企业网站需要备案吗阿里云网站备案拍照
目录
- 一、基本内置类型
- 1. 类型的作用
- 2. 分类
- 3. 整型
- 3.1 内存描述及查询
- 3.2 布尔类型 —— bool
- 3.3 字符类型 —— char
- 3.4 其他整型
- 4. 有符号类型和无符号类型
- 5. 浮点型
- 6. 如何选择类型
- 7. 类型转换
- 7.1 自动类型转换
- 7.2 强制类型转换
- 7.3 类型转换总结
- 8. 类型溢出
- 8.1 注意事项
- 9. 字面值常量
- 9.1 整形字面值
- 9.2 浮点型字面值
- 9.3 字符和字符串字面值
- 9.3.1 转义字符
- 二、变量
- 1. 变量的定义和初始化
- 2. 变量若未初始化的结果
- 3. 变量声明和定义的区别
- 4. 变量名的命名规则
- 5. 变量名的作用域
一、基本内置类型
1. 类型的作用
数据类型是程序的基础,它决定了该数据的意义和能对其进行的操作。如:
a = a + b;
若 a 和 b 均为 int 类型,则执行的是 int 类型的加法,若为 double 类型则执行的是 double 类型的加法,若为自定义类型则执行自定义类型的加法。
2. 分类
C++中基本数据类型分为算数类型和空类型(void)。算数类型包含布尔类型、字符类型、整型和浮点型,由于布尔和字符类型也算整型,所以算数类型实际上就是整型和浮点型。空类型不对应具体类型,只在一些特殊场合使用,最常见的是:当函数不返回任何值时,使用空类型(void)作为返回类型。
3. 整型
一般来说按照所占位数的大小,可以按如下顺序划分整形:bool(布尔)、char(字符)、short(短整型)、int(整型)、long(长整型)和 long long。
3.1 内存描述及查询
在计算机中,数据都是用一个个比特位来表示的,该值只有 0 和 1 两种。而一般把 8 个比特位称为一个字节(byte),即 1 字节 = 8 比特。一个字节可以表示 2 的8次方种变化,如果是无符号整数即 0-255 。而算数类型的尺寸(也就是该类型所占比特位数)在不同实现上面是有所差别的。我们可以通过对类型使用 sizeof 运算符来查看该类型所占内存大小(单位字节)。如:

可以看到 int 类型占 4 个字节,也就是 32 位。
也可以通过包含头文件 climits ,通过符号常量来查询具体的值。如:
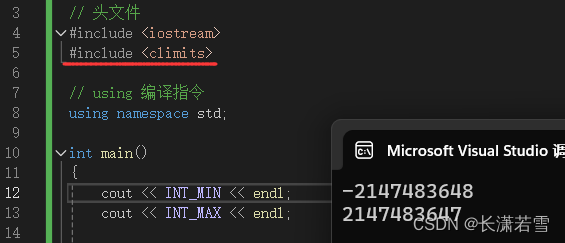
3.2 布尔类型 —— bool
布尔类型的值只有两种,真(true)和假(false)。true 和 false 为 bool 类型的字面值常量,分别表示真和假。布尔型一般用在条件判断语句中,判断该条件是否成立。虽然只用一个比特为就可以表示该类型,但是一般都以一个字节进行存储。如果使用 bool 类型进行算数运算,则真(true)为 1,假(false)为 0。而如果在需要使用 bool 型的地方使用整型或者浮点型,则 0 为假,非 0 为真。
3.3 字符类型 —— char
C++提供了多种字符类型,其中多数支持国际化。基本字符类型是 char,一个 char 应确保可以存放机器基本字符集中的任意字符对应的数字值。char 的大小和一个机器字节一样,一般为 8 位。而在计算机中,实际上是使用整数来存储 char 类型,如 ASCII码表,通过给每个字符对应一个数字,当需要使用字符时,就通过存储的数值找到对应的字符。如:在ASCII码中,字符’A’对应整数 65,字符’a’对应整数 97。
3.4 其他整型
除了字符和布尔类型,其他整型用于表示不同范围的整数。C++规定 int 至少和 short 一样大,long 至少和 int 一样大,long long 至少和 long 一样大。其中,long long 类型是 C++11 中新定义的。
4. 有符号类型和无符号类型
除去 bool 型之外,其他类型可以分为有符号和无符号类型两种。有符号类型(signed)就是既可以表示正数又可以表示负数,而无符号类型(unsigned)就是只能表示 0 和正数。一般情况下 short、int、long 和 long long都是有符号类型。无符号类型只需要在其前面加上 unsigned 修饰即可,如 unsigned int 。
与其他整型不同,char 被分为了三种:char、signed char 和 unsigned char。但是实际上只有两种,char 类型会被编译器转换为有符号或者无符号的一种,具体是哪一种由具体实现决定。
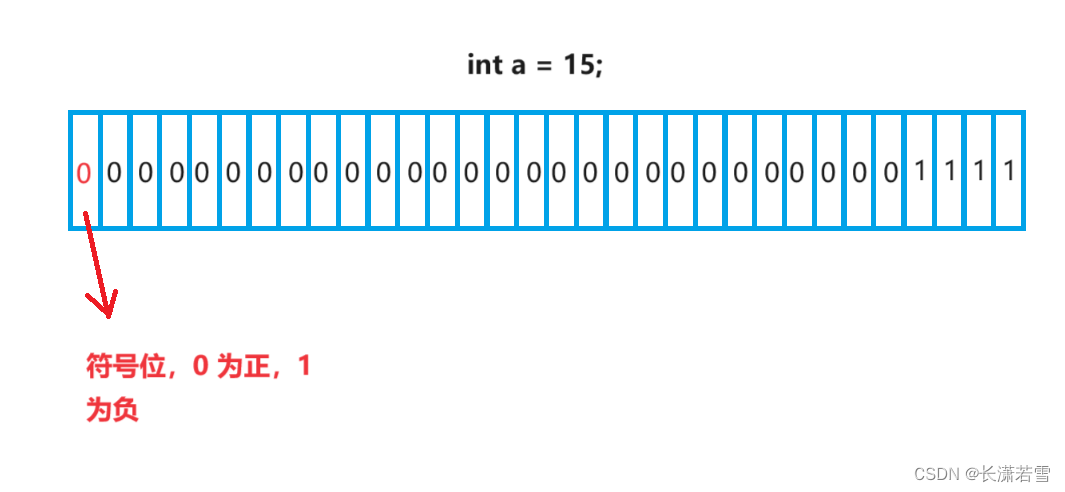
C++并没有规定带符号类型应如何表示,但是约定了表示范围内的正值和负值应平衡。所以有符号类型的最高位表示正负,最高位为 1 为负,最高位为 0 为正。如:int a = 15;
5. 浮点型
浮点型按照所占位数由低到高为:float、double 和 long double。浮点型与整型的差别在于,浮点型可以表示整数。但是浮点型有精度范围,超出该范围其值不精准。所以,上述三种类型的差别在于所表示的值的范围不同和精度不同。浮点型全是有符号类型。
6. 如何选择类型
a. 当确定数值不可能为负数时,选择无符号类型。
b. 一般选择 int 进行算数运算。short 一般显得太小,而 long 一般和 int 一样大。如果数值超出 int 一般选择 long long 类型。
c. 在算数表达式中尽量不要使用 char 或 bool,只在使用字符或者布尔值时使用它们。因为 char 类型在一些实现上面是有符号的,在另一些实现上面是无符号的。如果真的需要使用,请指明其类型是 signed char 或者 unsigned char 。
d. 执行浮点数运算选用 double,因为 float 通常精度不够,而两者计算代价相差无几。long double 提供的精度在一般情况下是没有必要的,而且其运行时消耗更大。
7. 类型转换
类型转换分为自动类型转换和强制类型转换。
7.1 自动类型转换
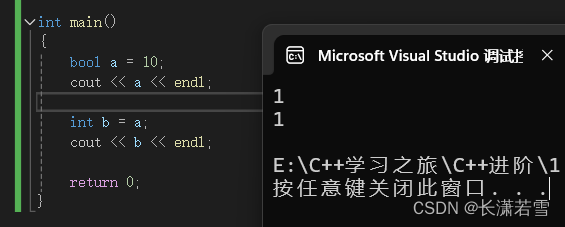
bool 值进行算数运算时,会自动类型转换为 int 类型,真(true)为 1 ,假(false)为 0 。而其他类型赋值给 bool 变量,0 为假(false),非 0 为真(true)。如下代码:
char 类型进行算数运算时,也会自动类型转换为 int 类型。而其他整型赋值给 char 类型时,只会存储该类型的后 8 位。如下代码:
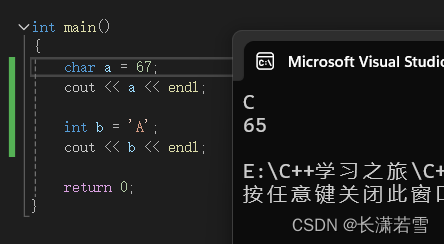
再次证明 char 类型是用整数进行存储的,当需要字符时,编译器就找到整数 67 对应的字符 ‘C’,然后输出。而当需要整数时,编译器找到字符 ‘A’ 对应的整数 65 存入变量 b 中,然后输出。
浮点数赋值给整型变量时,会发生截断,丢弃小数部分。而整数赋值给浮点型变量时,小数部分为0。如下代码:
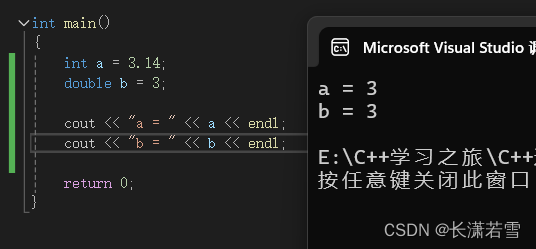
这里时编译器做了处理,实际上 b = 3.0 。
7.2 强制类型转换
强制类型转换有两种方式,一种时从 C 语言继承下来的 C 风格,另一种是 C++ 新增的 C++风格。
如下代码:
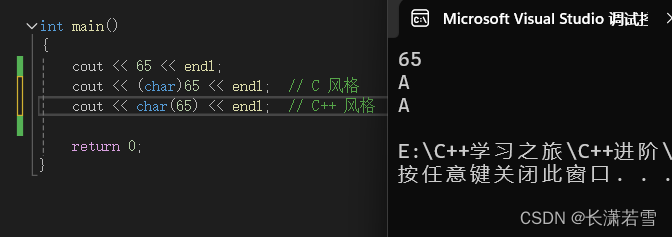
本来三行代码都应该和第一行一样输出数字 65。但是第二行和第三行进行了强制类型转换,使原本 int 类型的 65,变成了 char 类型的 65 。编译器就会按照 char 类型进行输出,找到整数 65 对应的字符 ‘A’,输出。
C 风格强制类型转换格式:(类型)变量名
C++ 风格强制类型转换格式:类型(变量名)
C++ 风格的想法是想像使用函数一样使用使用强制类型转换。这两种就目前来说已经够用,但是一般在编写程序的过程中很少用到强制类型转换。
7.3 类型转换总结
初始化和赋值: 将值赋给取值范围更大的类型时,通常不会导致问题;将值赋给取值范围更小的类型时,可能会导致精度降低或数据丢失;将0赋给bool变量时,将被转换为false,非零值转换为true。
表达式中的转换:
整型提升: bool、char、unsigned char、signed char 和 short 值在表达式中会被转换为int。
自动类型转换: 当运算涉及两种类型时,较小的类型将被转换为较大的类型。编译器通过校验表来确定在表达式中执行的转换。
强制类型转换: 可以使用强制类型转换运算符显式地进行类型转换。
8. 类型溢出
如果赋值超出了该类型的最大值或者低于该类型的最小值,就会从另一头开始,如:unsigned char 类型的最大值是 255,最小值是 0,分别使用256 和 -1 给其赋值。代码和结果如下:
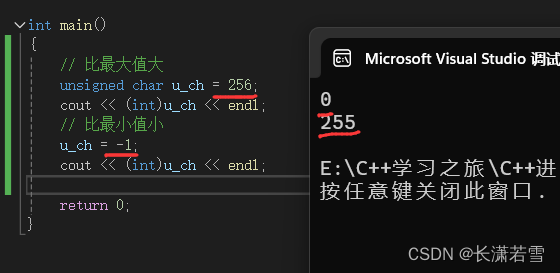
可以看出,如果超出最大值则从最小值开始,如果超出最小值就从最大值开始。但是C++只保证了无符号类型的溢出是这样处理的,而有符号类型则不一定,其造成的结果是未定义的,此时,程序可能继续工作、可能崩溃,也可能产生垃圾数据。
这是我用的计算无符号类型溢出的方法: 如果超过最大值,就用该值先减去 1,然后一直减该无符号类型的最大值,直到结果在该无符号类型范围之内。如果低于最小值,则先加 1,然后一直加该无符号类型的最大值,直到结果在该无符号类型的范围之内。这个 1 是必须加减的,最大值至少加减 1 次。如:
256 - 1 - 255 = 0;
-1 + 1 + 255 = 255;
8.1 注意事项
不要使用无符号类型进行涉及负数的算数运算。因为同类型的有符号类型遇到同类型的无符号类型,在计算过程中会转换为无符号类型。结果也是无符号类型,但是无符号类型不存在负数,就会像上面溢出这样处理。如下代码和结果:
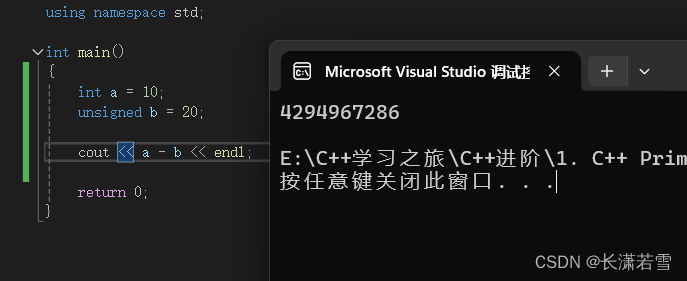
此处的计算结果本来应该是 -10,但是 int 类型的变量 a 在和 unsigned 类型的变量 b 进行运算时转换为了 unsigned 类型,-10 便成为了上述的溢出行为。
不要在循环变量中使用无符号类型的循环变量,如下代码:
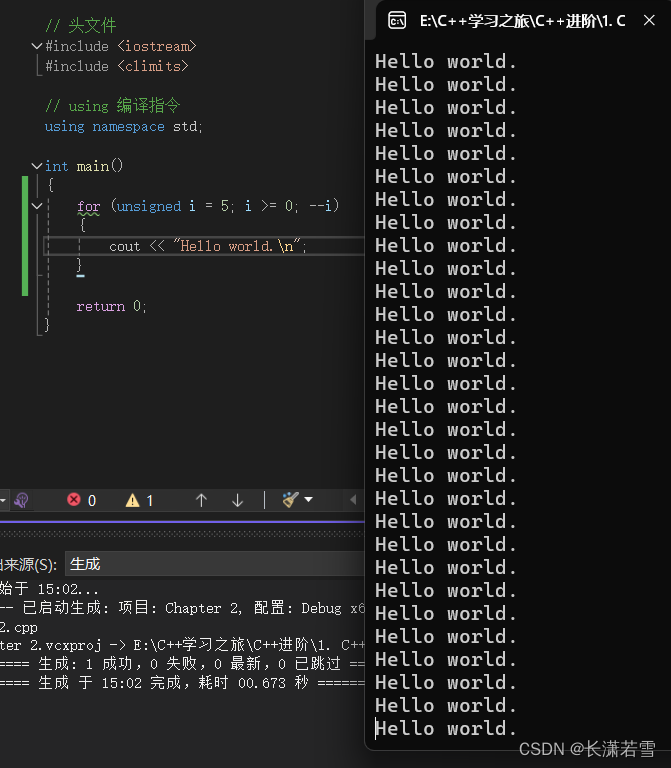
可以发现已经进入死循环了,因为当 i = 0 时,执行 --i 操作,使 i 成为了 unsigned 类型的最大值。造成了无符号类型的溢出行为。
9. 字面值常量
在C++中字面值存储在内存中的常量区。常量区是程序运行时的一个固定区域,用于存储不可修改的常量数据。
9.1 整形字面值
如:1,24,99等都是整形字面值。整形字面值还可以使用八进制和十六进制,八进制以 0 开头,而十六进制以 0x 或者 0X 开头。如下表示的都是整数 20:
20 —— 十进制
024 —— 八进制
0x14 —— 十六进制
在能容纳字面值数值的前提下,十进制字面值会从以下类型中选择尺寸最小的那个:int、long 和 long long 。而八进制和十六进制从 int 、unsigned int、long 、unsigned long、long long 和 unsigned long long 中选择尺寸最小的那个。
可以通过添加后缀来使字面值成为我们想要的类型,如:
32U / 32u —— unsigned int 类型的字面值 32
32l / 32L —— long 类型的字面值 32
32ul / 32LU —— unsigned long 类型的字面值 32
大小写可以互换,u 和 l 前后顺序可以颠倒。一般使用大写 L ,小写 l 容易 和数字 1 混淆。
9.2 浮点型字面值
浮点型字面值有两种表示方法:小数表示法和科学计数法。如:3.14,1.99,3.4E2 等均为浮点型字面值。而科学计数法中 E2 代表前面的数值乘以 10 的 2 次方,即 3.4 * 100 = 340.0 。而 -1.2E-1 中,最前面的符号表示整个浮点数是一个负数,而 E 后面的符号表示乘以 10 的 -1 次方。即 -1.2 * 0.1 = -0.12 。
9.3 字符和字符串字面值
用双引号括起来的是字符串字面值,而用单引号括起来的是字符字面值。如:‘a’,‘G’,‘1’ 等均为字符字面值。而 “abc”,“hello”,“123” 等均为字符串字面值。
字符串字面值实际上是由一组字符常量组成的数组(array)。编译器通过在其末尾添加空字符(‘\0’)来标识,所以实际上字符串字面值的实际长度比它的内容多 1 。所需要的存储空间也多了一个字节。如:字符’A’表示的就是单独的字符 A,而字符串"A"表示一个字符数组,除了字符’A’外还有一个空字符(‘\0’)。
一般来说如果两个字符串之间没有其他输出,那么第二个字符串会紧接在第一个字符串末尾。如下代码:
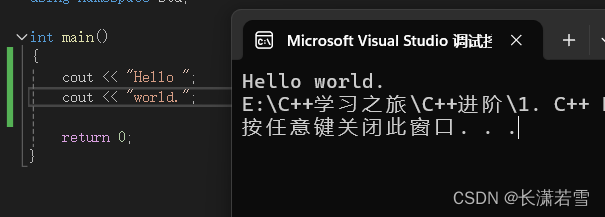
若两个字符串紧邻且中间只有空格、换行符和制表符,那么这实际上是一个字符串。如果字符串太长一行不好写,就可以分行编写,如下:

也可以通过添加前缀和后缀来指定字符字面值和字符串字面值的类型,但是我从来没用过。有兴趣的可以去了解一下。
9.3.1 转义字符
在C++中,有两类字符程序员是不能直接使用的:一类是不可打印字符,如退格或其他控制字符,因为它们看不见;另一类是在C++中有特殊含义的字符(单引号、双引号、反斜线)。所以需要使用转义字符来使用它们,转义字符均以反斜线开头(\)。如下是一些重要且经常使用的转义字符:
换行符 —— \n
横向制表符 —— \t
退格符 —— \b
双引号 —— "
单引号 —— ’
反斜线 —— \
空字符 —— \0
如:cout << “\n”; 表示换行,光标移动到下一行开头。其作用和 iostream 库中的操纵符 endl 一致,cout << endl; 。当输出字符串时需要换行使用前者比较方便,当输出数值等需要换行使用后者比较方便。
也可以使用八进制或者十六进制输出字符。八进制反斜杠后面紧跟 1-3 个八进制数,而十六进制反斜杠后面跟 1-多个十六进制数。
转以字符的使用的普通字符一样,并没有什么特别的地方,如:
cout << “Hello \x4do\115!\n”;
输出 Hi MOM! ,然后换行。
注意: 如果反斜杠后面跟着的八进制数超过 3 个,则只取前三个。如:“\1234” 表示三个字符,即八进制 123 对应的字符和字符 ‘4’,还有空字符。而十六进制 \x 后面跟着的所有数字都算,如:“\x1234” 表示两个字符,即十六进制 1234 对应的字符和空字符。但是,一般 char 只有 8 个字节,所以使用的时候需要小心。
9.4 布尔字面值和指针字面值
布尔字面值只有两个:true 和 false ,分别表示真和假。
指针字面值只有一个:nullptr,表示空指针。
二、变量
变量的实质是一块被标识符标记的内存空间。其类型决定了这块内存空间的大小和编译器如何理解这块空间。对C++程序员来说,变量和对象一般没有区别,可以互换使用,对象一般用来称呼类类型的变量。
1. 变量的定义和初始化
变量的定义形式:首先是类型说明符,其后紧跟由一个或多个变量名组成的列表,其中变量名以逗号分隔,最后以分号结束。列表中每个变量名的类型由类型说明符指定,定义时还可以为一个或多个变量赋初值,也叫初始化。如:
int a, b, c; —— 定义了三个 int 变量
double a, b, c = 0; —— 定义了三个 double 变量,并给最后一个变量 c 初始化。
上面 int 和 double 就是类型说明符,而 a,b 和 c 是变量名。
在创建对象的同时并给它赋一个初值,就叫这个对象被初始化了。用于初始化的值可以是任意复杂的表达式。当一次性定义多个变量时,先定义并初始化的变量可以用来初始化后定义的对象。如:int a = 1, b = a*2;
注意: 初始化不是赋值。初始化是在创建对象的同时赋予其一个初值。而赋值是用新的值替换当前值。
C++定义了如下几种初始化方式:
int a = 0;
int a = { 0 };
int a {0};
int a(0);
用花括号来初始化变量是C++11 新标准的一部分,这种初始化的形式被称为列表初始化。无论是初始化对象还是某些时候为对象赋新值,都可以使用花括号。
对于内置类型,列表初始化不允许出现初始值缺失的风险。如:用 double 值来初始化 int 变量,会发生截断,丢弃小数部分。若出现此类情况,编译器会报错。如下代码和结果:
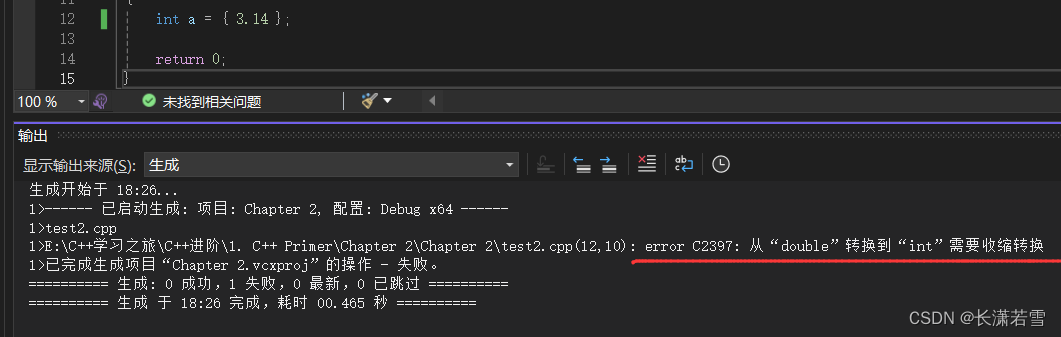
2. 变量若未初始化的结果
定义在函数之内的变量叫做局部变量,定义在函数之外的变量叫全局变量。若局部变量未初始化,则其里面存储的是之前这块空间上存储的值,也就是垃圾值。若直接使用未初始化的局部变量,会产生难以想象的错误,有的编译器会直接报错。而全局变量和静态变量若不初始化,编译器会自动把其值设置为 0 。静态变量就是生命周期为整个程序的变量。局部变量则是程序执行到其声明语句时被创建,出了其作用域时被销毁。而类类型的对象,若显式初始化,则其会自动调用其默认构造函数隐式初始化。
所以,局部变量最好在创建的同时初始化。
3. 变量声明和定义的区别
简单点来说,变量的声明不开辟空间,而变量的定义开辟空间。在中后期学习C++的时候,基本上都是分多个文件进行编程。有时一个文件需要使用另一个文件里面的变量,这个时候就只需要声明该变量,而不需要定义。意思就是告诉编译器,有这个变量,但是这个变量的定义不在该文件,需要去别的文件找。
只声明而不定义变量就是在原来定义变量的前面加上关键字 extren ,但是不能进行初始化。如果进行初始化就抵消了 extren 关键字的作用,还是定义变量。我们最开始定义变量的形式既是声明也是定义,如:int a; 。
必须在使用变量之前声明变量,因为可能存在拼写错误,这样没有声明的变量就不能使用,就可以检查出来这种低级错误。C++是一种静态类型语言,在编译阶段进行类型检查。其中检查类型的过程称为类型检查。如下代码展示了拼写错误:
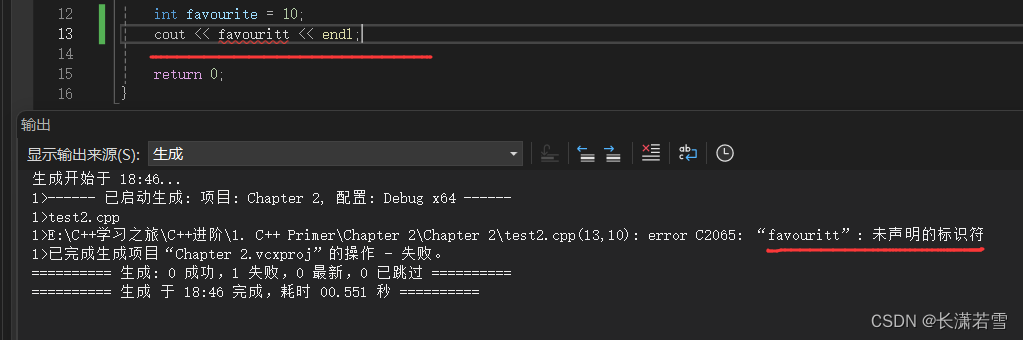
这里单词 favorite 就拼写错了一个字母,然后被编译器检查出来了,因为这个拼写错误的标识符未声明,编译器不认识。
4. 变量名的命名规则
变量名实际上就是标识符,变量名、函数名、结构名和类名等使用的都是标识符。标识符由字母、数字和下划线组成,且必须以字母或者下划线开头。标识符对长度一般没有限制,但是区分大小写。如下面定义了四个不同的 int 变量:
int ab = 1, Ab = 1, aB = 1, AB = 1;
但是标识符不能和C++关键字相同。同时C++也保留了一些名称给语言本身使用。用户自定义的标识符不能连续出现两个下划线,也不能以下划线紧连着大写字母开头。此外,定义在函数体外的标识符不能以下划线开头。
变量名的命名规范:
C++没有规定变量名的命名标准,但是下面是一些约定俗成的命名规范,可以提高代码的可读性。
(1)标识符要能体现实际含义
(2)变量名一般用小写字母,如:year
(3)用户自定义的类名一般以大写字母开头,如:Person
(4)如果标识符由多个单词组成,则单词之前应该由明显区分,用下划线分开或者使用大写字母。如:student_number 或者 studentNumber,不要使用 studentnumber 。
5. 变量名的作用域
作用域是程序的一部分,在其中名字有其特定的含义。C++中在多数作用域,以花括号分隔。
在函数内定义的变量,其作用域一般都是从声明语句到其所在最近花括号的结尾。注意: 在同一作用域内不能创建两个变量名相同的变量,否则编译器会报错。如下代码:
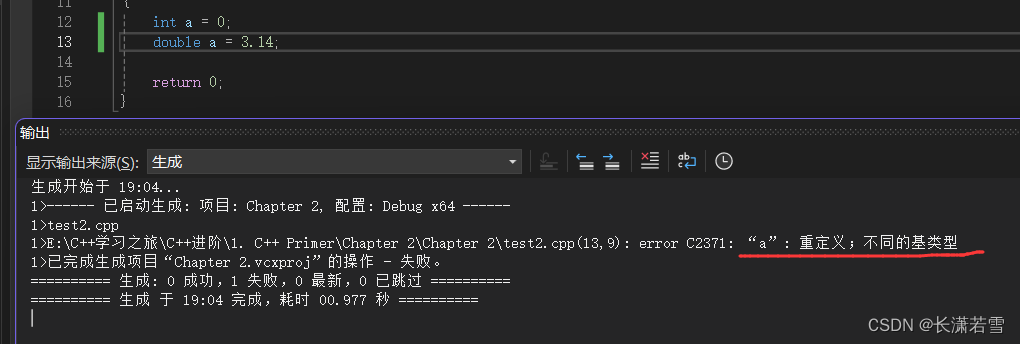
但是,不同作用域可以创建同名变量。当前作用域变量会隐藏其他同名变量。
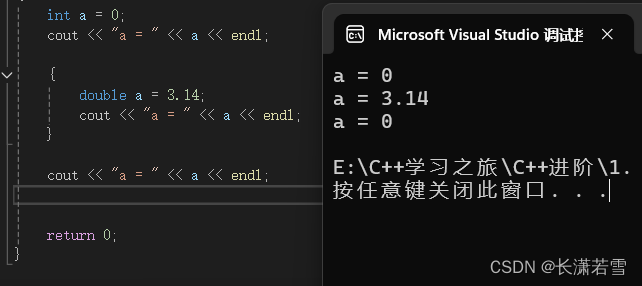
上面这种作用域中包含作用域称为嵌套作用域。外面的叫外层作用域,里面的叫内层作用域,允许在内层作用域中重新定义外层作用域中已有的名称,当执行到内层作用域时,内层作用域中的同名变量会隐藏外层作用域中的同名变量。当执行第一条输出语句时,内层中的 a 还未创建,所以输出外层中的 a。而执行第二条输出语句时,内层的 a 隐藏了外层的 a ,所以输出内层的 a 。而执行第三条语句时,已经不在第二个 a 的作用域中,且其已经被销毁,所以输出第一个 a 。
全局变量的作用域为整个程序,从声明的位置到程序结束。如果在函数中声明了与全局变量同名的变量,那么函数中的局部变量会隐藏全局变量。而通过使用作用域操作符(::)可以显式地访问全局变量。如下代码:
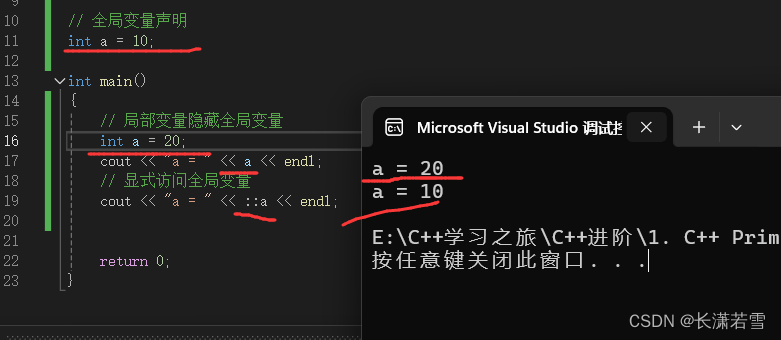
第一条输出语句,局部变量隐藏了全局变量。而第二条语句通过作用域操作符(::)显式访问全局变量。