市住房城乡建设网站建网站简易软件
简介
SSH 是一种安全网络协议,旨在让客户端和服务器之间进行安全的数据传输。SSH 的核心思想是利用公钥加密技术和共享密钥加密技术相结合的方式,使客户端和服务器之间建立起安全的连接。 当客户端发起连接请求时,服务器会对客户端进行身份验证,以确保它是合法的用户。为了达到这一目的,服务器会把自己的公钥发送给客户端,客户端使用这个公钥对一组随机数据进行加密,并返回给服务器。服务器收到后用自己的私钥解密,从而验证客户端的身份。 一旦客户端的身份得到确认,双方就开始协商共享会话密钥,即一个临时密钥,用于加密随后传输的所有数据。双方各自生成一段密钥,并交换,最终形成一致的会话密钥。这时,所有通过 SSH 发送的数据都会被用这个共享会话密钥进行加密,只有客户端和服务器才知道这个密钥,因此即使数据在传输过程中被截获,也不能被别人解读。 另外,为了防止中间人攻击,SSH 还会在一段时间后自动更新会话密钥。 以上就是 SSH 的基本运行原理,它可以通过这样的加密过程确保客户端和服务器之间数据的安全传输。
作用:当需要同时管理多个集群节点的时候,通过一个客户端就可以进行访问,相对来说就比较方便。
windows必备服务
使用ssh -V 查看电脑是否安装了SSH ,一般电脑都会自带ssh服务

自行安装,非常简单不再累述
然后查看SSH的运行 ,使用Get-Service -Name ssh*

生成密钥
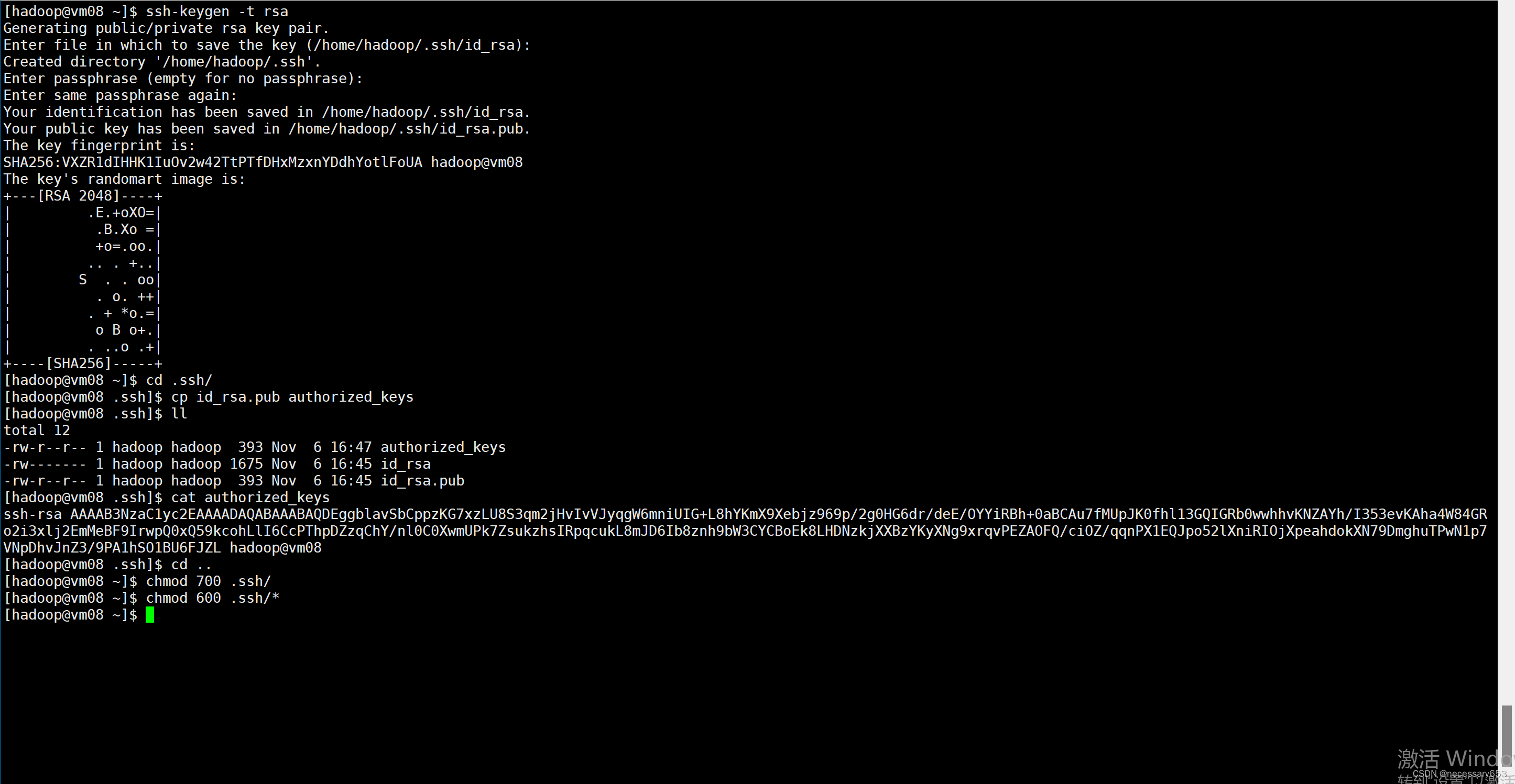
在需要SSH互通的机器上都需要生成密钥。
1.生成密钥
ssh-keygen -t rsa -f D://id_rsa
注意如果要免密登录生成密钥时不要输入密码;
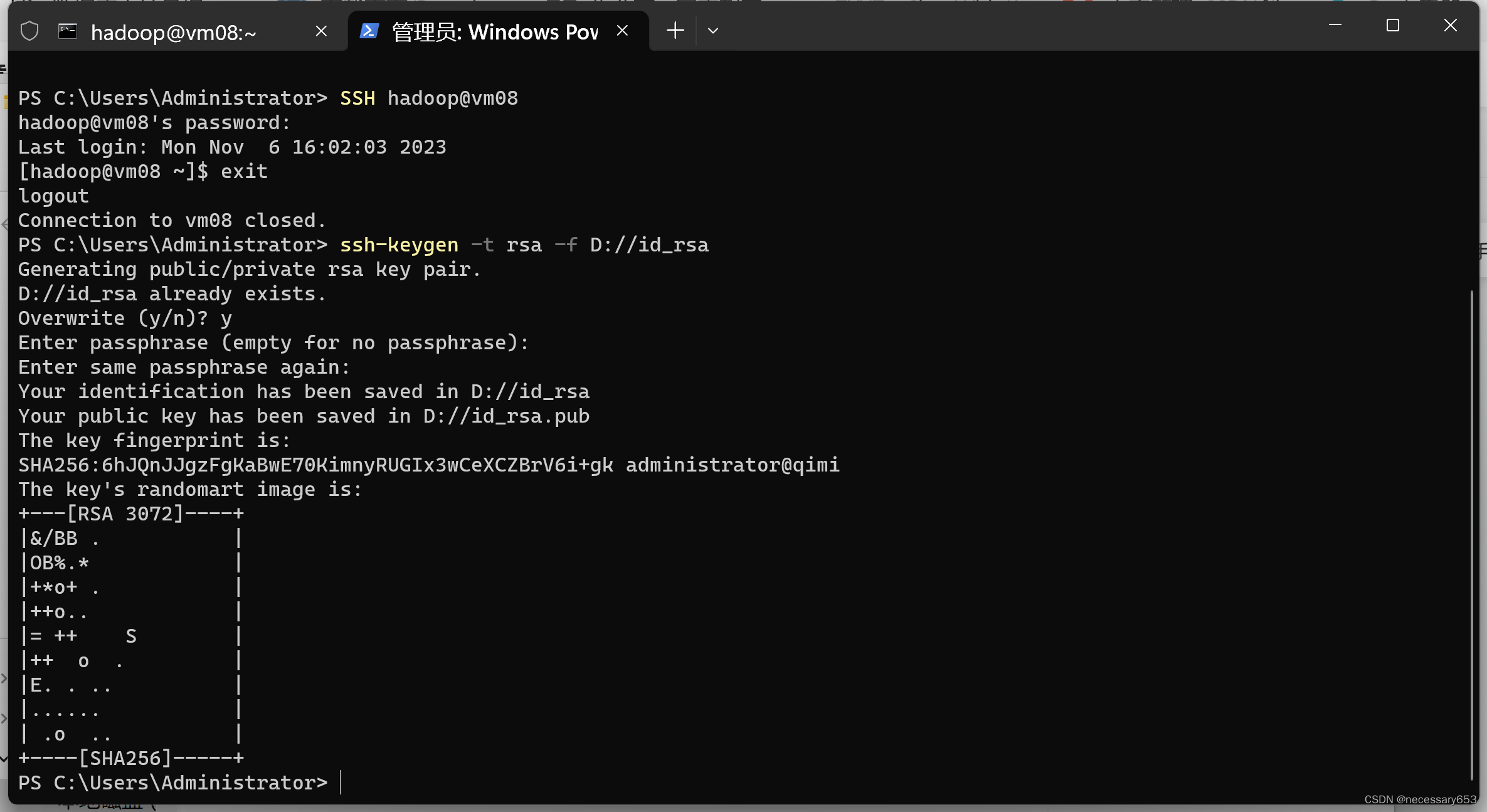
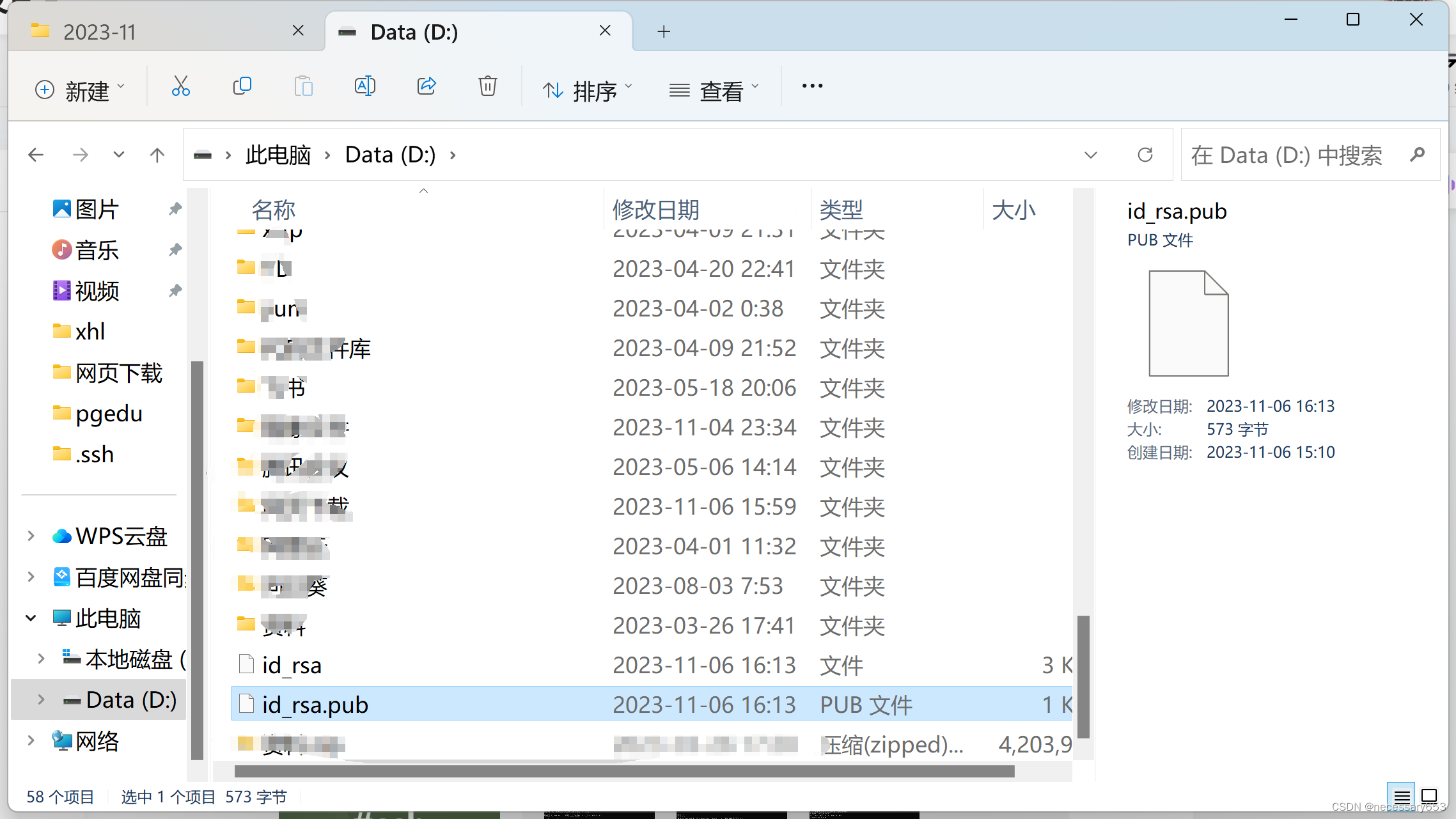
复制 D://id_rsa.pub 文件 到服务器的 C:\Users\<user>\.ssh 文件夹 下的 authorized_keys文件,博主的路径为C:\Users\Administrator\.ssh

修改配置文件sshd_config,C:\Program Files\Git\etc\ssh,电脑不同路劲也会有些区别。
#注释这两行 #Match Group administrators # AuthorizedKeysFile __PROGRAMDATA__/ssh/administrators_authorized_keys##添加这三行 PubkeyAuthentication yes AuthorizedKeysFile .ssh/authorized_keys PasswordAuthentication yes
说明:
-
注释掉
#Match Group administrators和#AuthorizedKeysFile __PROGRAMDATA__/ssh/administrators_authorized_keys两行将禁用针对管理员组的匹配和授权密钥文件。 -
添加
PubkeyAuthentication yes一行将启用公钥身份验证。这意味着客户端连接到 SSH 服务器时将需要使用公钥和私钥进行身份验证,而不是使用密码。 -
添加
AuthorizedKeysFile .ssh/authorized_keys一行将指定验证用户身份时要检查的授权密钥文件。默认情况下,SSH 服务器会在用户的家目录下查找名为.ssh/authorized_keys的文件。 -
修改
PasswordAuthentication yes一行将启用密码身份验证。这意味着客户端连接到 SSH 服务器时,可以使用密码进行身份验证。
增加IP映射
修改文件 C:\Windows\System32\drivers\etc\hosts。
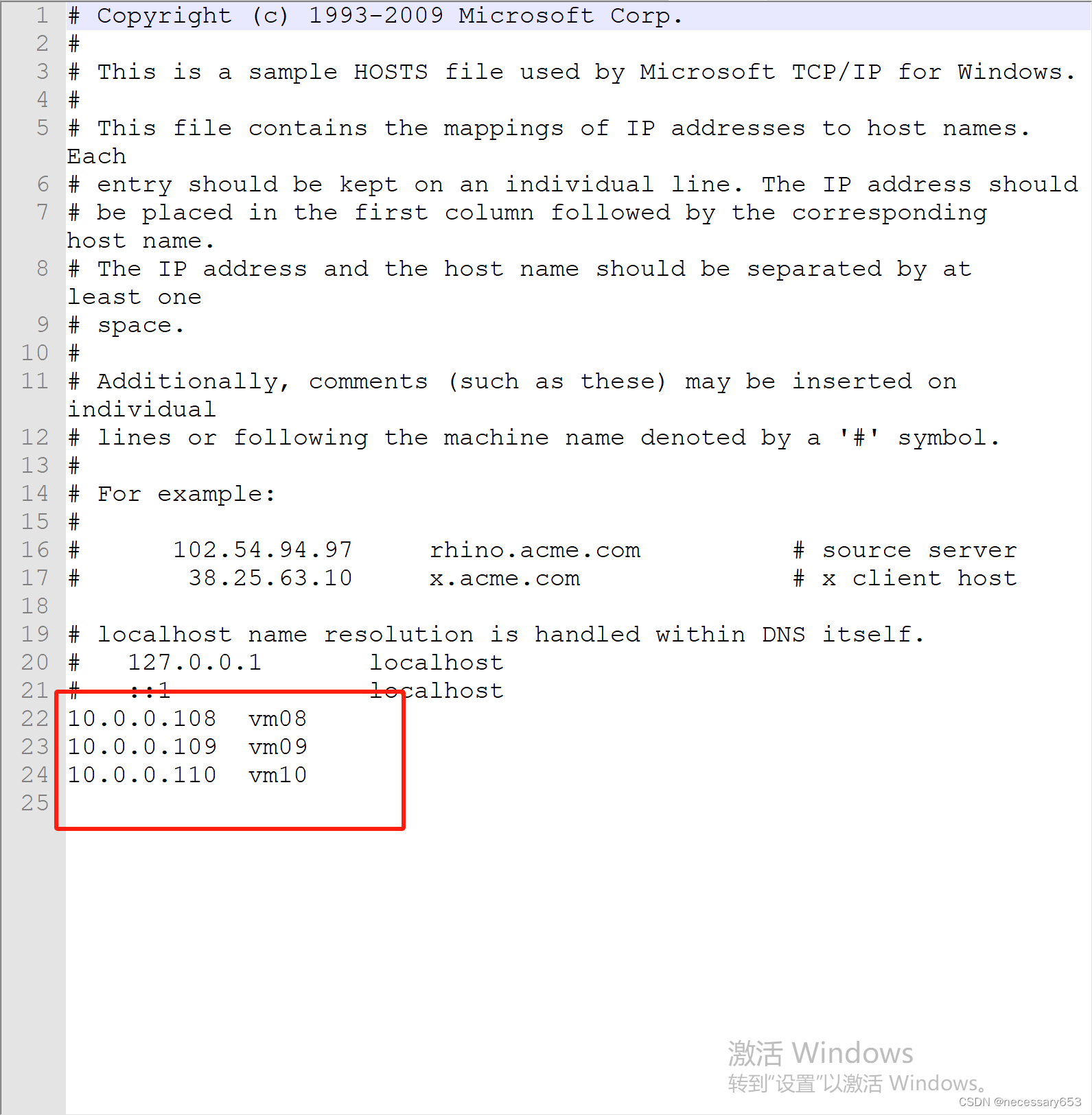
增加你需要的服务器名和IP
格式: IP地址 <空格> hostname
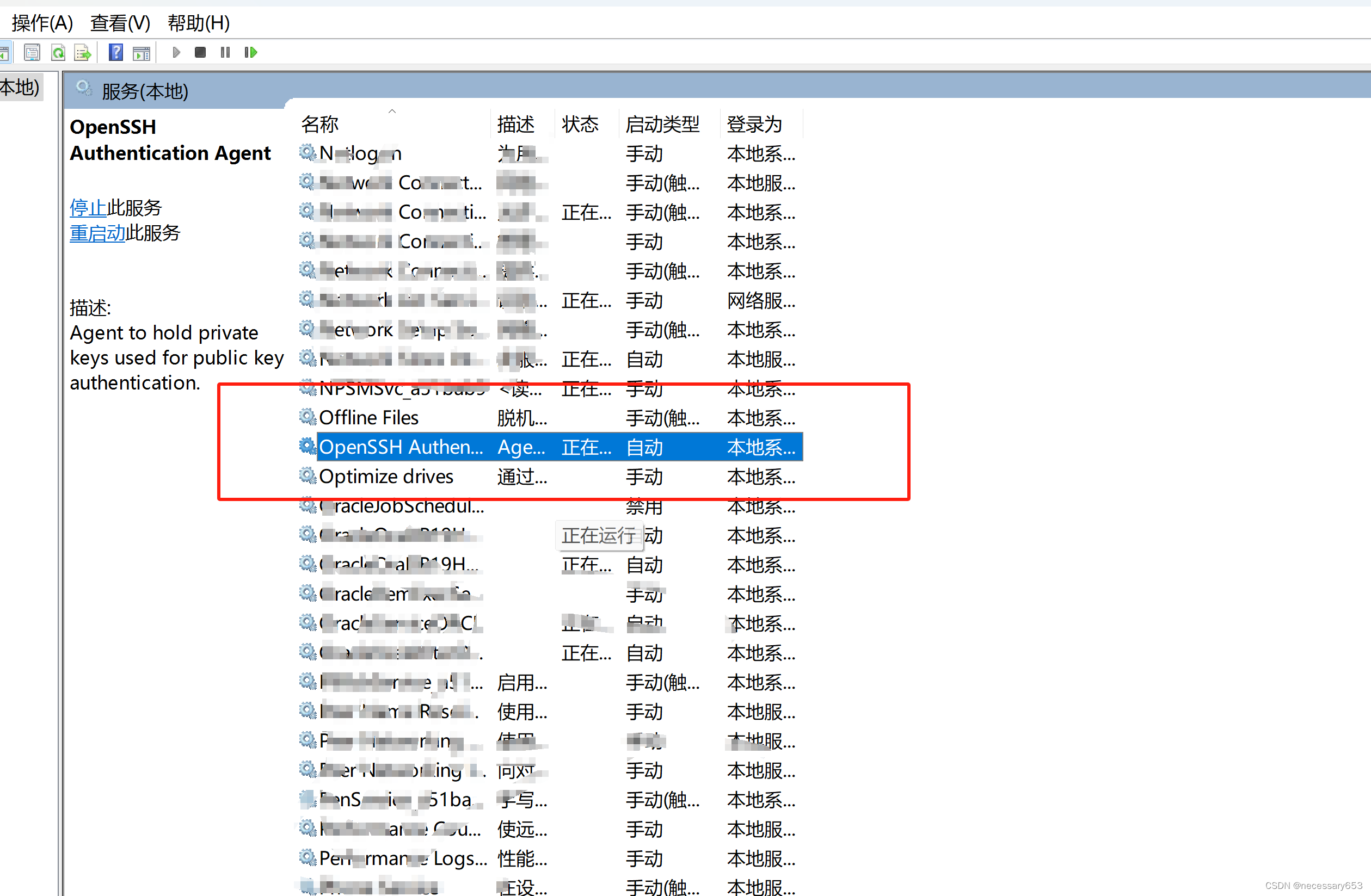
重启服务
使用指令services.msc 打开服务列表,并启动openssh。
linux配置
编辑IP映射文件vim /etc/hostname

格式IP地址 <空格> hostname
windows中查看本地机的IP使用ipconfig 查看本地机的hostname 使用hostname 
在虚拟机中生成密钥
授权
chmod 700 .ssh/
chmod 700 .ssh/*
说明:
第一段指令:chmod 700 .ssh/ 会给整个 .ssh 目录赋予 700 权限,只允许所有者对该目录具有读写执行权限。
第二段指令:chmod 600 .ssh/* 会给 .ssh 目录下的所有文件赋予 600 权限,只允许所有者对该文件具有读写权限。
测试
使用ssh 用户名@hostname 便可以登录任意节点
第一次登录任意节点都需要yes 确认一下。
C:\>ssh hadoop@vm10
The authenticity of host 'vm10 (10.0.0.110)' can't be established.
ED25519 key fingerprint is SHA256:yUxCtH472lSUYgAgJqeOE9lvAiaMBwPO78SogOujnH4.
This host key is known by the following other names/addresses:C:\Users\Administrator/.ssh/known_hosts:1: vm08C:\Users\Administrator/.ssh/known_hosts:4: vm09
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Warning: Permanently added 'vm10' (ED25519) to the list of known hosts.
hadoop@vm10's password:
Last login: Mon Nov 6 10:11:33 2023 from vm08
[hadoop@vm10 ~]$ exit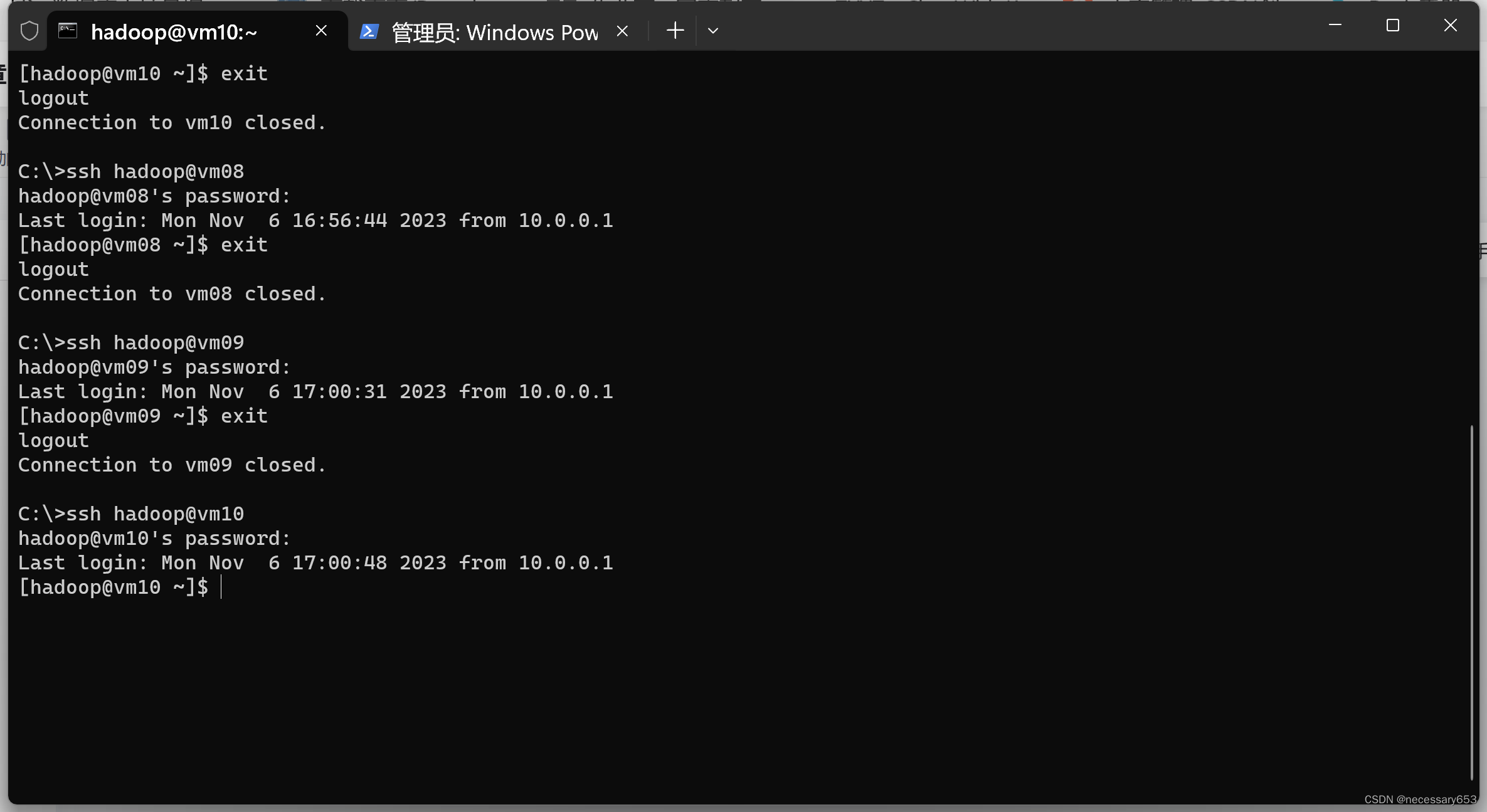
使用方式登录到节点,命令适合对应服务器的操作命令匹配。