做网站需要了解的内容seo怎么收费

AR质量监督 解放双手,解决死角
在当今制造业快速发展的背景下,质量监督成为确保产品高质量和完善的管理制度的关键环节。然而,传统的质量监督方式存在诸多挑战,如人工操作带来的效率低下、查岗不及时、摄像头死角等问题。
为了解决这些问题,安宝特AR的远程协助方案,以其独特的软硬件优势及丰富的现场经验,为工厂质量监督提供了全新的解决方案。

01 解放双手,提高工作效率
- 传统质量监督工具的局限性
在工厂生产线上,操作人员往往需要在进行质量检查的同时操作各种工具和设备。这种情况下,双手的自由度对于提高工作效率和准确性至关重要。
传统的质量监督工具,如平板电脑或手持设备,尽管能够提供丰富的功能,但往往需要操作人员频繁切换工具,这在很大程度上影响了工作效率。
- 安宝特方案的革新之处
安宝特AR为工厂生产线带来了革新,解放了操作人员的双手,使他们无需再分心于手持设备。操作人员只需佩戴轻便的AR眼镜,便能轻松地执行各项任务。
- AR眼镜的功能与优势
安宝特AR硬件不仅轻便,而且功能强大。通过眼镜上的摄像头,它可以实时传输操作人员第一人称视角的画面至调度中心。此外,眼镜的显示屏和扬声器还能辅助现场人员与远端专家进行实时沟通,或迅速获取所需的资料文件。这些功能使得操作人员能将更多精力集中在实际操作上,从而显著提高工作效率和质量监督的准确性。
02 解决摄像头死角问题,确保全方位监控
传统的摄像头监控虽然具备一定的监督能力,但往往存在摄像头死角的问题。工厂环境复杂多变,生产流程长,固定摄像头无法覆盖所有区域,容易导致某些关键位置的监控盲区。这些死角可能成为质量问题的潜在隐患,影响产品的最终质量。
安宝特AR通过集成先进的摄像头和传感器技术,实现全方位的监控。操作人员佩戴AR眼镜后,可以随意移动视角,查看任何位置的细节。同时,AR眼镜还可以加载AI识别技术,自动检测和识别潜在的质量问题,及时向操作人员发出警示。这种全方位的监控能力,有效解决了摄像头死角的问题,确保工厂每一个角落都在质量监督的范围之内。

03 实时远程协助,解决查岗不及时问题
在传统的质量监督体系中,查岗不及时是一个常见的问题。工厂规模大、生产线长,质量监督人员无法实时到达每一个检查点,导致一些问题未能及时发现和解决,严重情况下会导致流水线停工。此外,质量监督人员的经验和技能水平不一,也可能影响质量监督的效果。
安宝特AR的远程协助功能,通过AR眼镜与远程专家实时连接,实现实时的远程指导和支持。操作人员在现场遇到问题时,可以通过AR眼镜与远程专家进行视频通话,专家可以实时查看现场情况,并提供专业的指导和建议。这种实时远程协助的方式,不仅提高了问题解决及时性,还可以充分利用专家的经验和技能,提高整体质量监督效果。
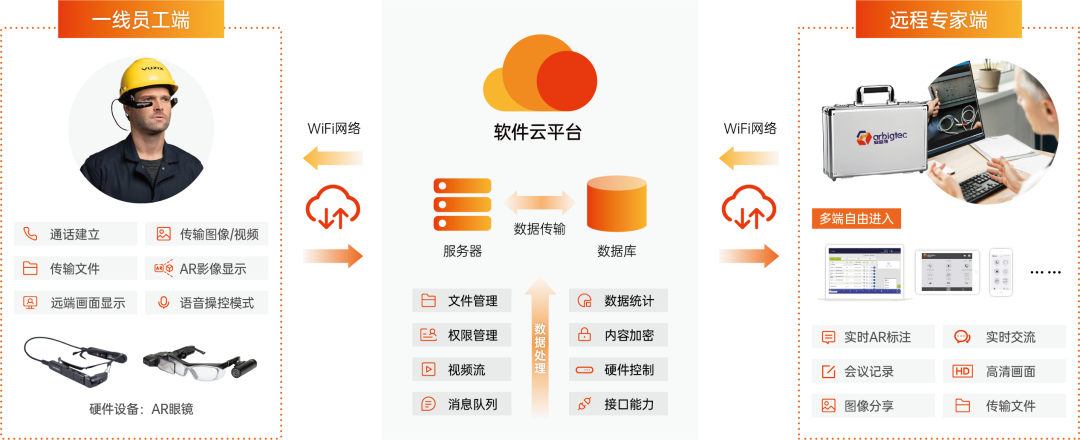
04 安宝特AR的多重优势
- 佩戴轻便舒适、操作简便友好
AR眼镜总重低于190g,主机仅重68g,佩戴轻便舒适,操作人员可以长时间佩戴而不会感到疲劳。
AR眼镜界面友好,操作简单,支持语音控制,大部分操作免提完成,操作人员无需复杂培训即可上手使用。
- 高效的视频数据处理
AR眼镜集成高效的数据处理能力,支持低带宽环境下1080p视频的稳定传输,最高支持4k清晰度,提供清晰的现场画面。
- 与现有系统的兼容性
安宝特AR采用Android 11 操作系统,提供完整SDK,易于二次开发,实现与现有数据管理系统的集成,进一步提高质量监督的效率和效果。
在智能制造的时代,AR技术正在为工厂质量监督带来全新的变革。安宝特AR的远程协助方案,以其轻便易用、性能稳定,贴合现场实际需求等优势,为工厂提供了高效、精准的质量监督解决方案。
让我们共同期待,AR技术能够在工厂质量监督中的广泛应用,推动工业向数字化转型迈出坚实的步伐。如果您对更多行业应用感兴趣,欢迎关注我们的公众号或联系销售工程师,了解更多动态和免费定制方案的机会。期待您的关注和参与!
安宝特 | AR企业级解决方案供应商
安宝特科技有限公司是一家领先的AR解决方案供应商,由原虹科数字化+AR业务孵化的独立公司主体,致力于开发并提供创新解决方案,帮您克服各种挑战!围绕AR工业远程协助、AR数字化工作流程、AR+AI识别、私有化部署、客户定制等提供专业可靠的解决方案,并广获行业客户如华为、中国电信、中钢集团、台达、东风日产、巴斯夫、施乐辉、复旦大学、西安交通大学等的信任与好评。
作为专业的工业级AR解决方案提供商,我们可以帮助您:
-
远程的培训指导员工,提高效率降低成本
-
专业的AI算法模型,多场景智能识别,提高工作质量
-
数字化的工作流程帮助员工标准化作业,促进数字化转型
-
软件商城海量应用支持不同需求,私有化部署保护信息安全
-
定制化方案与专业技术服务,保证目标达成
一旦您开始应用安宝特AR解决方案,我们的团队将为您提供一对一的方案支持,保证您的项目高效、安全运转。