九易建网站的建站模板如何提高网站排名
写在之前:近期打了个比赛,备受打击,入手了vip账号进修,加油!
文章目录
- ctfshow-web1
- 查看源代码
- ctfshow-web2
- burp抓包
- ctfshow-web3
- burp抓包
- ctfshow-web4
- 访问robots.txt
- ctfshow-web5
- dirscarch扫描
- PHPS文件泄露
- ctfshow-web6
- dirscarch扫描
- ctfshow-web7
- dirscarch扫描
- ctfshow-web8
- dirscarch扫描
- ctfshow-web9
- ctfshow-web10
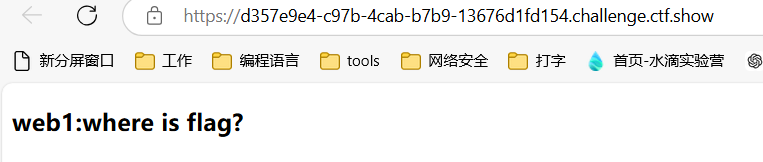
ctfshow-web1
打开网页后如图
查看源代码
右键查看源代码
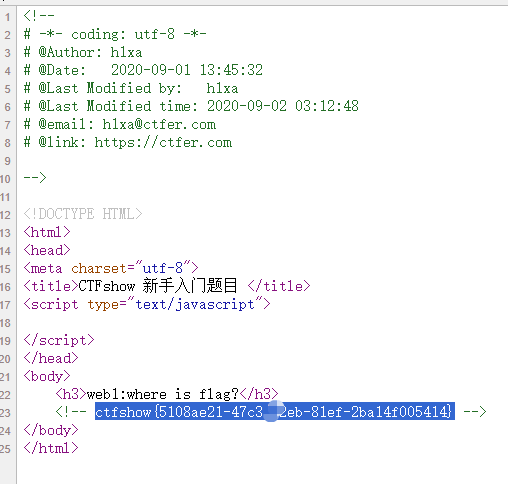
发现flag。
ctfshow-web2
开始给出提示
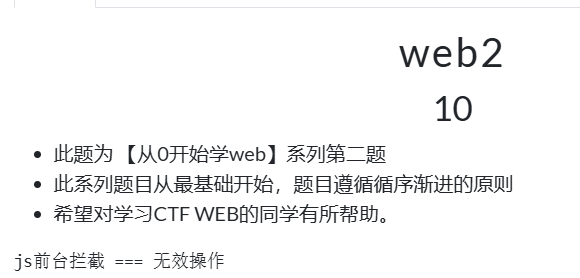
打开网页后发现无法查看源代码。
burp抓包
运用burp抓包在repeat中获取flag。
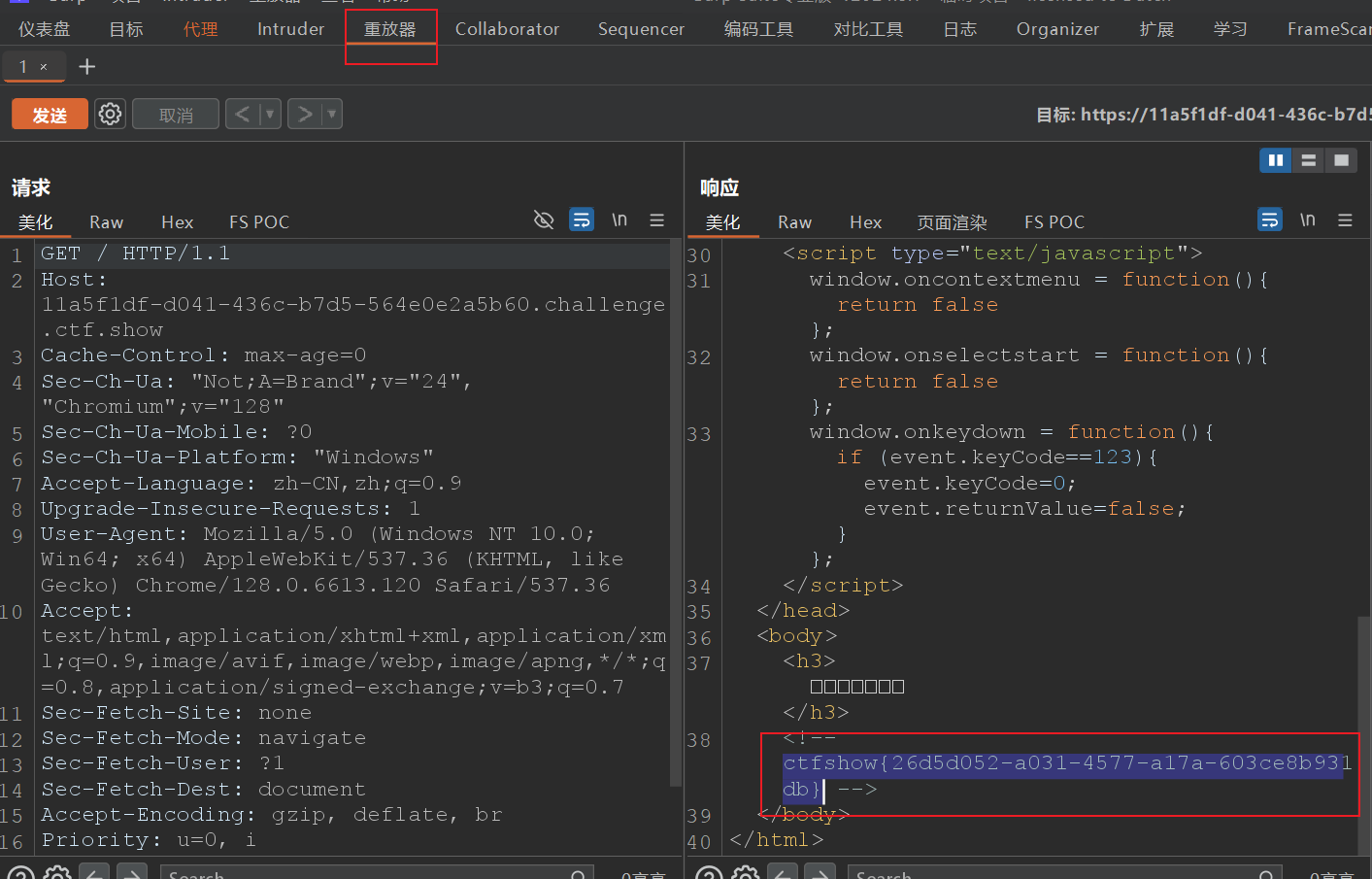
除此之外好像还能修改前端代码,对js不熟悉,先不搞了。
ctfshow-web3
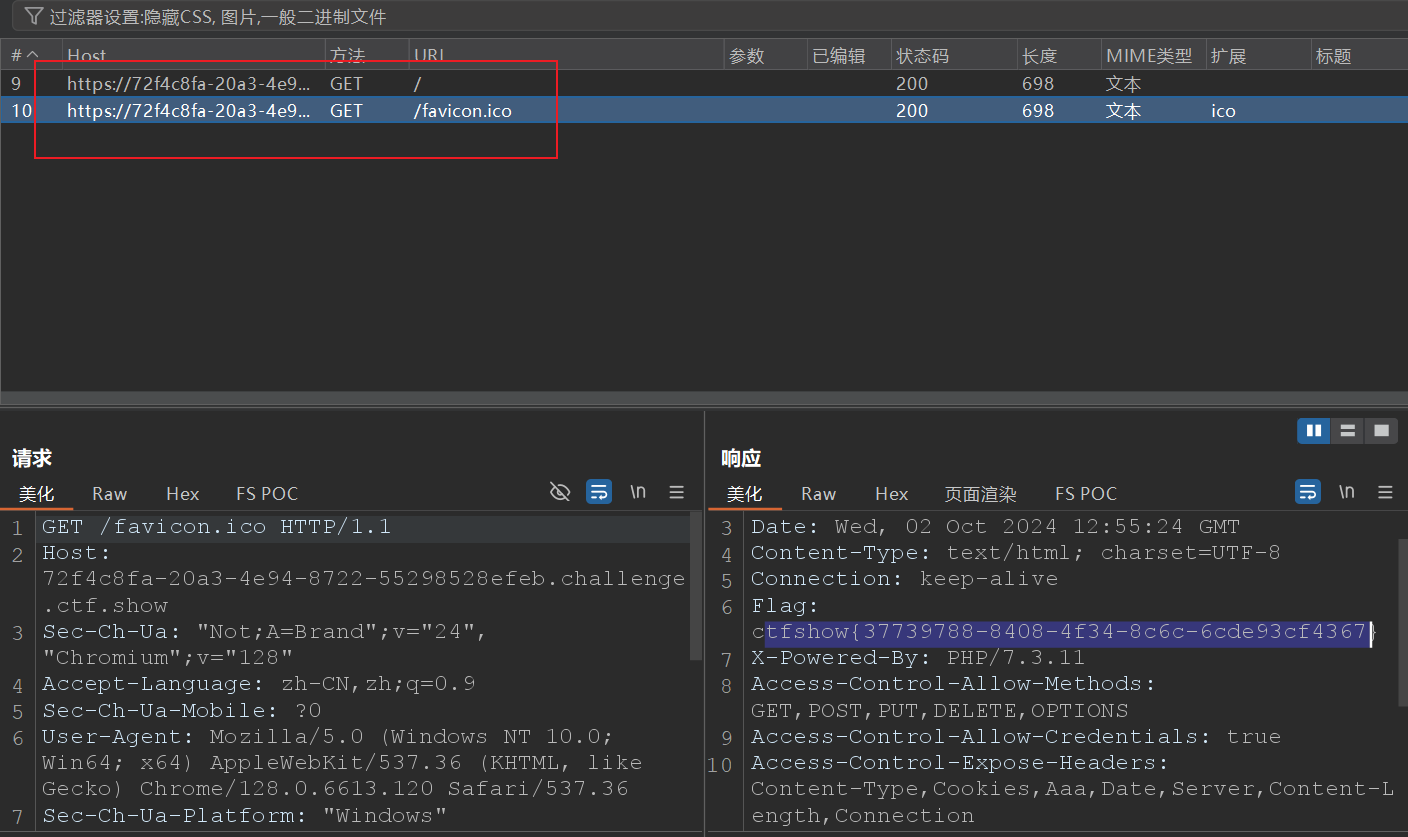
burp抓包
抓包过程中,发现有发送的另外的数据包。表头中获取flag
ctfshow-web4