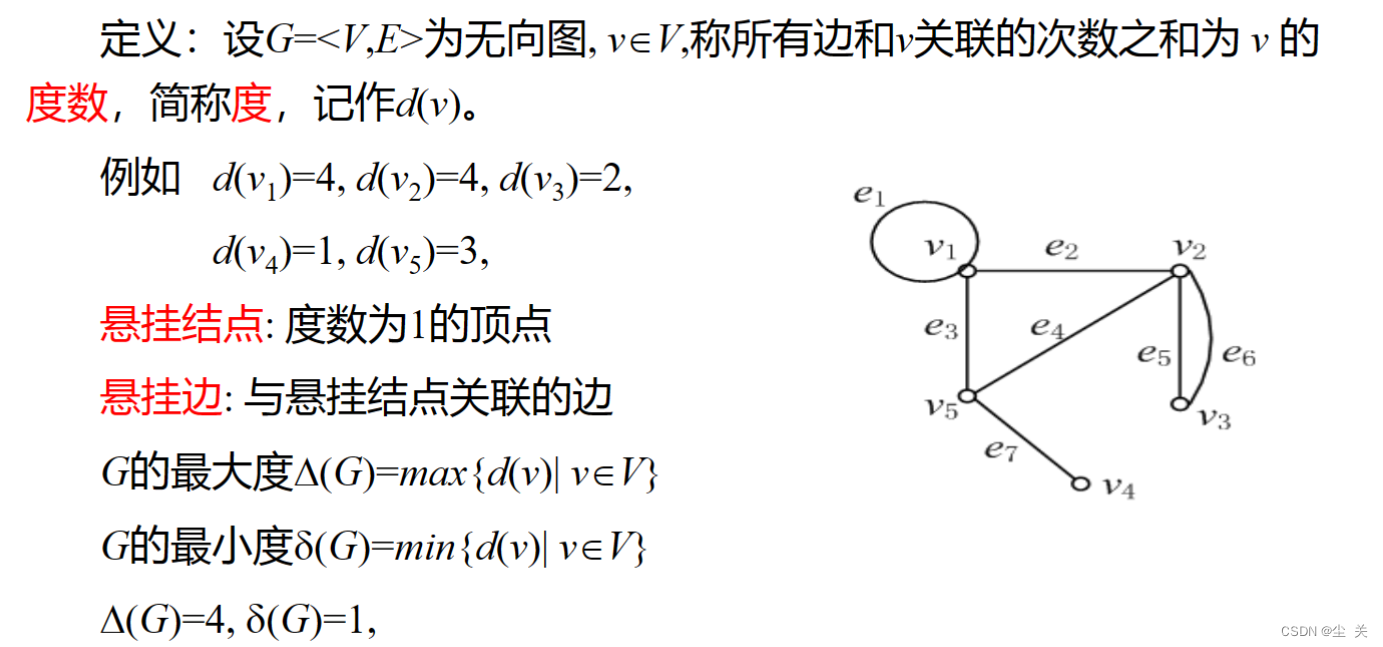

握手定理:
简单图与多重图:
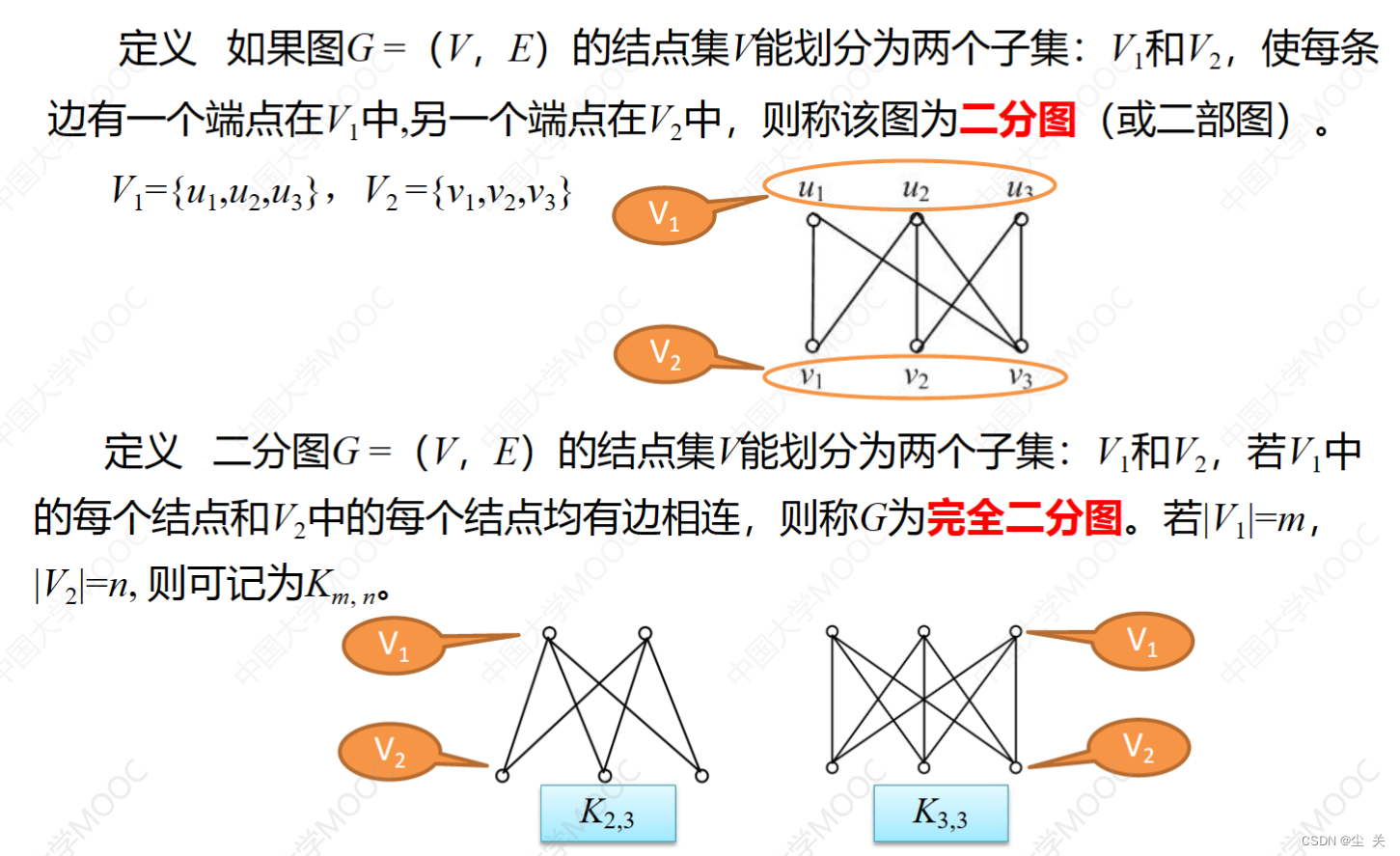
2、 通路与回路、简单通(回)路与初级通(回)路;连通图与非连通图、连通分支、点割集、边割集、点(边)连通度;强连通图、单向连通图与弱连通图;二部图。
3、 图的矩阵表示:关联矩阵、邻接矩阵、可达矩阵。
4、 欧拉通(回)路、(半)欧拉图;哈密尔顿通(回)路、(半)哈密尔顿图;

5、 无向树、生成树、带权树、最小生成树。
6、 有向树、树根、有序树、二叉树、最优二叉树、前缀码、最佳前缀码、霍夫曼(Huffman)算法、二叉树的周游及应用。
本章重点内容: 握手定理、点(边)割集、通路与回路、特殊图(欧拉图与哈密顿图、无(有)向树)、最优二叉树、最佳前缀码、霍夫曼(Huffman)算法。
[复习要求]
1、理解图的有关概念:图、完全图、简单图、子图、母图、生成子图等。
2、深刻理解握手定理及其推论的内容,并能熟练地应用它们。
3、能判断两个图是否同构。
4、理解连通度、点割集、边割集、割边和割点。
5、能判断图是否为强连通图、单向连通图与弱连通图。
6、理解图的矩阵表示(关联矩阵、相邻矩阵)和性质以及熟练掌握用有向图的邻接矩阵及各次幂求图中通路与回路数的方法。
4、理解欧拉图、哈密顿图的定义及判别定理。在无向图中找出一条欧拉通路或欧拉回路、哈密顿通路或哈密顿回路。
5、理解无向树的定义,熟练掌握无向树的主要性质,并能灵活应用它们。
6、理解生成树的有关概念与性质。
7、理解有向树、根树、二叉树和前缀码的有关概念;掌握用霍夫曼(Huffman)算法求带权图的最优二分树,掌握求最佳前缀码方法,二叉树的中序和前序行遍法。