帮别人做买家秀的网站北京的外包公司有哪些
整理一个之前的老项目问题,发现日志一直打印不出来,本地启动发现了第一个问题日志如下:

此处可发现,jar包冲突问题,去掉冲突的jar包即可,此处不做过多赘述。
然后发现了重新启动项目,发现jar包冲突的问题小时了。但是日志却没有任何输出。郁闷。
然后开始打断点,看到logger的级别是OFF,但是我设置的明明是DEBUG,这是怎么回事?
然后开始翻看源码,看他怎么初始化的,最后找到问题,
在类org.apache.log4j.LogManager的静态代码块中。有如下代码
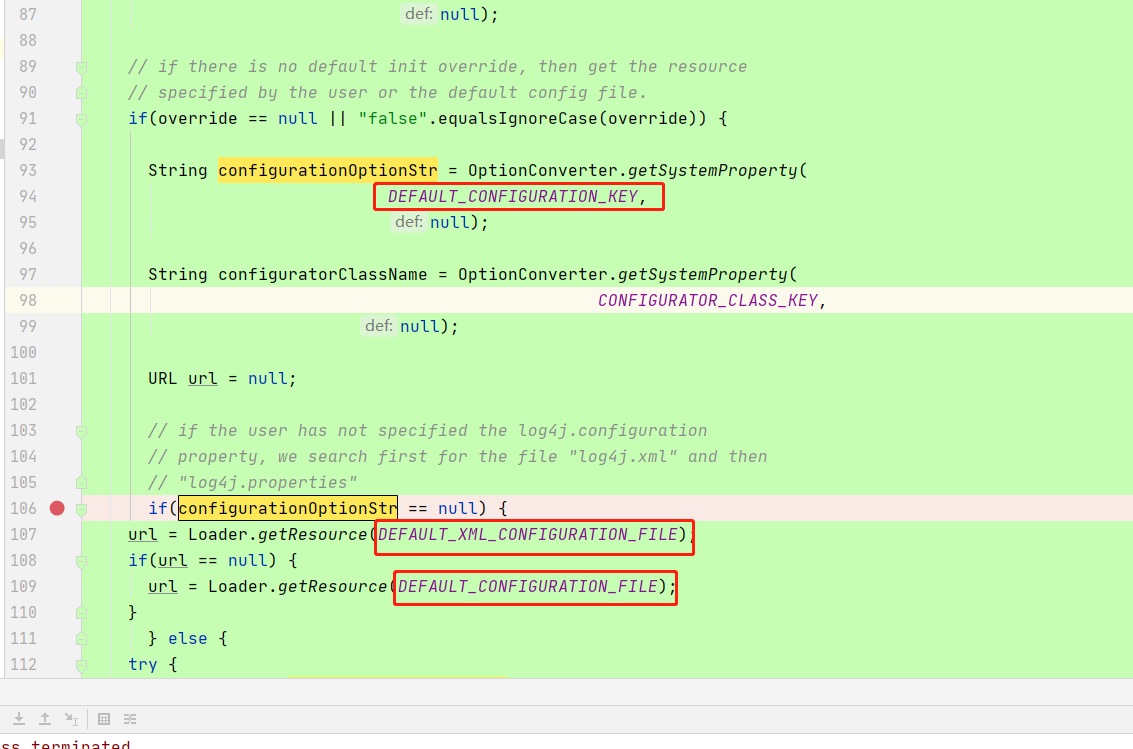
标红处是配置文件的地址,有优先级,
1、DEFAULT_CONFIGURATION_KEY="log4j.configuration"
2、DEFAULT_XML_CONFIGURATION_FILE = "log4j.xml"
3、DEFAULT_CONFIGURATION_FILE = "log4j.properties";
我是用的是log4j.properties,
我的项目中引用了一个jar包。kettle5-log4j-plugin-6.1.0.1-196.jar
这个jar保利有个log4j的配置文件log4j.xml,所以我的配置文件就被跳过了。
原来如此。